Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Vectors are high-dimensional embeddings that represent text, images, and other content mathematically. Azure AI Search stores vectors at the field level, allowing vector and nonvector content to coexist within the same search index.
A search index becomes a vector index when you define vector fields and a vector configuration. To populate vector fields, you can push precomputed embeddings into them or use integrated vectorization, a built-in Azure AI Search capability that generates embeddings during indexing.
At query time, the vector fields in your index enable similarity search, where the system retrieves documents whose vectors are most similar to the vector query. You can use vector search for similarity matching alone or hybrid search for a combination of similarity and keyword matching.
This article covers the key concepts for creating and managing a vector index, including:
- Vector retrieval patterns
- Content (vector fields and configuration)
- Physical data structure
- Basic operations
Tip
Want to get started right away? See Create a vector index.
Vector retrieval patterns
Azure AI Search supports two patterns for vector retrieval:
Classic search. This pattern uses a search bar, query input, and rendered results. During query execution, the search engine or your application code vectorizes the user input. The search engine then performs vector search over the vector fields in your index and formulates a response that you render in a client app.
In Azure AI Search, results are returned as a flattened row set, and you can choose which fields to include in the response. Although the search engine matches on vectors, your index should have nonvector, human-readable content to populate the search results. Classic search supports both vector queries and hybrid queries.
Generative search. Language models use data from Azure AI Search to respond to user queries. An orchestration layer typically coordinates prompts and maintains context, feeding search results into chat models like GPT. This pattern is based on the retrieval-augmented generation (RAG) architecture, where the search index provides grounding data.
Schema of a vector index
The schema of a vector index requires the following:
- Name
- Key field (string)
- One or more vector fields
- Vector configuration
Nonvector fields aren't required, but we recommend including them for hybrid queries or for returning verbatim content that doesn't go through a language model. For more information, see Create a vector index.
Your index schema should reflect your vector retrieval pattern. This section mostly covers field composition for classic search, but it also provides schema guidance for generative search.
Basic vector field configuration
Vector fields have unique data types and properties. Here's what a vector field looks like in a fields collection:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Only certain data types are supported for vector fields. The most common type is Collection(Edm.Single), but using narrow types can save on storage.
Vector fields must be searchable and retrievable, but they can't be filterable, facetable, or sortable. They also can't have analyzers, normalizers, or synonym map assignments.
The dimensions property must be set to the number of embeddings generated by the embedding model. For example, text-embedding-ada-002 generates 1,536 embeddings for each chunk of text.
Vector fields are indexed using algorithms specified in a vector search profile, which is defined elsewhere in the index and not shown in this example. For more information, see Add a vector search configuration.
Fields collection for basic vector workloads
Vector indexes require more than just vector fields. For example, all indexes must have a key field, which is id in the following example:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Other fields, such as the content field, provide the human-readable equivalent of the content_vector field. If you're using language models exclusively for response formulation, you can omit nonvector content fields, but solutions that push search results directly to client apps should have nonvector content.
Metadata fields are useful for filters, especially if they include origin information about the source document. Although you can't filter directly on a vector field, you can set prefilter, postfilter, or strict postfilter (preview) modes to filter before or after vector query execution.
Schema generated by the import wizard
We recommend the Import data wizard for evaluation and proof-of-concept testing. The wizard generates the example schema in this section.
The wizard chunks your content into smaller search documents, which benefits RAG apps that use language models to formulate responses. Chunking helps you stay within the input limits of language models and the token limits of semantic ranker. It also improves precision in similarity search by matching queries against chunks pulled from multiple parent documents. For more information, see Chunk large documents for vector search solutions.
