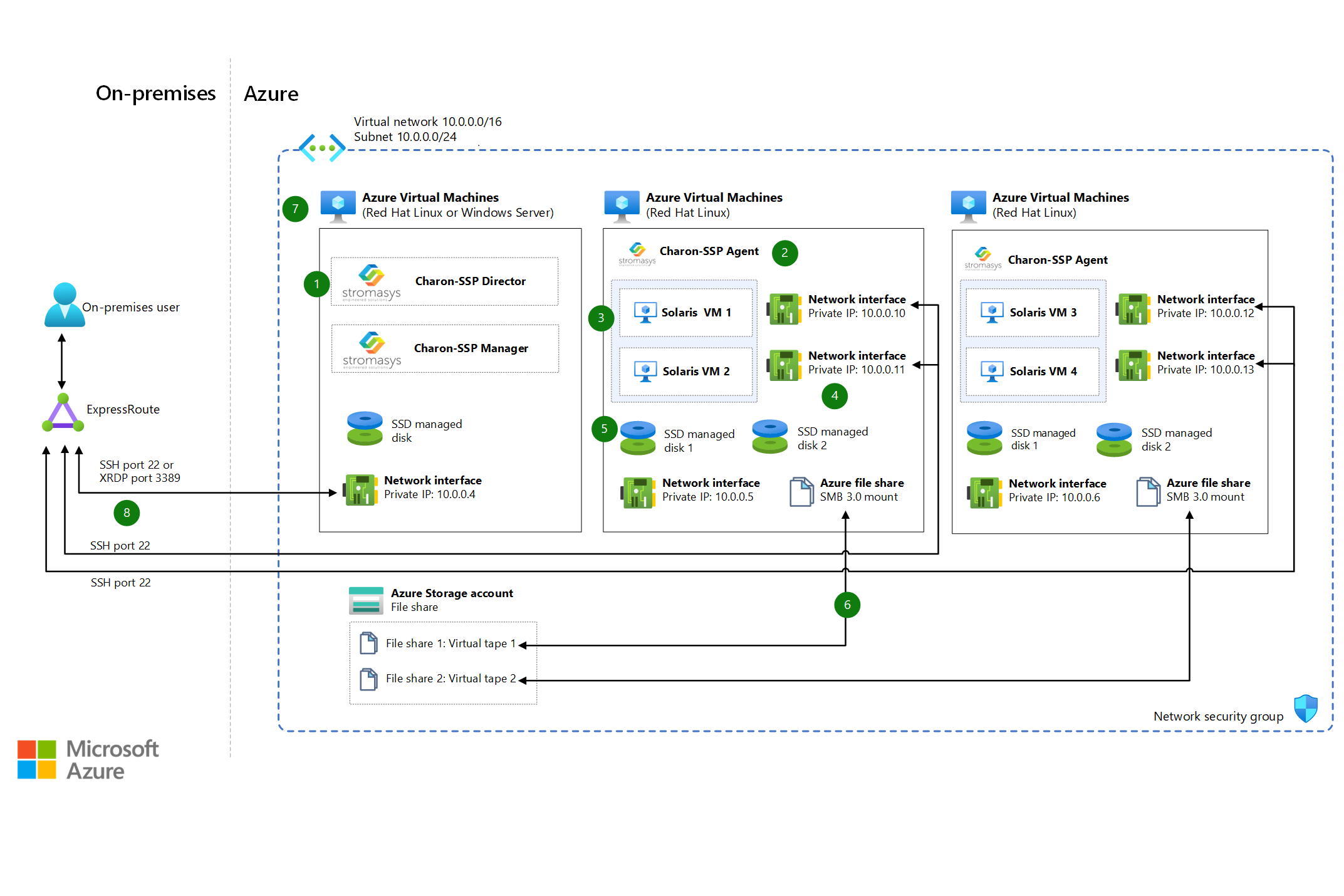
Stromasys Charon-SSP Solaris emulator on Azure VMs
Charon-SSP cross-platform hypervisor emulates legacy Sun SPARC systems on industry standard x86-64 computer systems and VMs.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Mainframe and midrange hardware is composed of a family of systems from various vendors (all with a history and goal of high performance, high throughput, and sometimes high availability). These systems were often scale-up and monolithic, meaning they were a single, large frame with multiple processing units, shared memory, and shared storage.
On the application side, programs were often written in one of two flavors: either transactional or batch. In both cases, there were several programming languages that were used, including COBOL, PL/I, Natural, Fortran, REXX, and so on. Despite the age and complexity of these systems, there are many migration pathways to Azure.
On the data side, data is usually stored in files and in databases. Mainframe and midrange databases commonly come in various structures, such as relational, hierarchical, and network, among others. There are different types of file organizational systems, where some of them can be indexed and can act as a key-value stores. Further, data encoding in mainframes can be different from the encoding that's typically handled in non-mainframe systems. Therefore, data migrations should be handled with upfront planning. There are many options for migrating to the Azure data platform.

In many cases, mainframe, midrange, and other server-based workloads can be replicated in Azure with little to no loss of functionality. Sometimes users don't notice changes in their underlying systems. In other situations, there are options for refactoring and re-engineering the legacy solution into an architecture that is in alignment with the cloud. This is done while still maintaining the same or similar functionality. The architectures in this content set (plus the white papers and other resources provided later in this article) help guide you through this process.
In our mainframe architectures, we use the following terms.
Mainframes were designed as scale-up servers to run high-volume online transactions and batch processing in the late 1950s. As such, mainframes have software for online transaction forms (sometimes called green screens) and high-performance I/O systems, for processing the batch runs. Mainframes have a reputation for high reliability and availability, in addition to their ability to run online and batch jobs.
Part of demystifying mainframes involves decoding various overlapping terms. For example, central storage, real memory, real storage, and main storage all refer to storage that is attached directly to the mainframe processor. Mainframe hardware includes processors and many other devices, such as direct-access storage devices (DASDs), magnetic tape drives, and several types of user consoles. Tapes and DASDs are used for system functions and by user programs.
Types of physical storage:
The measurement of millions of instructions per second (MIPS) provides a constant value of the number of cycles per second, for a given machine. MIPS are used to measure the overall compute power of a mainframe. Mainframe vendors charge customers, based on MIPS usage. Customers can increase mainframe capacity to meet specific requirements. IBM maintains a processor capacity index, which shows the relative capacity across different mainframes.
The following table shows typical MIPS thresholds across small, medium, and large enterprise organizations (SORGs, MORGs, and LORGs).
| Customer size | Typical MIPS usage |
|---|---|
| SORG | Less than 500 MIPS |
| MORG | 500 MIPS to 5,000 MIPS |
| LORG | More than 5,000 MIPS |
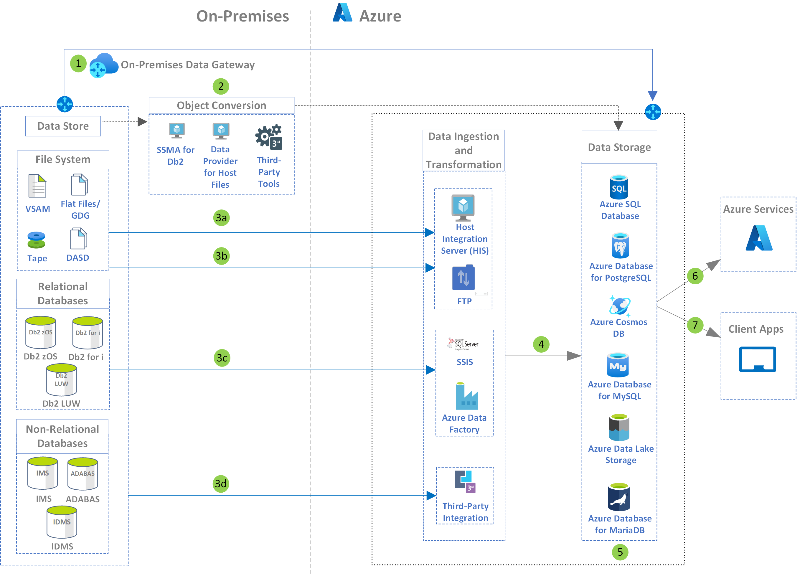
Mainframe data is stored and organized in various ways, from relational and hierarchical databases to high throughput file systems. Some of the common data systems are z/OS Db2 for relational data and IMS DB for hierarchical data. For high throughput file storage, you might see VSAM (IBM Virtual Storage Access Method). The following table provides a mapping of some of the more common mainframe data systems, and their possible migration targets into Azure.
