Σημείωμα
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να εισέλθετε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Σε αυτό το άρθρο, θα μάθετε πώς μπορείτε να εκτελέσετε διερευνητική ανάλυση δεδομένων χρησιμοποιώντας Τα Ανοιχτά σύνολα δεδομένων Azure και το Apache Spark. Αυτό το άρθρο αναλύει το σύνολο δεδομένων ταξί στη Νέα Υόρκη. Τα δεδομένα είναι διαθέσιμα μέσω του Azure Open Datasets. Αυτό το υποσύνολο του συνόλου δεδομένων περιέχει πληροφορίες σχετικά με κίτρινες διαδρομές ταξί: πληροφορίες σχετικά με κάθε διαδρομή, την ώρα έναρξης και λήξης και τοποθεσίες, το κόστος και άλλα ενδιαφέροντα χαρακτηριστικά.
Σε αυτό το άρθρο, θα κάνετε τα εξής:
- Λήψη και προετοιμασία δεδομένων
- Ανάλυση δεδομένων
- Απεικόνιση δεδομένων
Προαπαιτούμενα στοιχεία
Λάβετε μια συνδρομή Microsoft Fabric. Εναλλακτικά, εγγραφείτε για μια δωρεάν δοκιμαστική έκδοση του Microsoft Fabric.
Εισέλθετε στο Microsoft Fabric.
Μεταβείτε στο Fabric χρησιμοποιώντας την εναλλαγή εμπειριών στην κάτω αριστερή πλευρά της αρχικής σελίδας σας.
Λήψη και προετοιμασία των δεδομένων
Για να ξεκινήσετε, κάντε λήψη του συνόλου δεδομένων ταξί New York City (NYC) και προετοιμάστε τα δεδομένα.
Δημιουργήστε ένα σημειωματάριο χρησιμοποιώντας το PySpark. Για οδηγίες, ανατρέξτε στο θέμα Δημιουργία σημειωματάριου.
Σημείωμα
Εξαιτίας του πυρήνα PySpark, δεν χρειάζεται να δημιουργήσετε οποιαδήποτε περιβάλλοντα ρητά. Το περιβάλλον Spark δημιουργείται αυτόματα για εσάς όταν εκτελείτε το πρώτο κελί κώδικα.
Σε αυτό το άρθρο, χρησιμοποιείτε πολλές διαφορετικές βιβλιοθήκες για να απεικονίσετε το σύνολο δεδομένων. Για να κάνετε αυτή την ανάλυση, εισαγάγετε τις παρακάτω βιβλιοθήκες:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdΕπειδή τα ανεπεξέργαστα δεδομένα είναι σε μορφή Parquet, μπορείτε να χρησιμοποιήσετε το περιβάλλον Spark για να μεταφέρετε το αρχείο στη μνήμη ως DataFrame απευθείας. Χρησιμοποιήστε το API Ανοικτών συνόλων δεδομένων για να ανακτήσετε τα δεδομένα και να δημιουργήσετε ένα Spark DataFrame. Για να συναγάγετε τους τύπους δεδομένων και το σχήμα, χρησιμοποιήστε το σχήμα Spark DataFrame στις ιδιότητες ανάγνωσης .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Μετά την ανάγνωση των δεδομένων, κάντε κάποιο αρχικό φιλτράρισμα για να καθαρίσετε το σύνολο δεδομένων. Ενδέχεται να καταργήσετε περιττές στήλες και να προσθέσετε στήλες που εξάγουν σημαντικές πληροφορίες. Επιπλέον, μπορείτε να φιλτράρετε τις ανωμαλίες εντός του συνόλου δεδομένων.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Ανάλυση δεδομένων
Ως αναλυτής δεδομένων, έχετε ένα ευρύ φάσμα διαθέσιμων εργαλείων για να σας βοηθήσει να εξαγάγετε πληροφορίες από τα δεδομένα. Σε αυτό το μέρος του άρθρου, μάθετε σχετικά με μερικά χρήσιμα εργαλεία που είναι διαθέσιμα στα σημειωματάρια Microsoft Fabric. Σε αυτήν την ανάλυση, θέλετε να κατανοήσετε τους παράγοντες που αποδίδουν υψηλότερες συμβουλές ταξί για την επιλεγμένη περίοδο.
