Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Service Bus
Azure Queue Storage
Azure Event Hubs
Many services use a throttling pattern to control the resources they consume, imposing limits on the rate at which other applications or services can access them. You can use a rate limiting pattern to help you avoid or minimize throttling errors related to these throttling limits and to help you more accurately predict throughput.
A rate limiting pattern is appropriate in many scenarios, but it is particularly helpful for large-scale repetitive automated tasks such as batch processing.
Context and problem
Performing large numbers of operations using a throttled service can result in increased traffic and throughput, as you'll need to both track rejected requests and then retry those operations. As the number of operations increases, a throttling limit might require multiple passes of resending data, resulting in a larger performance impact.
As an example, consider the following naive retry on error process for ingesting data into Azure Cosmos DB:
- Your application needs to ingest 10,000 records into Azure Cosmos DB. Each record costs 10 Request Units (RUs) to ingest, requiring a total of 100,000 RUs to complete the job.
- Your Azure Cosmos DB instance has 20,000 RUs provisioned capacity.
- You send all 10,000 records to Azure Cosmos DB. 2,000 records are written successfully and 8,000 records are rejected.
- You send the remaining 8,000 records to Azure Cosmos DB. 2,000 records are written successfully and 6,000 records are rejected.
- You send the remaining 6,000 records to Azure Cosmos DB. 2,000 records are written successfully and 4,000 records are rejected.
- You send the remaining 4,000 records to Azure Cosmos DB. 2,000 records are written successfully and 2,000 records are rejected.
- You send the remaining 2,000 records to Azure Cosmos DB. All are written successfully.
The ingestion job completed successfully, but only after sending 30,000 records to Azure Cosmos DB even though the entire data set only consisted of 10,000 records.
There are additional factors to consider in the above example:
- Large numbers of errors can also result in additional work to log these errors and process the resulting log data. This naive approach will have handled 20,000 errors, and logging these errors might impose a processing, memory, or storage resource cost.
- Not knowing the throttling limits of the ingestion service, the naive approach has no way to set expectations for how long data processing will take. Rate limiting can allow you to calculate the time required for ingestion.
Solution
Rate limiting can reduce your traffic and potentially improve throughput by reducing the number of records sent to a service over a given period of time.
A service can throttle based on different metrics over time, such as:
- The number of operations (for example, 20 requests per second).
- The amount of data (for example, 2 GiB per minute).
- The relative cost of operations (for example, 20,000 RUs per second).
Regardless of the metric used for throttling, your rate limiting implementation will involve controlling the number and/or size of operations sent to the service over a specific time period, optimizing your use of the service while not exceeding its throttling capacity.
In scenarios where your APIs can handle requests faster than throttled ingestion services allow, you must manage how quickly you use the service. Treating throttling only as a data-rate mismatch and buffering ingestion requests until the service recovers creates risk. If your application crashes in this scenario, any buffered data might be lost.
To avoid this risk, consider sending your records to a durable messaging system that can handle your full ingestion rate. (Services such as Azure Event Hubs can handle millions of operations per second). You can then use one or more job processors to read the records from the messaging system at a controlled rate that is within the throttled service's limits. Submitting records to the messaging system can save internal memory by allowing you to dequeue only the records that can be processed during a given time interval.