| Data source | Target platform in Azure |
|---|---|
| z/OS Db2 & Db2 LUW | Azure SQL DB, SQL Server on Azure VMs, Db2 LUW on Azure VMs, Oracle on Azure VMs, Azure Database for PostgreSQL |
| IMS DB | Azure SQL DB, SQL Server on Azure VMs, Db2 LUW on Azure VMs, Oracle on Azure VMs, Azure Cosmos DB |
| Virtual Storage Access Method (VSAM), Indexed Sequential Access Method (ISAM), other flat files | Azure SQL DB, SQL Server on Azure VMs, Db2 LUW on Azure VMs, Oracle on Azure VMs, Azure Cosmos DB |
| Generation Date Groups (GDGs) | Files on Azure using extensions in the naming conventions to provide similar functionality to GDGs |
Midrange systems and midrange computers are loosely defined terms for a computer system that is more powerful than a general-purpose personal computer, but less powerful than a full-size mainframe computer. In most instances, a midrange computer is employed as a network server, when there are a small to medium number of client systems. The computers generally have multiple processors, a large amount of random access memory (RAM), and large hard drives. Additionally, they usually contain hardware that allows for advanced networking, and ports for connecting to more business-oriented peripherals (such as large-scale data storage devices).
Common systems in this category include AS/400 and the IBM i and p series. Unisys also has a collection of midrange systems.
The Unix operating system was one of the first enterprise-grade operating systems. Unix is the base operating system for Ubuntu, Solaris, and operating systems that follow POSIX standards. Unix was developed in the 1970s by Ken Thompson, Dennis Ritchie, and others at AT&T Laboratories. It was originally meant for programmers who are developing software, rather than non-programmers. It was distributed to government organizations and academic institutions, both of which led Unix to being ported to a wider variety of variations and forks, with different specialized functions. Unix and its variants (such as AIX, HP-UX, and Tru64) are commonly found running on legacy systems, such as IBM mainframes, AS/400 systems, Sun Sparc, and DEC hardware-based systems.
Other legacy systems include the family of systems from Digital Equipment Corporation (DEC), such as the DEC VAX, DEC Alpha, and DEC PDP. The DEC systems initially ran the VAX VMS operating system, then eventually they moved to Unix variants, such as Tru64. Other systems include ones that are based on the PA-RISC architecture, such as the HP-3000 and HP-9000 systems.
Midrange data is stored and organized in variety of ways, from relational and hierarchical databases, to high throughput file systems. Some of the common data systems are Db2 for i (for relational data), and IMS DB for hierarchical data. The following table provides a mapping of some of the more common mainframe data systems and the possible migration targets into Azure.
| Data source | Target platform in Azure |
|---|---|
| Db2 for i | Azure SQL DB, SQL Server on Azure VMs, Azure Database for PostgreSQL, Db2 LUW on Azure VMs, Oracle on Azure VMs |
| IMS DB | Azure SQL DB, SQL Server on Azure VMs, Db2 LUW on Azure VMs, Oracle on Azure VMs, Azure Cosmos DB |
Consider the following details about endianness:
The following figure visually shows you the difference between big endian and little endian.

Often referred to as a lift-and-shift migration, this option doesn't require code changes. You can use it to quickly migrate your existing applications to Azure. Each application is migrated as is, to reap the benefits of the cloud (without the risk and cost that are associated with code changes).
Stromasys Charon-SSP Solaris emulator on Azure VMs
Charon-SSP cross-platform hypervisor emulates legacy Sun SPARC systems on industry standard x86-64 computer systems and VMs.
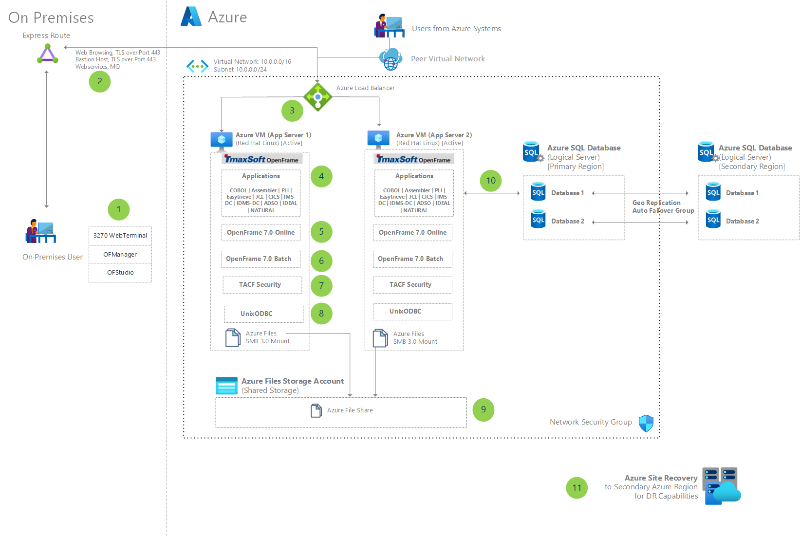
Migrate IBM mainframe apps to Azure with TmaxSoft OpenFrame
Migrate IBM zSeries mainframe applications to Azure. Use a no-code approach that TmaxSoft OpenFrame offers for this lift and shift operation.
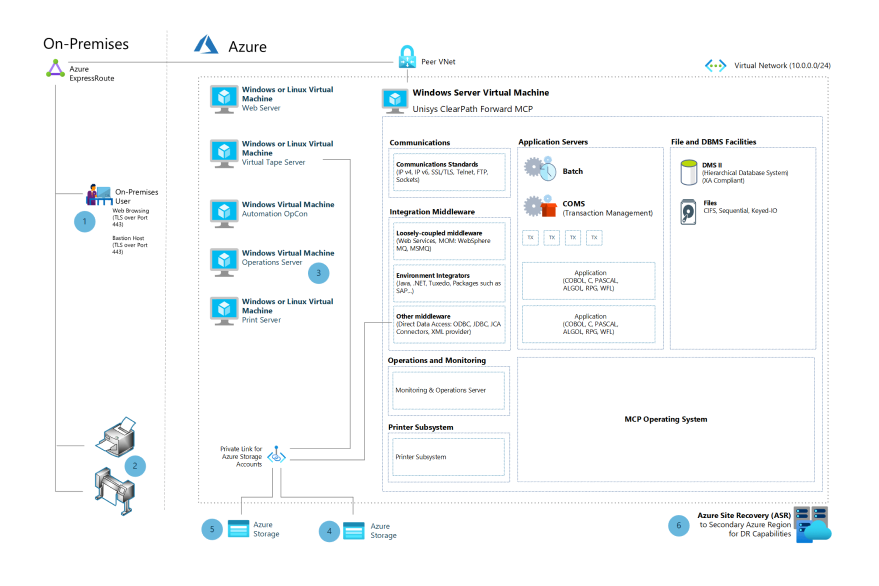
Unisys ClearPath Forward mainframe rehost to Azure using Unisys virtualization
The architecture described in this article shows how to use virtualization technologies from Microsoft partner Unisys with a legacy Unisys CPF Libra mainframe.