Apache Spark SQL Magic
Πρώτα, κάντε διερευνητική ανάλυση δεδομένων χρησιμοποιώντας το Apache Spark SQL και μαγικές εντολές με το σημειωματάριο Microsoft Fabric. Αφού έχετε το ερώτημα, απεικονίστε τα αποτελέσματα χρησιμοποιώντας την ενσωματωμένη chart options δυνατότητα.
Στο σημειωματάριο, δημιουργήστε ένα νέο κελί και αντιγράψτε τον ακόλουθο κώδικα. Χρησιμοποιώντας αυτό το ερώτημα, μπορείτε να κατανοήσετε πώς αλλάζουν τα μέσα ποσά συμβουλών κατά την περίοδο που επιλέγετε. Αυτό το ερώτημα σάς βοηθά επίσης να αναγνωρίσετε άλλες χρήσιμες πληροφορίες, όπως το ελάχιστο/μέγιστο ποσό συμβουλής ανά ημέρα και το μέσο ποσό ναύλου.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCΑφού ολοκληρωθεί η εκτέλεση του ερωτήματός σας, μπορείτε να απεικονίσετε τα αποτελέσματα μεταβαίνοντας στην προβολή γραφήματος. Αυτό το παράδειγμα δημιουργεί ένα γράφημα γραμμών καθορίζοντας το
day_of_monthπεδίο ως κλειδί καιavgTipAmountως τιμή. Αφού κάνετε τις επιλογές, επιλέξτε Εφαρμογή για να ανανεώσετε το γράφημά σας.
Απεικόνιση δεδομένων
Εκτός από τις ενσωματωμένες επιλογές γραφήματος σημειωματάριου, μπορείτε να χρησιμοποιήσετε δημοφιλείς βιβλιοθήκες ανοιχτού κώδικα για να δημιουργήσετε τις δικές σας απεικονίσεις. Στα παρακάτω παραδείγματα, χρησιμοποιήστε τις βιβλιοθήκες Seaborn και Matplotlib, οι οποίες χρησιμοποιούνται συχνά ως βιβλιοθήκες Python για την απεικόνιση δεδομένων.
Για να γίνει η ανάπτυξη ευκολότερη και λιγότερο δαπανηρή, κάντε μείωση του συνόλου δεδομένων. Χρησιμοποιήστε την ενσωματωμένη δυνατότητα δειγματοληψίας Apache Spark. Επιπλέον, οι στήλες Seaborn και Matplotlib απαιτούν έναν πίνακα Pandas DataFrame ή NumPy. Για να λάβετε ένα Pandas DataFrame, χρησιμοποιήστε την