Azure provides several durable messaging services that you can use with this pattern, including:
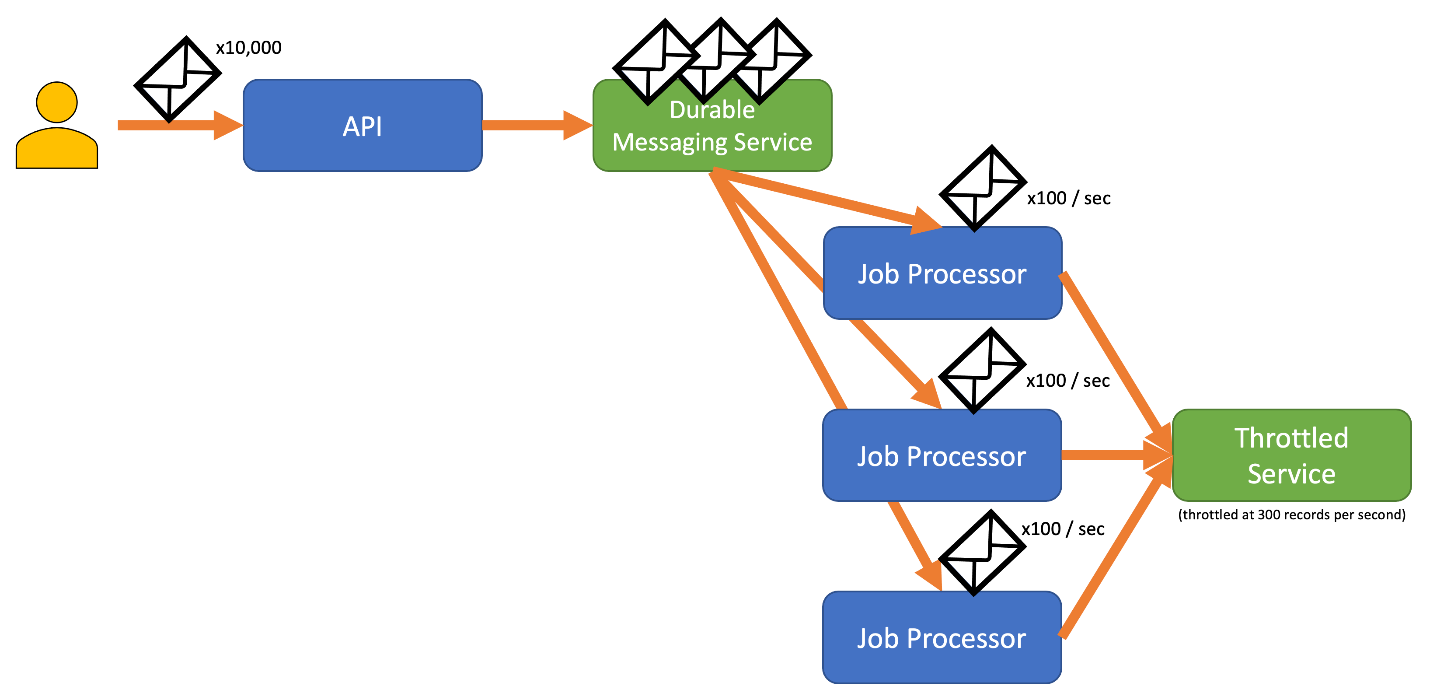
When you're sending records, the time period you use for releasing records might be more granular than the period the service throttles on. Systems often set throttles based on timespans you can easily comprehend and work with. However, for the computer running a service, these timeframes might be very long compared to how fast it can process information. For instance, a system might throttle per second or per minute, but commonly the code is processing on the order of nanoseconds or milliseconds.
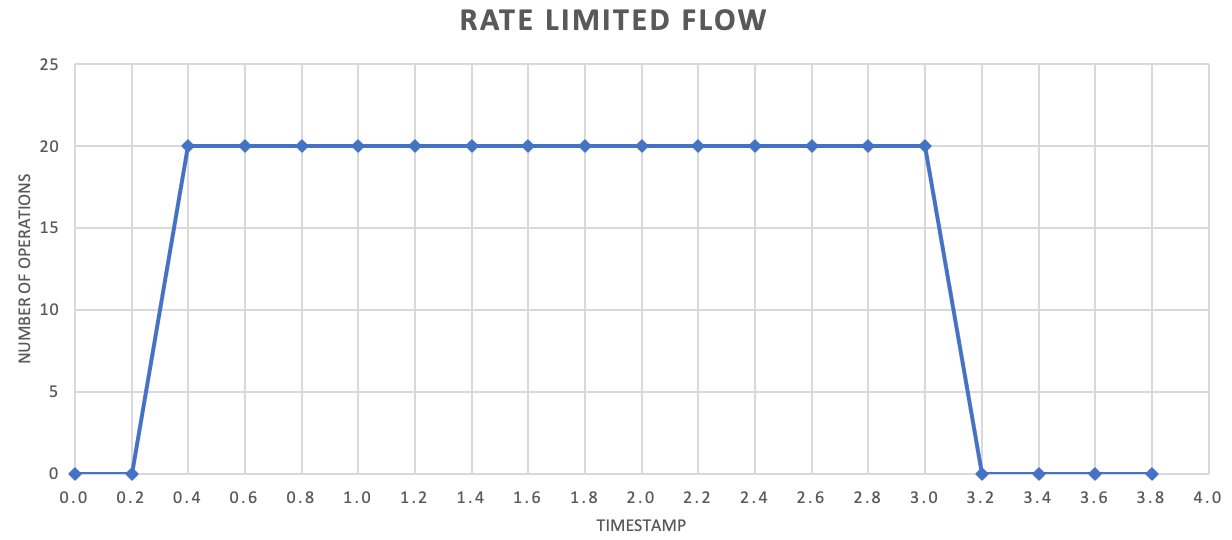
While not required, it's often recommended to send smaller amounts of records more frequently to improve throughput. So rather than trying to batch things up for a release once a second or once a minute, you can be more granular than that to keep your resource consumption (memory, CPU, and network) flowing at a more even rate, preventing potential bottlenecks due to sudden bursts of requests. For example, if a service allows 100 operations per second, the implementation of a rate limiter might even out requests by releasing 20 operations every 200 milliseconds, as shown in the following graph.