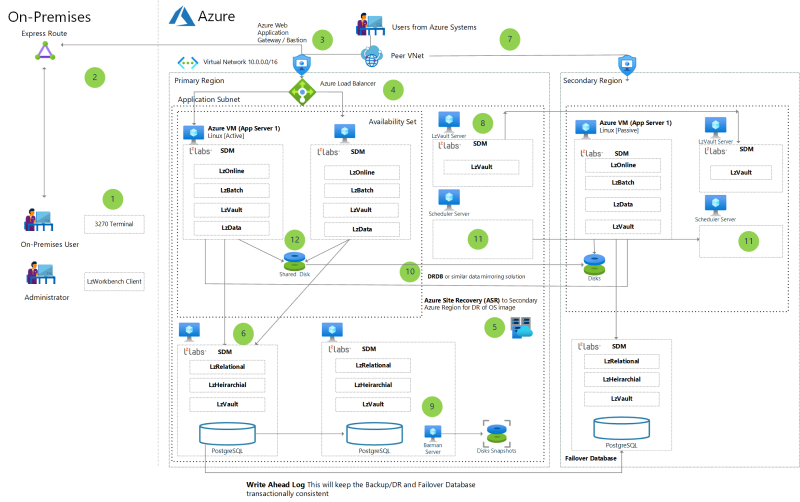
Using LzLabs Software Defined Mainframe (SDM) in an Azure VM deployment
An approach for rehosting mainframe legacy applications in Azure using the LzLabs Software Defined Mainframe platform.
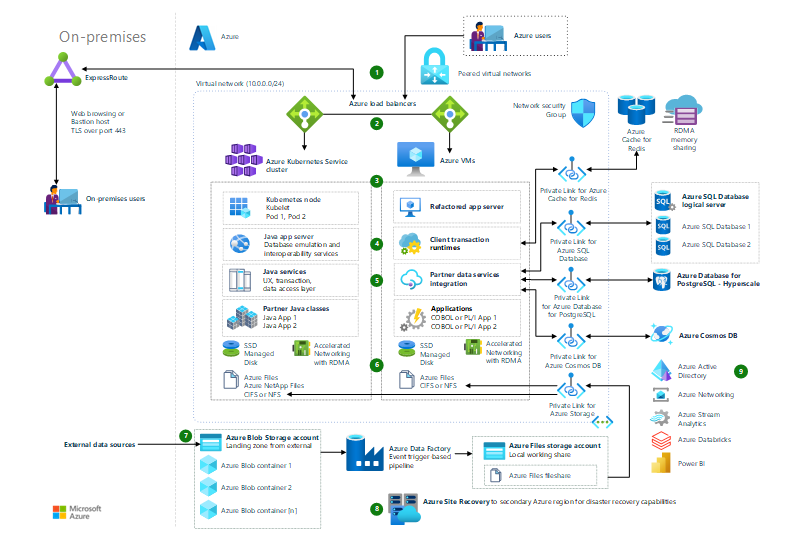
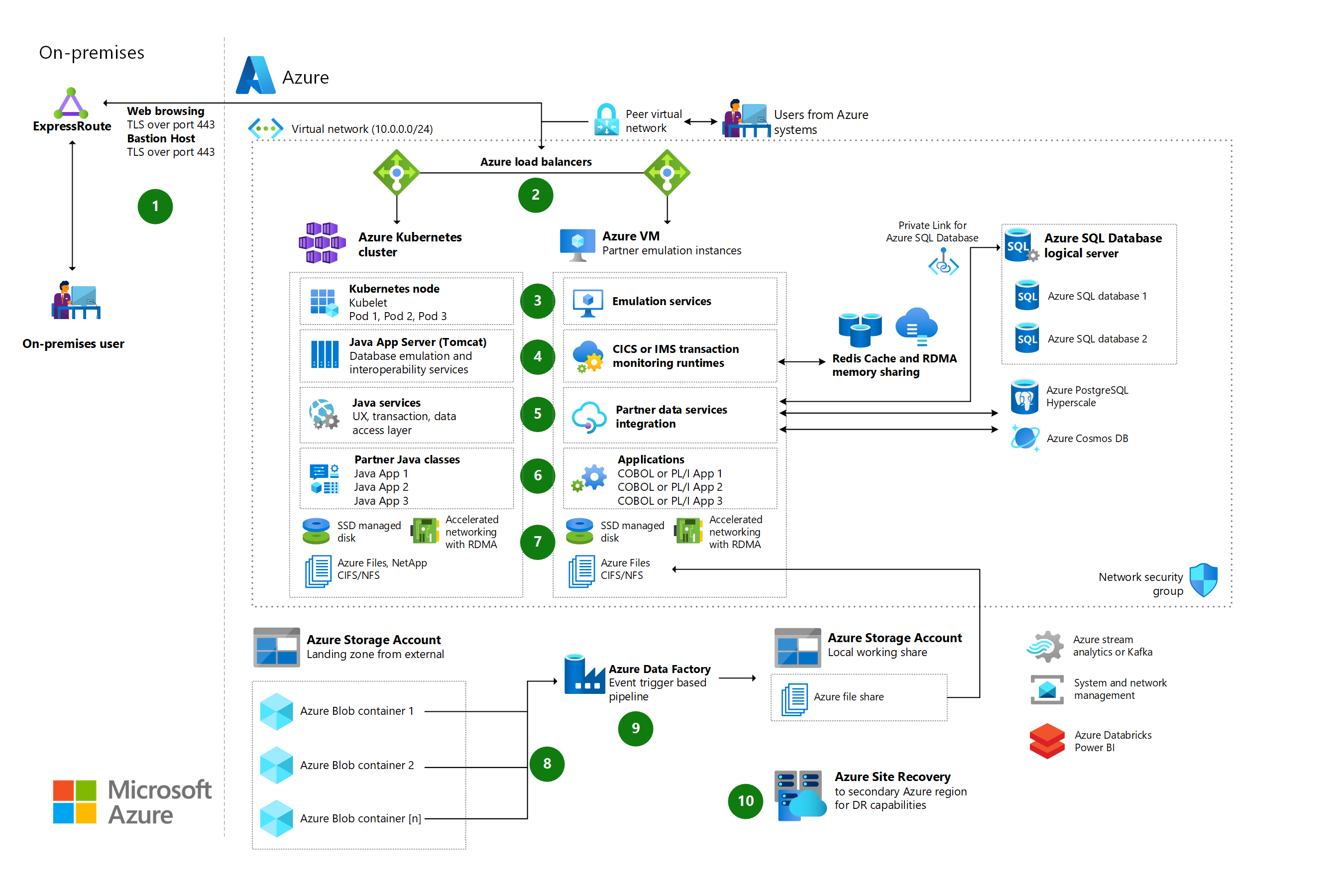
Refactoring requires minimal changes to applications. This often enables the application architecture to take advantage of Azure platform as a service (PaaS) and other cloud offerings. For example, you could migrate compute components of existing applications to Azure App Service or to Azure Kubernetes Service (AKS). You could also refactor relational and nonrelational databases into various options, such as Azure SQL Managed Instance, Azure Database for MySQL, Azure Database for PostgreSQL, and Azure Cosmos DB.
