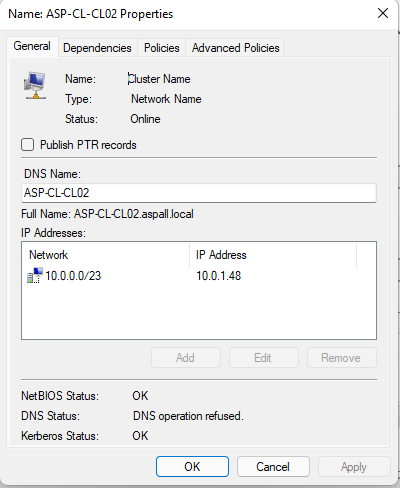
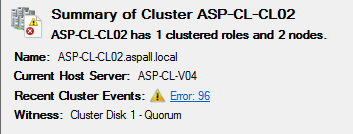
So our other Cluster was due for the problem as well, so I waited until it started throwing out event ID 1257 again, then just deleted the DNS record for that clusters main CNO. Similar to before, once it tried again (it tries every 15 mins once it fails) it registered in DNS, but now the "DHCP" role owns it. It's almost like I'm having the exact opposite issue as you, where my main CNO DNS object is now being 'owned' by the roles it maintains, rather than by itself. So far, no errors have ever happened when attempting to register the roles DNS, but it might be that I'm not waiting long enough after the main CNO quits being able to update itself.
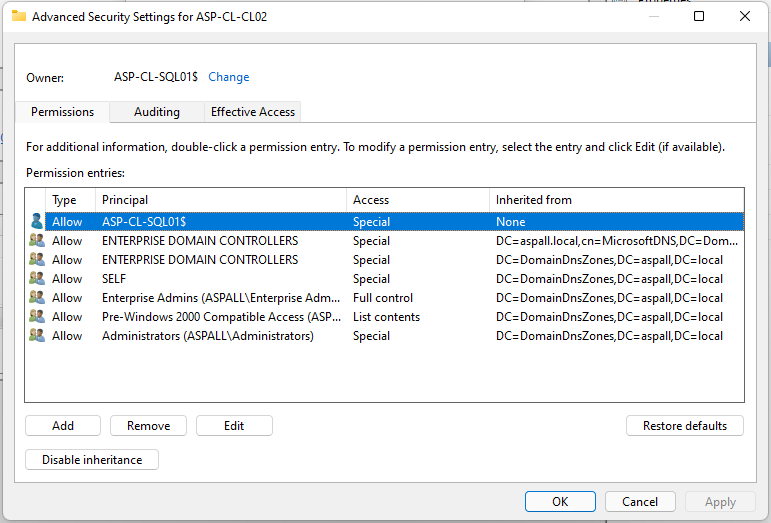
If I delete the DNS record, and then stop/start the 'Name' role on the cluster itself, it re-registers the DNS record under it's own name properly. The next time the password is updated is when it switches to one of the roles.
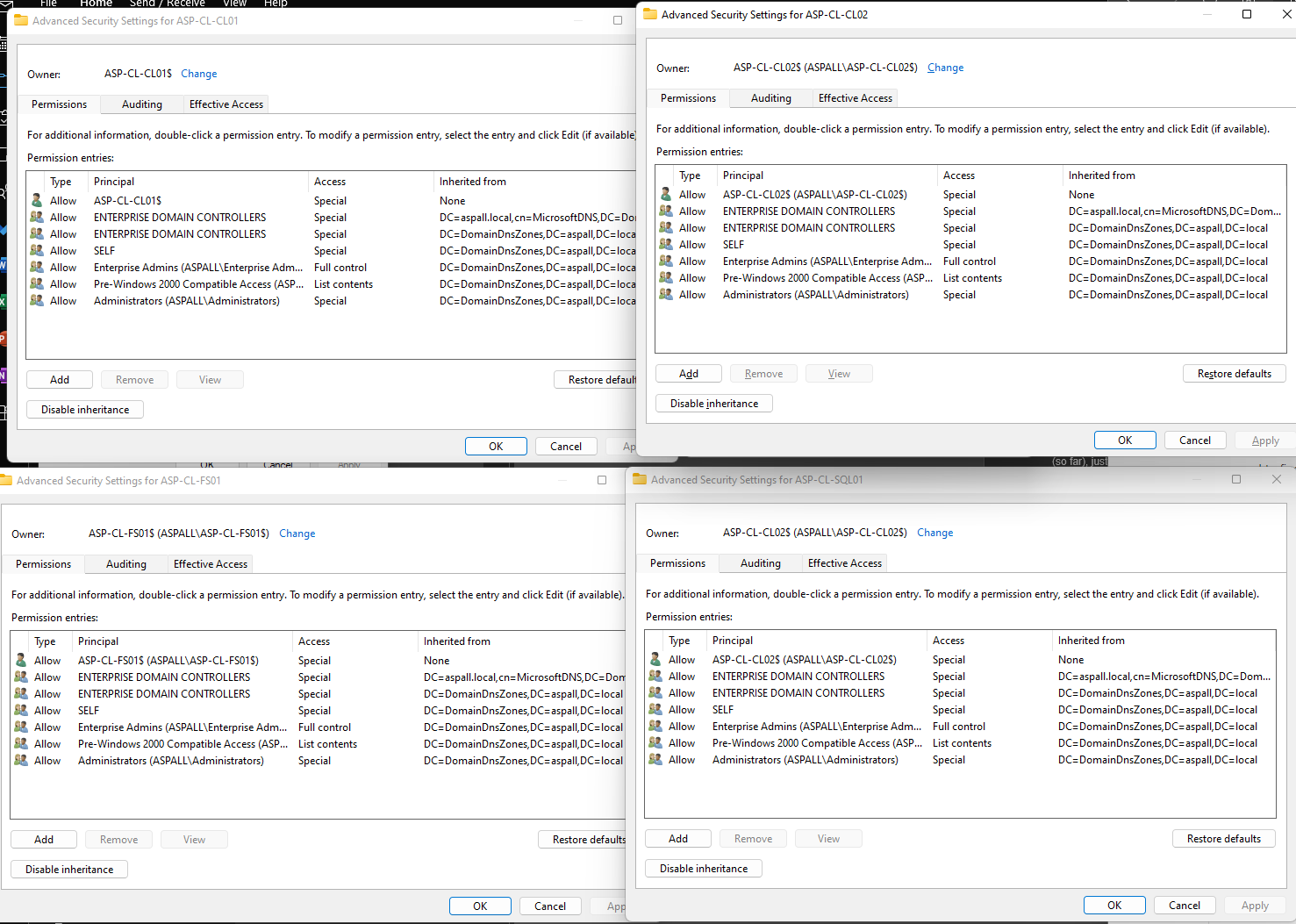
I'm still leaning towards the thought I had when I originally posted, which was that my cluster basically 'forgets' how to login under it's own name after it changes the password on the CNO, but somehow it's falling over to using one of the roles credentials. I suppose I can just add both the roles and the main CNO object as being able to write to the DNS record. This will probably make it work, however I would still consider this a 'workaround' to a bug that was introduced within the last 6 months or so.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJE%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJD%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMA%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESC%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EY%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAT%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJB%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPS%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHG%3C/text%3E%3C/svg%3E)