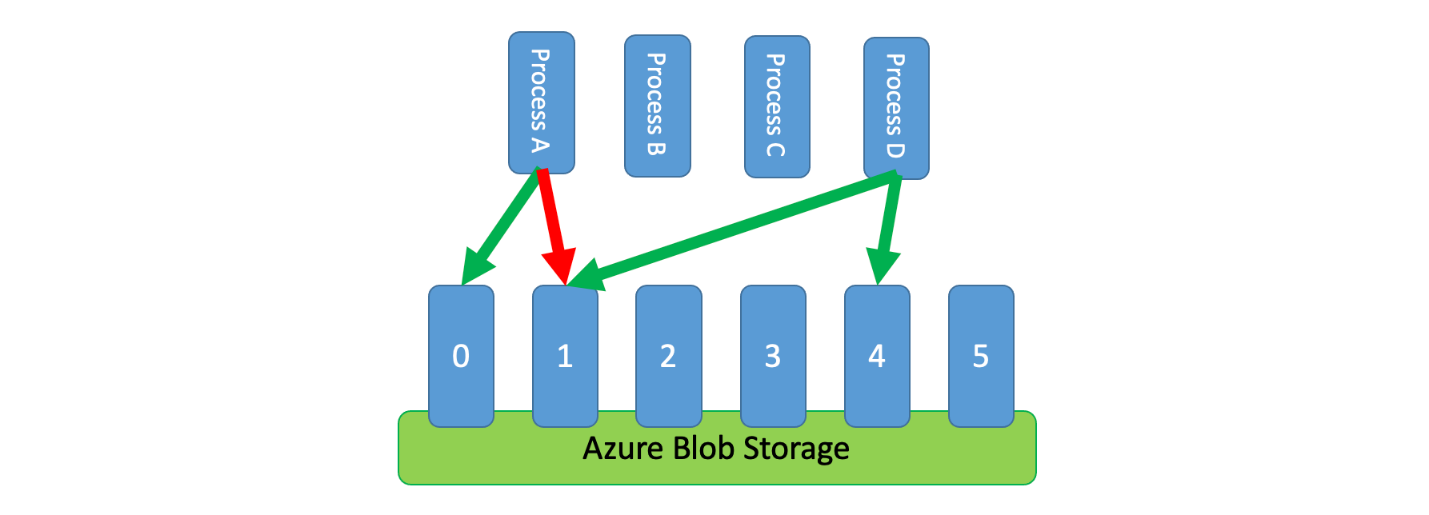
In addition, it's sometimes necessary for multiple uncoordinated processes to share a throttled service. To implement rate limiting in this scenario you can logically partition the service's capacity and then use a distributed mutual exclusion system to manage exclusive locks on those partitions. The uncoordinated processes can then compete for locks on those partitions whenever they need capacity. For each partition that a process holds a lock for, it's granted a certain amount of capacity.
For example, if the throttled system allows 500 requests per second, you might create 20 partitions worth 25 requests per second each. If a process needed to issue 100 requests, it might ask the distributed mutual exclusion system for four partitions. The system might grant two partitions for 10 seconds. The process would then rate limit to 50 requests per second, complete the task in two seconds, and then release the lock.
One way to implement this pattern would be to use Azure Storage. In this scenario, you create one 0-byte blob per logical partition in a container. Your applications can then obtain exclusive leases directly against those blobs for a short period of time (for example, 15 seconds). For every lease an application is granted, it will be able to use that partition's worth of capacity. The application then needs to track the lease time so that, when it expires, it can stop using the capacity it was granted. When implementing this pattern, you'll often want each process to attempt to lease a random partition when it needs capacity.
To further reduce latency, you might allocate a small amount of exclusive capacity for each process. A process would then only seek to obtain a lease on shared capacity if it needed to exceed its reserved capacity.