General mainframe refactor to Azure
See how to refactor general mainframe applications to run more cost-effectively and efficiently on Azure.
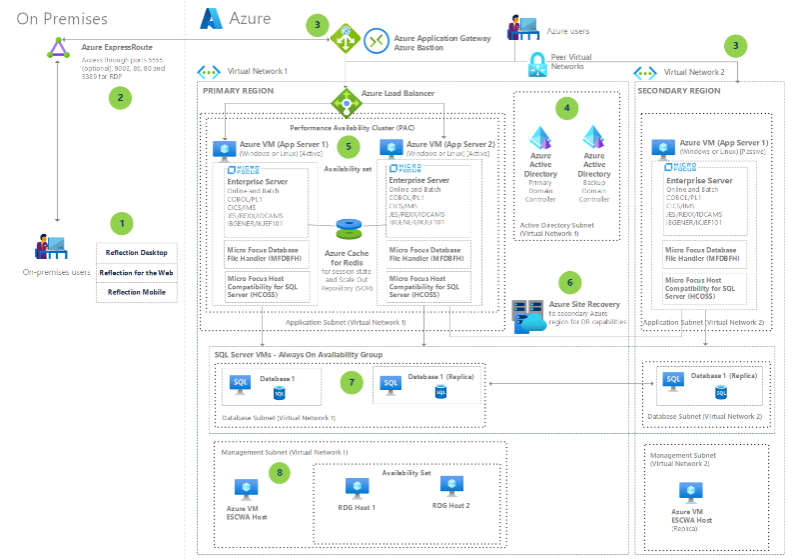
Micro Focus Enterprise Server on Azure VMs
Optimize, modernize, and streamline IBM z/OS mainframe applications by using Micro Focus Enterprise Server 6.0 on Azure VMs.
Refactor IBM z/OS mainframe Coupling Facility (CF) to Azure
Learn how Azure services and components can provide scale-out performance comparable to IBM z/OS mainframe CF and Parallel Sysplex capabilities.
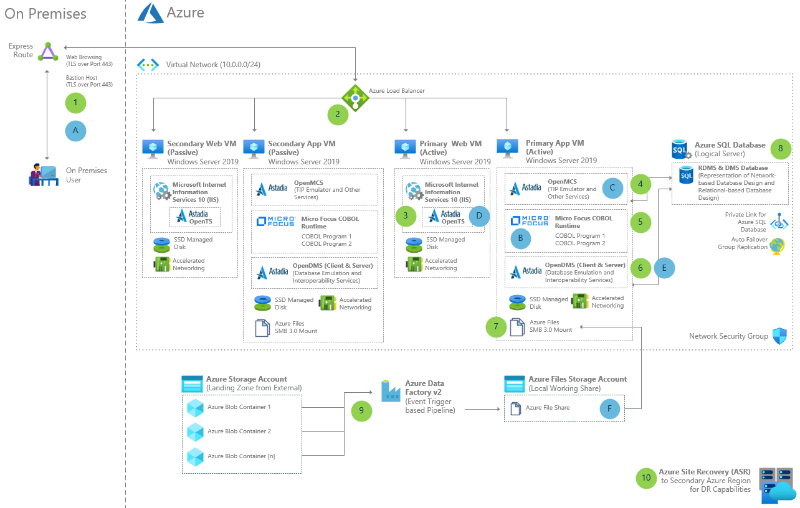
Unisys Dorado mainframe migration to Azure with Astadia & Micro Focus