For each search document in the following example, there's one chunk ID, parent ID, chunk, title, and vector field. The wizard:
Populates the
chunk_idandparent_idfields with base64-encoded blob metadata (path).Extracts the
chunkandtitlefields from the blob content and blob name, respectively.Creates the
vectorfield by calling an Azure OpenAI embedding model that you provide to vectorize thechunkfield. Only the vector field is fully generated during this process.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schema for generative search
If you're designing vector storage for RAG and chat-style apps, you can create two indexes:
- One for static content that you indexed and vectorized.
- One for conversations that can be used in prompt flows.
For illustrative purposes, this section uses the chat-with-your-data-solution-accelerator to create the chat-index and conversations indexes.
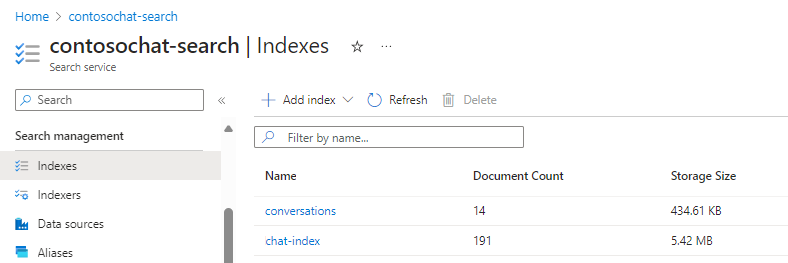
The following fields from chat-index support generative search experiences:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
The following fields from conversations support orchestration and chat history:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
The following screenshot shows search results for conversations in Search explorer:
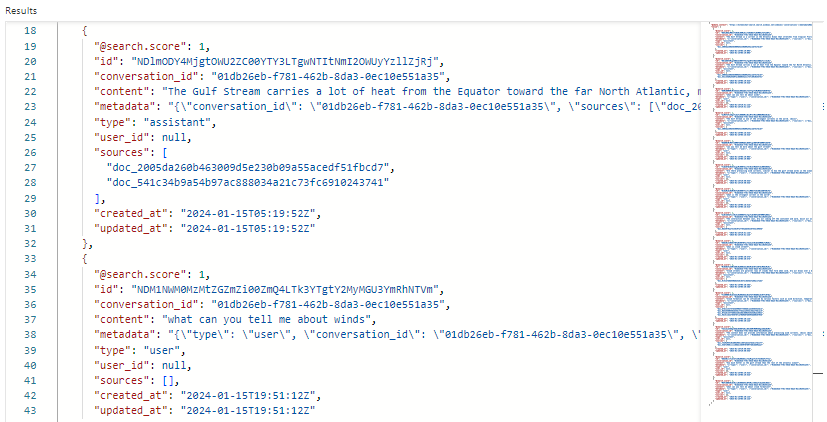
In our example, the search score is 1.00 because the search is unqualified. Several fields support orchestration and prompt flows:
conversation_ididentifies each chat session.typeindicates whether the content is from the user or the assistant.created_atandupdated_atage out chats from the history.
Physical structure and size
In Azure AI Search, the physical structure of an index is largely an internal implementation. You can access its schema, load and query its content, monitor its size, and manage its capacity. However, Microsoft manages the infrastructure and physical data structures stored with your search service.
The size and substance of an index are determined by the:
Quantity and composition of your documents.
Attributes on individual fields. For example, more storage is required for filterable fields.
Index configuration, including the vector configuration that specifies how the internal navigation structures are created. You can choose HNSW or exhaustive KNN for similarity search.
Azure AI Search imposes limits on vector storage, which helps maintain a balanced and stable system for all workloads. To help you stay under the limits, vector usage is tracked and reported separately in the Azure portal and programmatically through service and index statistics.
The following screenshot shows an S1 service configured with one partition and one replica. This service has 24 small indexes, each with an average of one vector field consisting of 1,536 embeddings. The second tile shows the quota and usage for vector indexes. Because a vector index is an internal data structure created for each vector field, storage for vector indexes is always a fraction of the overall storage used by the index. Nonvector fields and other data structures consume the rest.