As an alternative to Azure Storage, you could also implement this kind of lease management system using technologies such as Zookeeper, Consul, etcd, Redis/Redsync, and others.
Issues and considerations
Consider the following when deciding how to implement this pattern:
- While the rate limiting pattern can reduce the number of throttling errors, your application will still need to properly handle any throttling errors that might occur.
- If your application has multiple workstreams that access the same throttled service, you'll need to integrate all of them into your rate limiting strategy. For instance, you might support bulk loading records into a database but also querying for records in that same database. You can manage capacity by ensuring all workstreams are gated through the same rate limiting mechanism. Alternatively, you might reserve separate pools of capacity for each workstream.
- The throttled service might be used in multiple applications. In some—but not all—cases it is possible to coordinate that usage (as shown above). If you start seeing a larger than expected number of throttling errors, this might be a sign of contention between applications accessing a service. If so, you might need to consider temporarily reducing the throughput imposed by your rate limiting mechanism until the usage from other applications lowers.
When to use this pattern
Use this pattern to:
- Reduce throttling errors raised by a throttle-limited service.
- Reduce traffic compared to a naive retry on error approach.
- Reduce memory consumption by dequeuing records only when there is capacity to process them.
Workload design
An architect should evaluate how the Rate Limiting pattern can be used in their workload's design to address the goals and principles covered in the Azure Well-Architected Framework pillars. For example:
| Pillar | How this pattern supports pillar goals |
|---|---|
| Reliability design decisions help your workload become resilient to malfunction and to ensure that it recovers to a fully functioning state after a failure occurs. | This tactic protects the client by acknowledging and honoring the limitations and costs of communicating with a service when the service desires to avoid excessive usage. - RE:07 Self-preservation |
As with any design decision, consider any tradeoffs against the goals of the other pillars that might be introduced with this pattern.
Example
The following example application allows users to submit records of various types to an API. There is a unique job processor for each record type that performs the following steps:
- Validation
- Enrichment
- Insertion of the record into the database
All components of the application (API, job processor A, and job processor B) are separate processes that can be scaled independently. The processes do not directly communicate with one another.
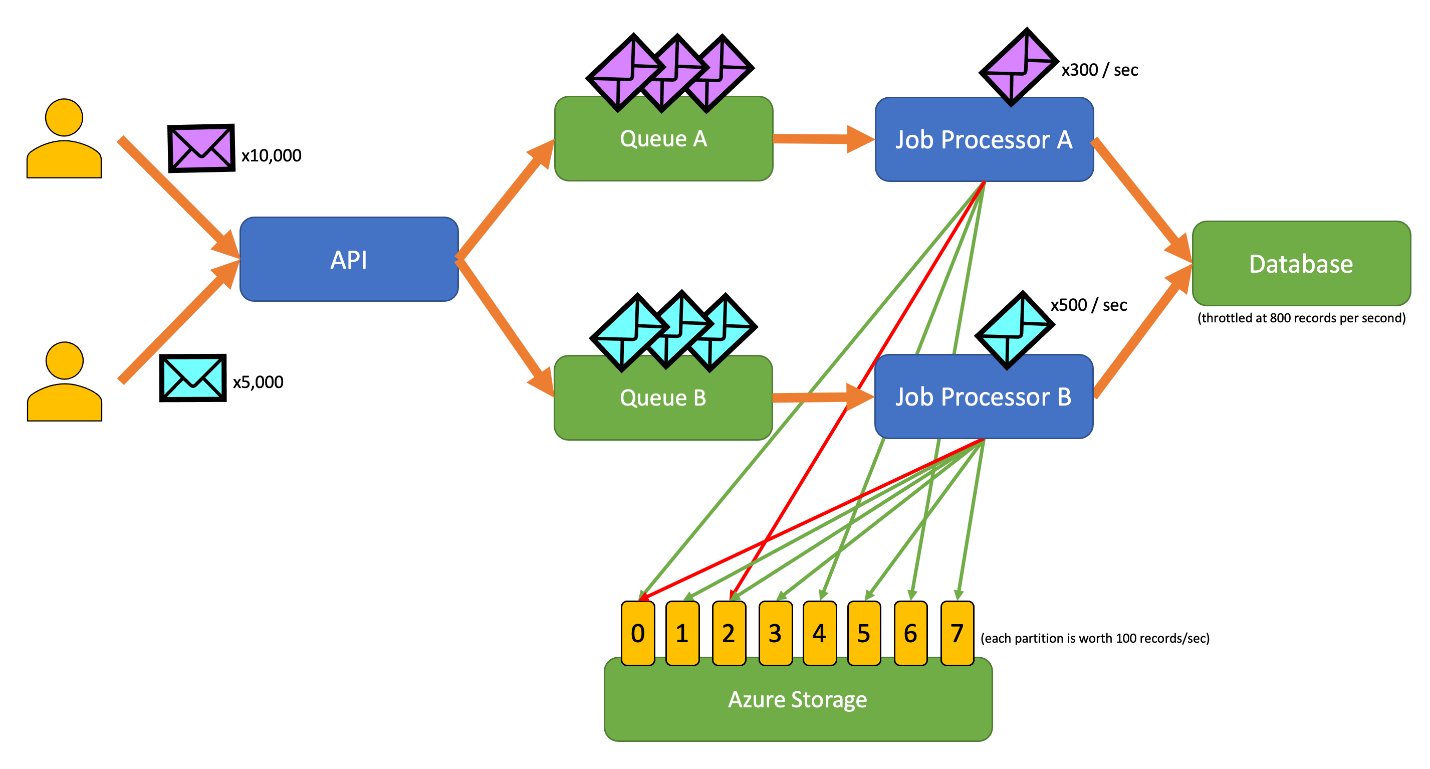
This diagram incorporates the following workflow:
- A user submits 10,000 records of type A to the API.
- The API enqueues those 10,000 records in Queue A.
- A user submits 5,000 records of type B to the API.
- The API enqueues those 5,000 records in Queue B.
- Job Processor A sees Queue A has records and tries to gain an exclusive lease on blob 2.