Migrate Unisys Dorado mainframe systems with Astadia and Micro Focus products. Move to Azure without rewriting code, switching data models, or updating screens.
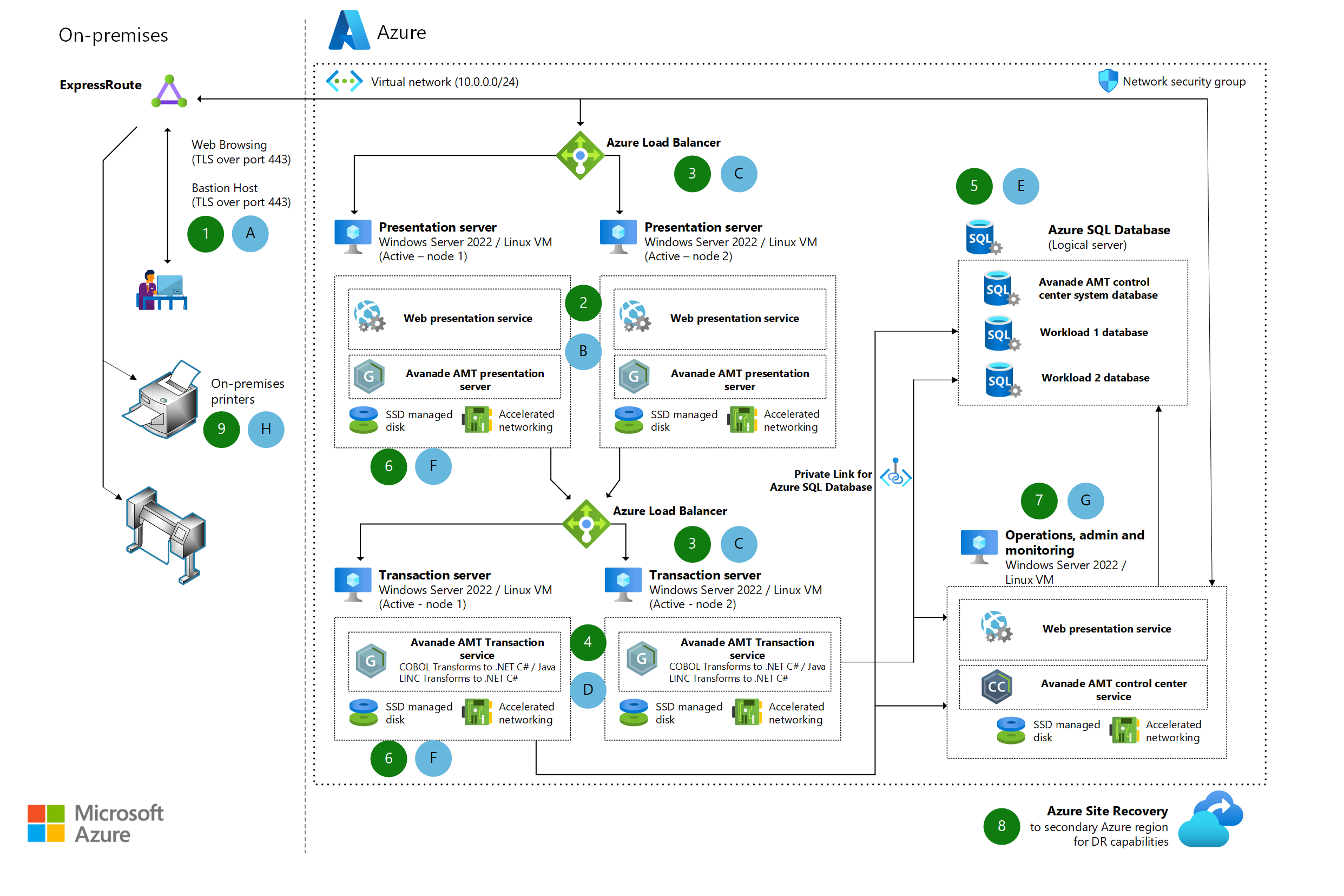
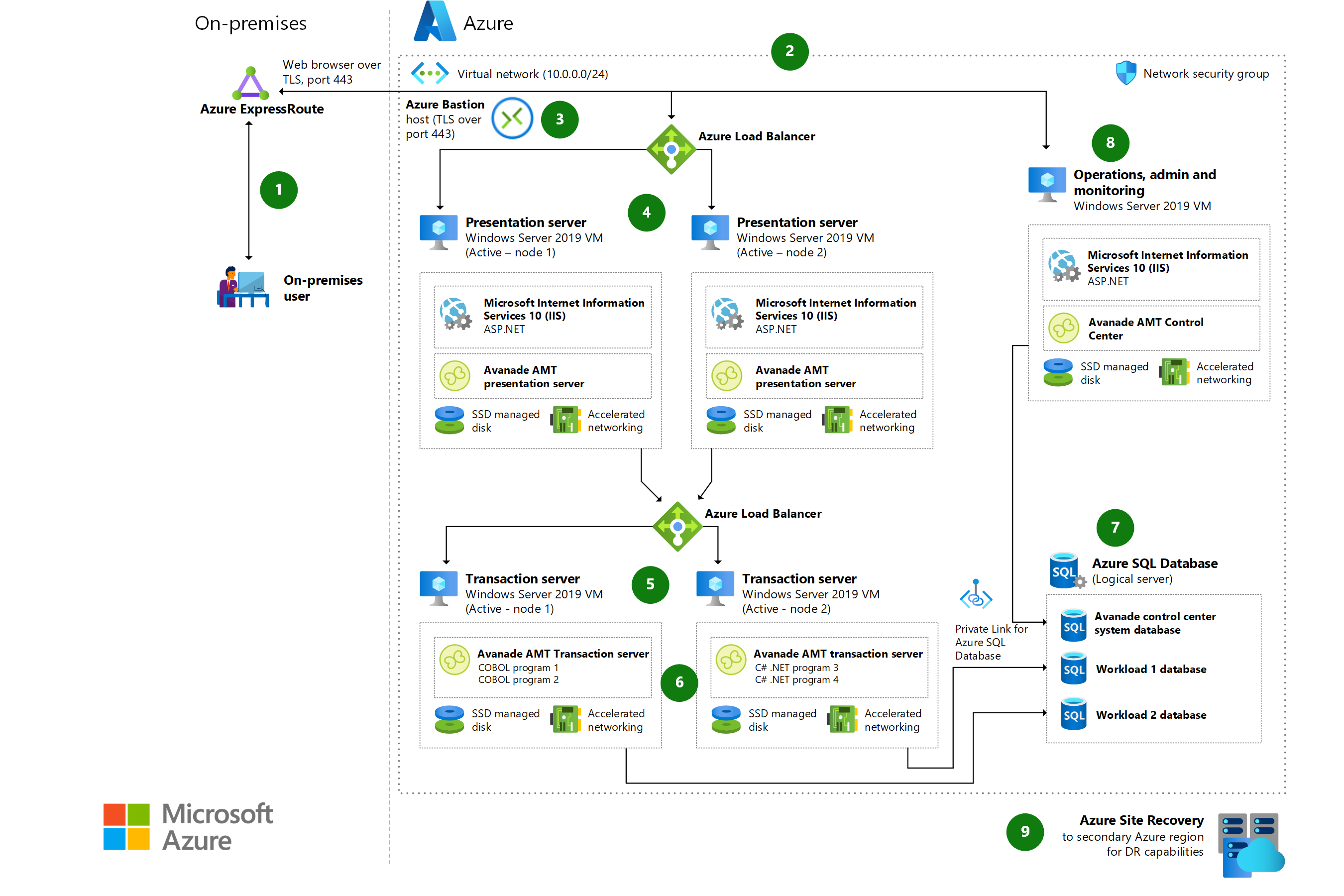
Unisys mainframe migration
Learn about options for using the Avanade Automated Migration Technology (AMT) Framework to migrate Unisys mainframe workloads to Azure.
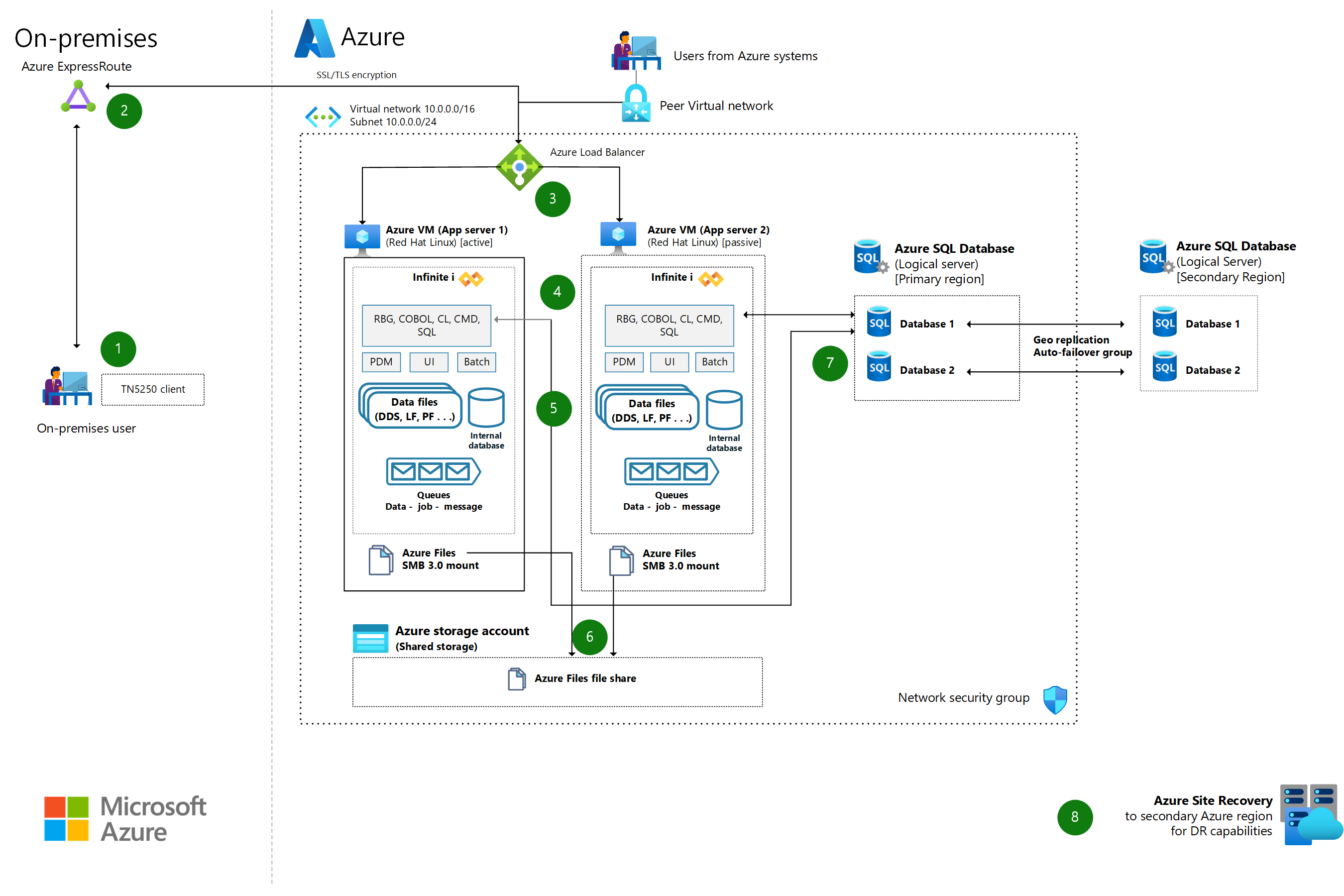
IBM System i (AS/400) to Azure using Infinite i
Use Infinite i to easily migrate your IBM System i (AS/400) workloads to Azure. You can lower costs, improve performance, improve availability, and modernize.