toPandas()εντολή για να μετατρέψετε το DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Μπορείτε να κατανοήσετε την κατανομή των συμβουλών στο σύνολο δεδομένων. Χρησιμοποιήστε το Matplotlib για να δημιουργήσετε ένα ιστόγραμμα που εμφανίζει την κατανομή της ποσότητας και του πλήθους των συμβουλών. Με βάση την κατανομή, μπορείτε να δείτε ότι οι συμβουλές αλλοιώνονται προς ποσά μικρότερα ή ίσα με 10 $.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()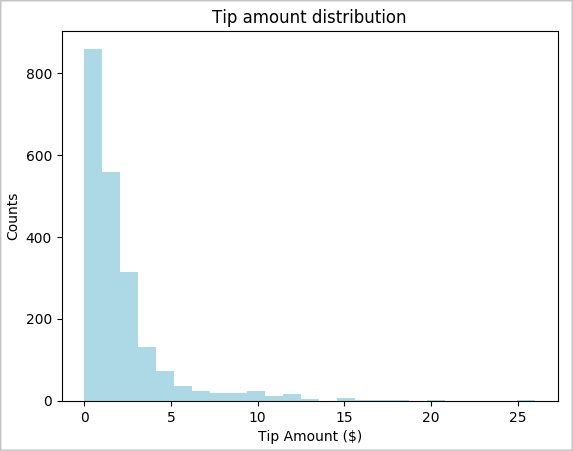
Στη συνέχεια, δοκιμάστε να κατανοήσετε τη σχέση μεταξύ των συμβουλών για ένα συγκεκριμένο ταξίδι και της ημέρας της εβδομάδας. Χρησιμοποιήστε τη seaborn για να δημιουργήσετε μια σχεδίαση πλαισίου που συνοψίζει τις τάσεις για κάθε ημέρα της εβδομάδας.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()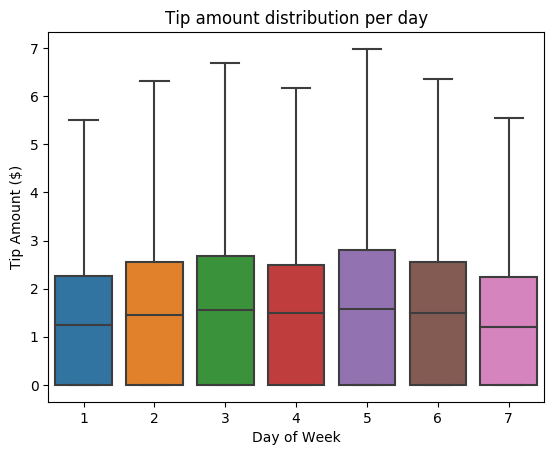
Μια άλλη υπόθεση μπορεί να είναι ότι υπάρχει θετική σχέση μεταξύ του αριθμού των επιβατών και του συνολικού ποσού συμβουλής ταξί. Για να επαληθεύσετε αυτήν τη σχέση, εκτελέστε τον παρακάτω κώδικα για να δημιουργήσετε ένα γράφημα πλαισίου που απεικονίζει τη διανομή συμβουλών για κάθε πλήθος επιβατών.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()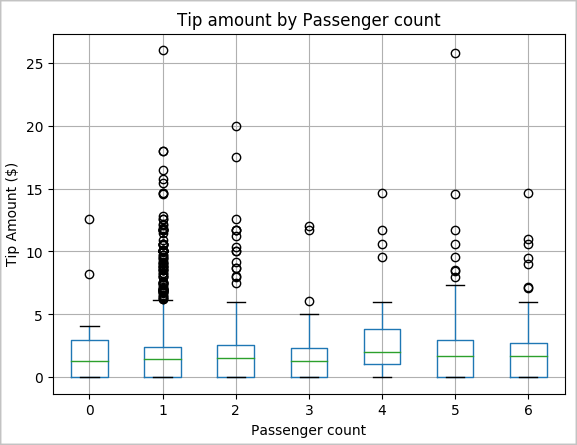
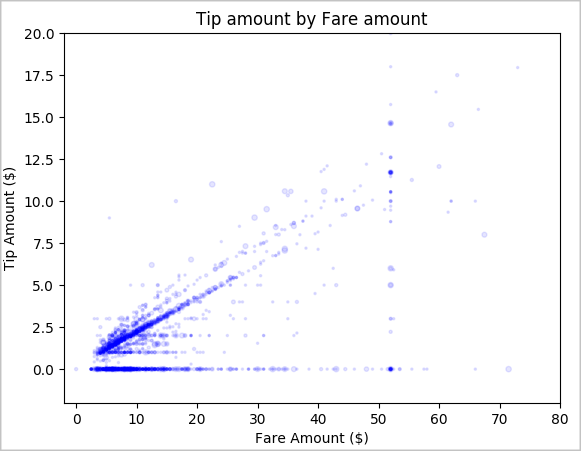
Τέλος, εξερευνήστε τη σχέση μεταξύ του ποσού ναύλου και του ποσού φιλοδωρήματος. Με βάση τα αποτελέσματα, μπορείτε να δείτε ότι υπάρχουν πολλές παρατηρήσεις στις οποίες οι χρήστες δεν δίνουν φιλοδώρημα. Ωστόσο, υπάρχει μια θετική σχέση μεταξύ του συνολικού ναύλου και των ποσών συμβουλών.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()