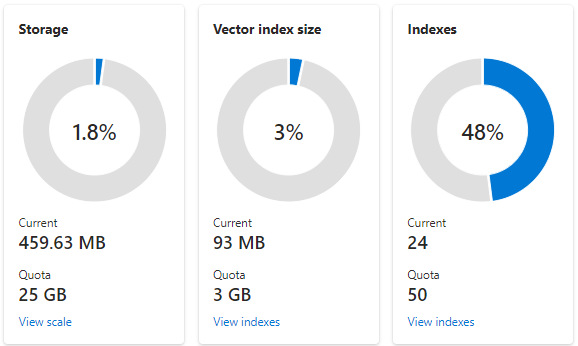
Vector index limits and estimations are covered in another article, but two points to emphasize are that maximum storage depends on the creation date and pricing tier of your search service. Newer same-tier services have significantly more capacity for vector indexes. For these reasons, you should:
Check the creation date of your search service. If it was created before April 3, 2024, you might be able to upgrade your service for greater capacity.
Choose a scalable tier if you anticipate fluctuations in vector storage requirements. For older search services, the Basic tier is fixed at one partition. Consider Standard 1 (S1) and higher for more flexibility and faster performance. You can also switch between Basic and Standard (S1, S2, and S3) tiers.
Basic operations and interaction
This section introduces vector runtime operations, including connecting to and securing a single index.
Note
There's no portal or API support for moving or copying an index. Typically, you either point your application deployment to a different search service (using the same index name) or revise the name to create a copy on your current search service and then build it.
Index isolation
In Azure AI Search, you work with one index at a time. All index-related operations target a single index. There's no concept of related indexes or the joining of independent indexes for either indexing or querying.
Continuously available
An index is immediately available for queries as soon as the first document is indexed, but it's not fully operational until all documents are indexed. Internally, an index is distributed across partitions and executes on replicas. The physical index is managed internally. You manage the logical index.
An index is continuously available and can't be paused or taken offline. Because it's designed for continuous operation, updates to its content and additions to the index itself happen in real time. If a request coincides with a document update, queries might temporarily return incomplete results.
Query continuity exists for document operations, such as refreshing or deleting, and for modifications that don't affect the existing structure or integrity of an index, such as adding new fields. Structural updates, such as changing existing fields, are typically managed using a drop-and-rebuild workflow in a development environment or by creating a new version of the index on the production service.
To avoid an index rebuild, some customers who are making small changes "version" a field by creating a new one that coexists with a previous version. Over time, this leads to orphaned content by way of obsolete fields and obsolete custom analyzer definitions, especially in a production index that's expensive to replicate. You can address these issues during planned updates to the index as part of index lifecycle management.
Endpoint connection
All vector indexing and query requests target an index. Endpoints are usually one of the following:
| Endpoint | Connection and access control |
|---|---|
<your-service>.search.windows.net/indexes |
Targets the indexes collection. Used when creating, listing, or deleting an index. Admin rights are required for these operations and available through admin API keys or a Search Contributor role. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Targets the documents collection of a single index. Used when querying an index or data refresh. For queries, read rights are sufficient and available through query API keys or a data reader role. For data refresh, admin rights are required. |
How to connect to Azure AI Search
Make sure you have permissions or an API access key. Unless you're querying an existing index, you need admin rights or a Contributor role assignment to manage and view content on a search service.
Start with the Azure portal. The person who created the search service can view and manage it, including granting access to others on the Access control (IAM) page.
Move on to other clients for programmatic access. For first steps, we recommend Quickstart: Vector searching using REST and the azure-search-vector-samples repo.
Manage vector stores
Azure provides a monitoring platform that includes diagnostic logging and alerting. We recommend that you:
Secure access to vector data
Azure AI Search implements data encryption, private connections for no-internet scenarios, and role assignments for secure access through Microsoft Entra ID. For more information about enterprise security features, see Data, privacy, and built-in protections.