IBM z/OS mainframe migration with Avanade AMT
See how to use the Avanade Automated Migration Technology (AMT) framework to migrate IBM z/OS mainframe workloads to Azure.
Rehost mainframe applications to Azure with Raincode compilers
This architecture shows how the Raincode COBOL compiler modernizes mainframe legacy applications.
IBM z/OS online transaction processing on Azure
Migrate a z/OS online transaction processing (OLTP) workload to an Azure application that is cost-effective, responsive, scalable, and adaptable.
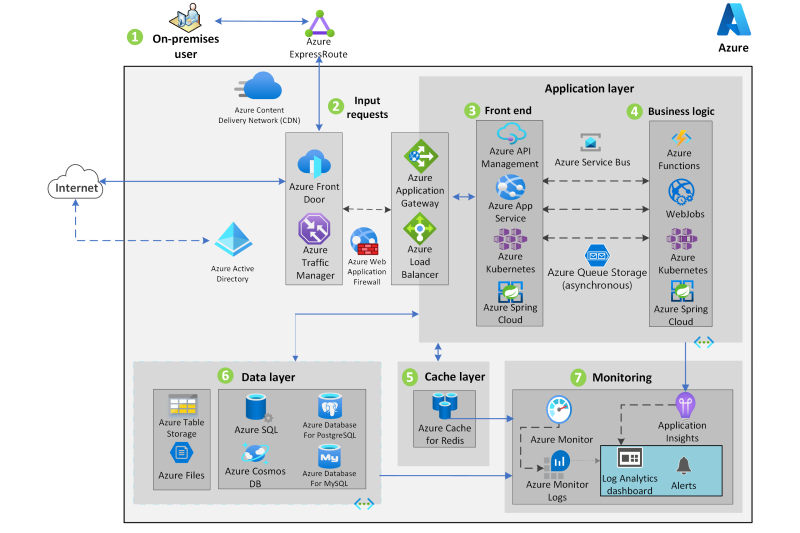
Re-engineering for migration focuses on modifying and extending application functionality and the code base to optimize the application architecture for cloud scalability. For example, you could break down a monolithic application into a group of microservices that work together and scale easily. You could also rearchitect relational and nonrelational databases to a fully managed database solution, such as SQL Managed Instance, Azure Database for MySQL, Azure Database for PostgreSQL, and Azure Cosmos DB.
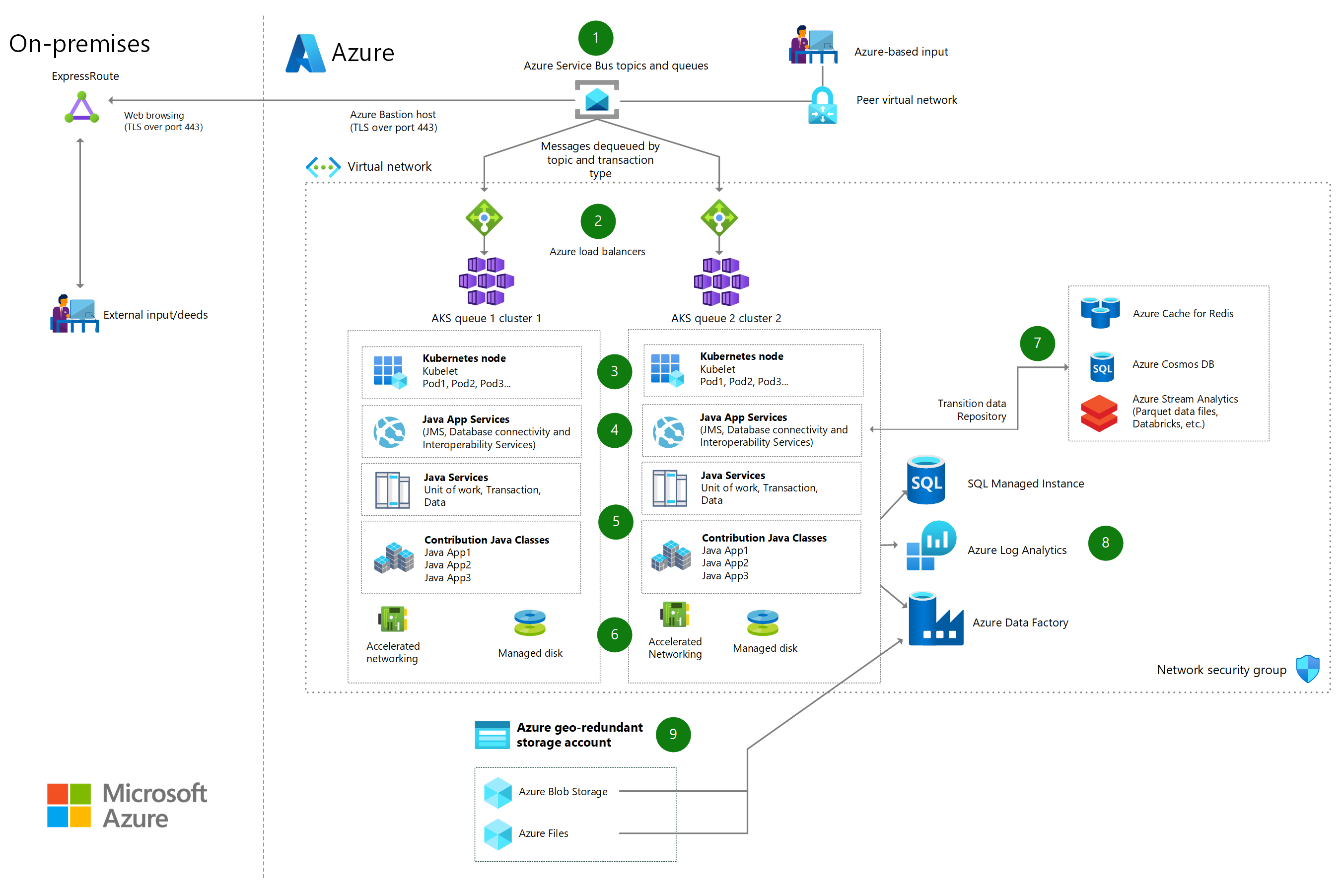
High-volume batch transaction processing
Use Azure Kubernetes Service (AKS) and Azure Service Bus to implement high-volume batch transaction processing.