- Job Processor B sees Queue B has records and tries to gain an exclusive lease on blob 2.
- Job Processor A fails to obtain the lease.
- Job Processor B obtains the lease on blob 2 for 15 seconds. It can now rate limit requests to the database at a rate of 100 per second.
- Job Processor B dequeues 100 records from Queue B and writes them.
- One second passes.
- Job Processor A sees Queue A has more records and tries to gain an exclusive lease on blob 6.
- Job Processor B sees Queue B has more records and tries to gain an exclusive lease on blob 3.
- Job Processor A obtains the lease on blob 6 for 15 seconds. It can now rate limit requests to the database at a rate of 100 per second.
- Job Processor B obtains the lease on blob 3 for 15 seconds. It can now rate limit requests to the database at a rate of 200 per second. (It also holds the lease for blob 2.)
- Job Processor A dequeues 100 records from Queue A and writes them.
- Job Processor B dequeues 200 records from Queue B and writes them.
- One second passes.
- Job Processor A sees Queue A has more records and tries to gain an exclusive lease on blob 0.
- Job Processor B sees Queue B has more records and tries to gain an exclusive lease on blob 1.
- Job Processor A obtains the lease on blob 0 for 15 seconds. It can now rate limit requests to the database at a rate of 200 per second. (It also holds the lease for blob 6.)
- Job Processor B obtains the lease on blob 1 for 15 seconds. It can now rate limit requests to the database at a rate of 300 per second. (It also holds the lease for blobs 2 and 3.)
- Job Processor A dequeues 200 records from Queue A and writes them.
- Job Processor B dequeues 300 records from Queue B and writes them.
- And so on...
After 15 seconds, one or both jobs still will not be completed. As the leases expire, a processor should also reduce the number of requests it dequeues and writes.
 Implementations of this pattern are available in different programming languages:
Implementations of this pattern are available in different programming languages:
Related resources
The following patterns and guidance might also be relevant when implementing this pattern:
- Throttling. The rate limiting pattern discussed here is typically implemented in response to a service that is throttled.
- Retry. When requests to throttled service result in throttling errors, it's generally appropriate to retry those after an appropriate interval.
Queue-Based Load Leveling is similar but differs from the Rate Limiting pattern in several key ways:
- Rate limiting doesn't necessarily need to use queues to manage load, but it does need to make use of a durable messaging service. For example, a rate limiting pattern can make use of services like Apache Kafka or Azure Event Hubs.
- The rate limiting pattern introduces the concept of a distributed mutual exclusion system on partitions, which allows you to manage capacity for multiple uncoordinated processes that communicate with the same throttled service.
- A queue-based load leveling pattern is applicable anytime there is a performance mismatch between services or to improve resilience. This makes it a broader pattern than rate limiting, which is more specifically concerned with efficiently accessing a throttled service.