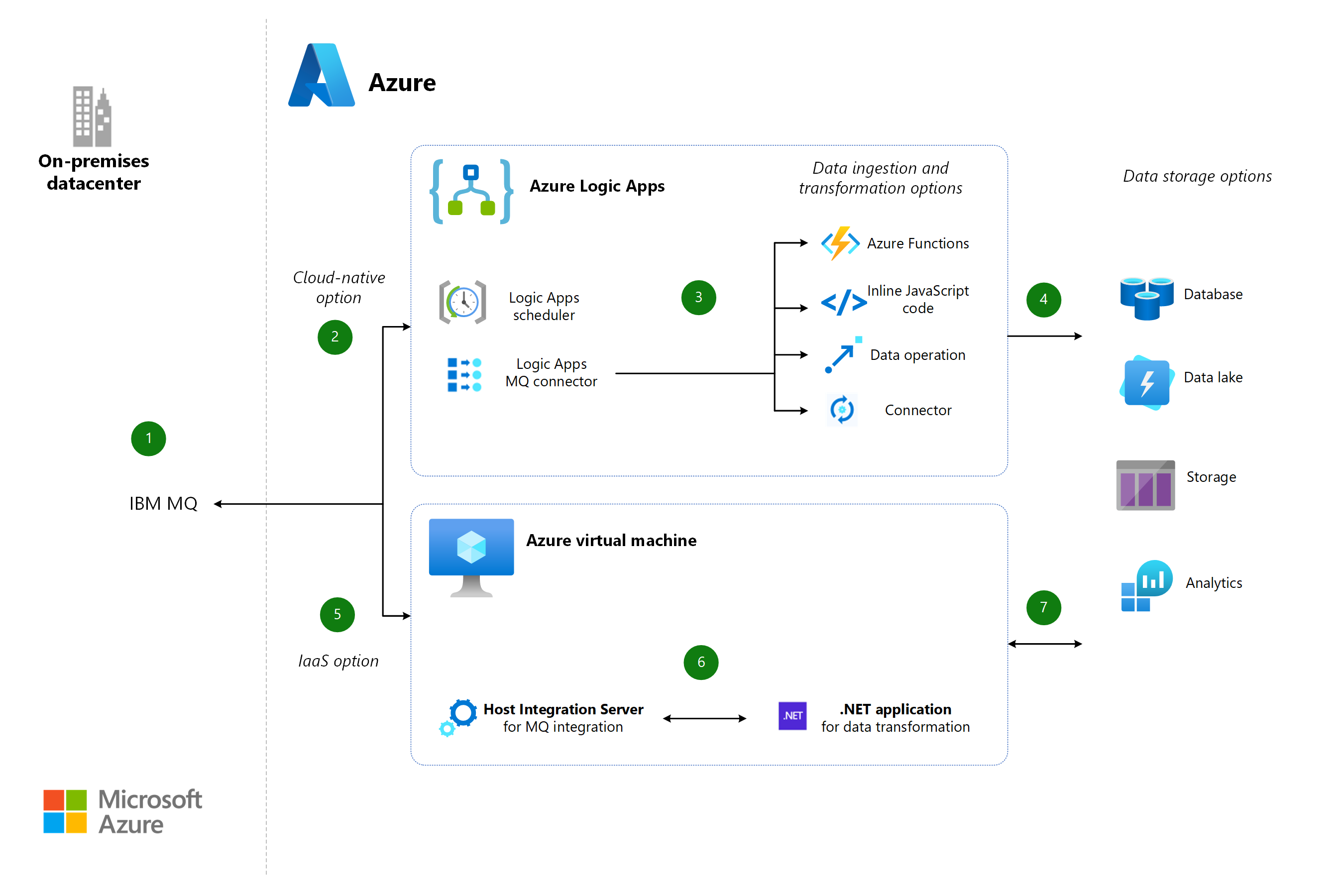
Integrate IBM mainframe and midrange message queues with Azure
This example describes a data-first approach to middleware integration that enables IBM message queues (MQs).
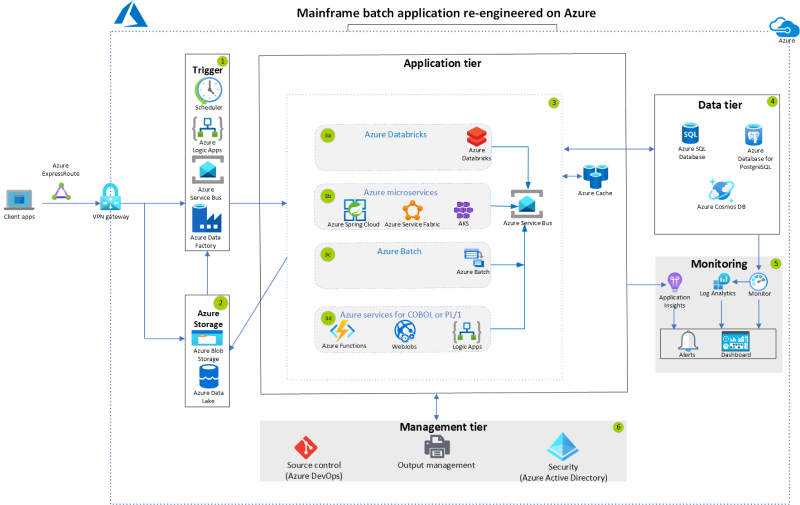
Re-engineer IBM z/OS batch applications on Azure
Use Azure services to re-engineer mainframe batch applications. This architecture change can reduce costs and improve scalability.
Another pattern for migrations into Azure (for legacy systems) is what is known as dedicated hardware. This pattern is where legacy hardware (such as IBM Power Systems) runs inside the Azure datacenter, with an Azure managed-service wrapping around the hardware, which enables easy cloud management and automation. Further, this hardware is available to connect to and use with other Azure IaaS and PaaS services.
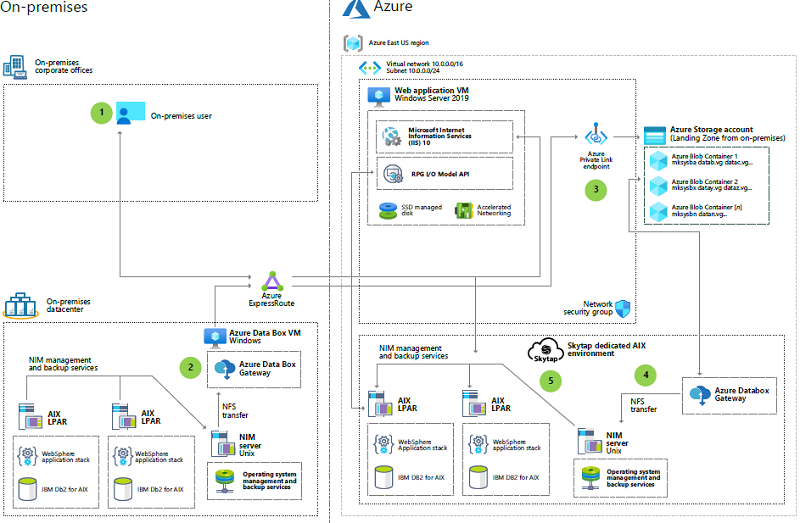
Migrate AIX workloads to Skytap on Azure
This example illustrates a migration of AIX logical partitions (LPARs) to Skytap on Azure.
Migrate IBM i series applications to Skytap on Azure
This example architecture shows how to use the native IBM i backup and recovery services with Microsoft Azure components.
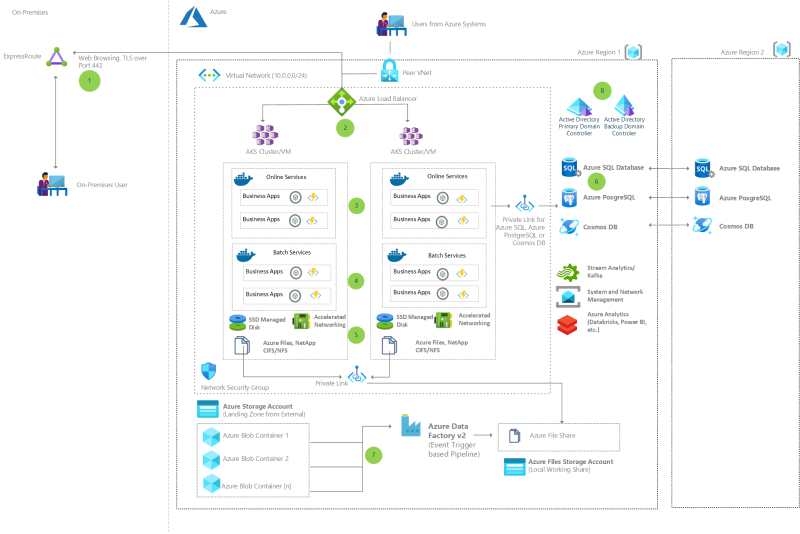
A key part of legacy migrations and transformations to Azure is consideration for data. This can include not only data movement, but also data replication and synchronization.
Modernize mainframe & midrange data
Learn how to modernize IBM mainframe and midrange data. See how to use a data-first approach to migrate this data to Azure.
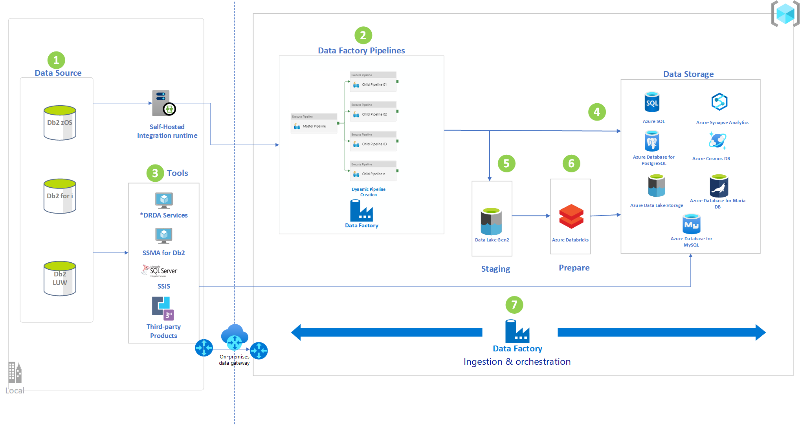
Replicate and sync mainframe data in Azure
Replicate data while modernizing mainframe and midrange systems. Sync on-premises data with Azure data during modernization.
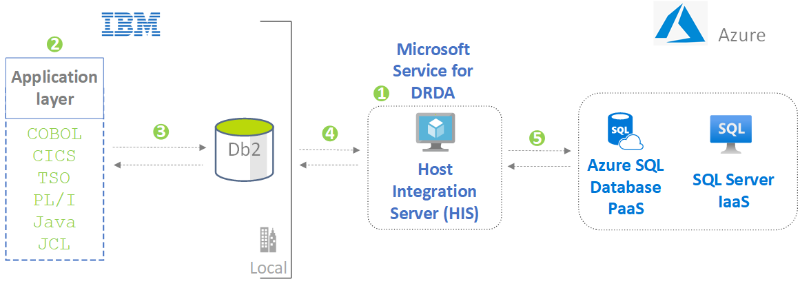
Mainframe access to Azure databases
Give mainframe applications access to Azure data without changing code. Use Microsoft Service for DRDA to run Db2 SQL statements on a SQL Server database.
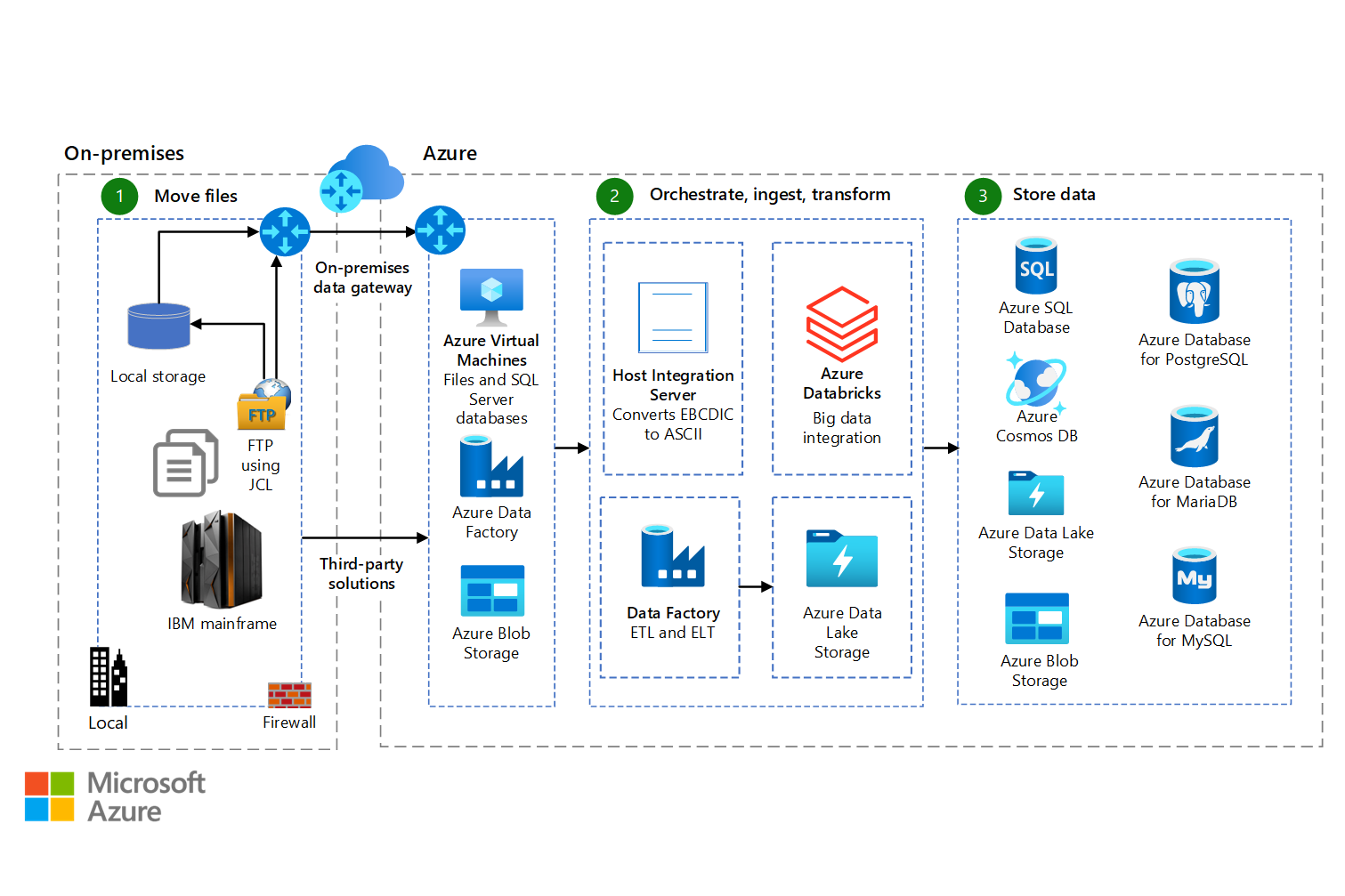
Mainframe file replication and sync on Azure
Learn about several options for moving, converting, transforming, and storing mainframe and midrange file system data on-premises and in Azure.
The white papers, blogs, webinars, and other resources are available to help you on your journey, to understand the pathways to migrate legacy systems into Azure:
Different industries are migrating from legacy mainframe and midrange systems in innovative and inspiring ways. See the following customer case studies and success stories:
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for