Azure SQL Database
An Azure relational database service.
6,326 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESD%3C/text%3E%3C/svg%3E)
Hello,
We have a csv which has columns and values in rows, where all odd rows are columns and even rows contain values see screenshot below.
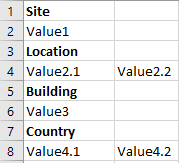
we want to insert this data in a sql database table which would look something like this

could you please guide in terms of what option we have to import this type of csv within Azure.

Hi @Sachin D ,
Just checking in to see if the below answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi @Sachin D ,
Just following up to see if the below answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi @Sachin D ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
The above requirement can be achieved using Mapping dataflow in azure data factory pipelines.
Kindly follow the below steps to achieve the above mentioned requirement:
1. Add source transformation and point your dataset to the .csv file . Preview the data . Two columns are present currently 'column_1' and 'col0'
2. Add surrogate key transformation to create an identity column 'Id'. It will assign an unique value corresponding to each row.
3. Add a conditional split with two Stream names 'ColumnNames' : Id%2!=0 and 'ColumnValues' . It will split the data into two parts: even rows and odd rows. Preview the data for both the conditions in data preview tab.

4. Add surrogate key transformation to both the branches to generate identity columns 'Id1' and 'Id2'. In the surrogate key data preview tab of below branch, click on 'Map drifted' option so that 'col0' would be included in the current schema. Add select transformation to deselect the unwanted 'col0' and 'Id' column from the first branch and 'Id' column from second branch.
5. Join the two streams 'select1' and 'select2' based on Id1 and Id2.
6. Now, create new branch out of Join transformation . In both the branches, Add select transformation to remove 'Id1' and 'Id2' on the basis of which we performed the join.
7. Add pivot transformation in both the branches. Skip the 'group by' tab. In pivot key tab, select 'ColumnName' as the pivot key . In the Pivoted columns of first branch, use max(ColumnValues) as the expression and in second branch use max(Col0) . Click on map drifted in data preview tab of both the pivot transformations.
8. Use Union transformation to union the data of both the map drifted outputs.
9. Use select transformation to sort the columns as per the need.
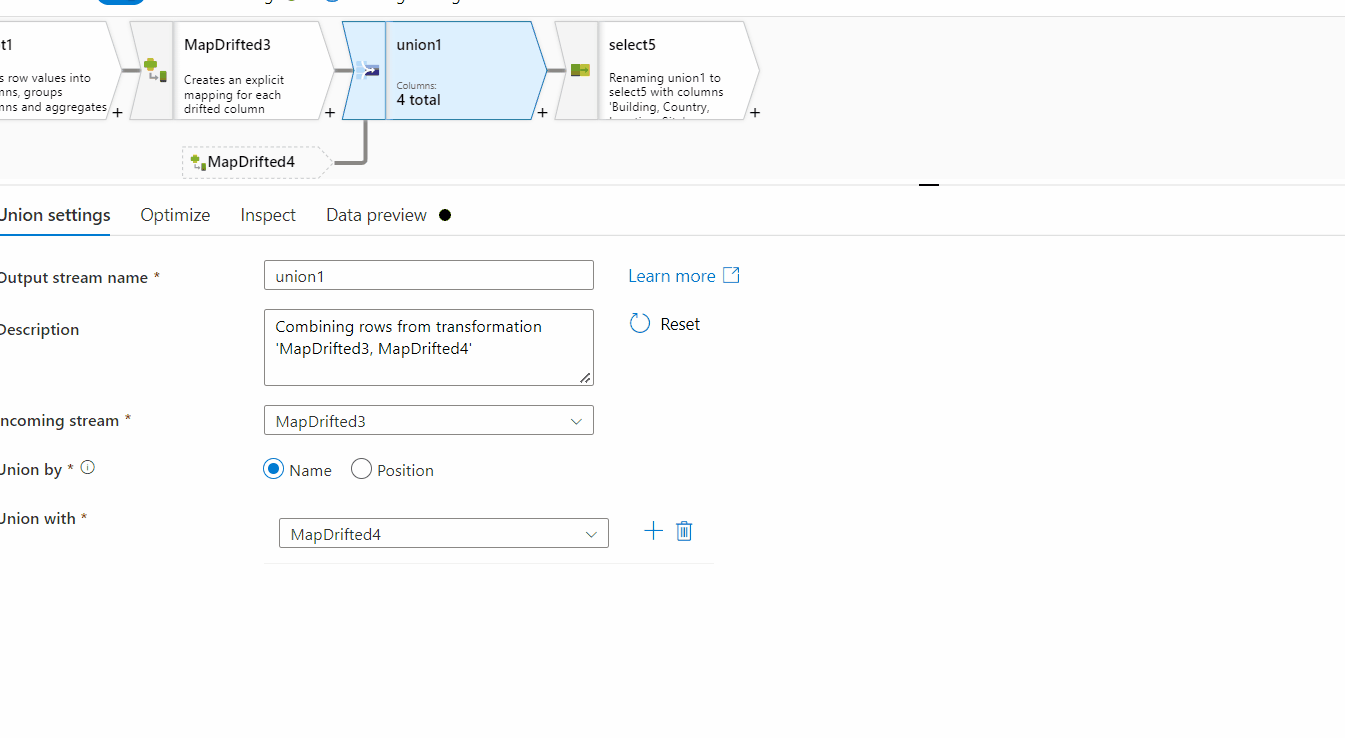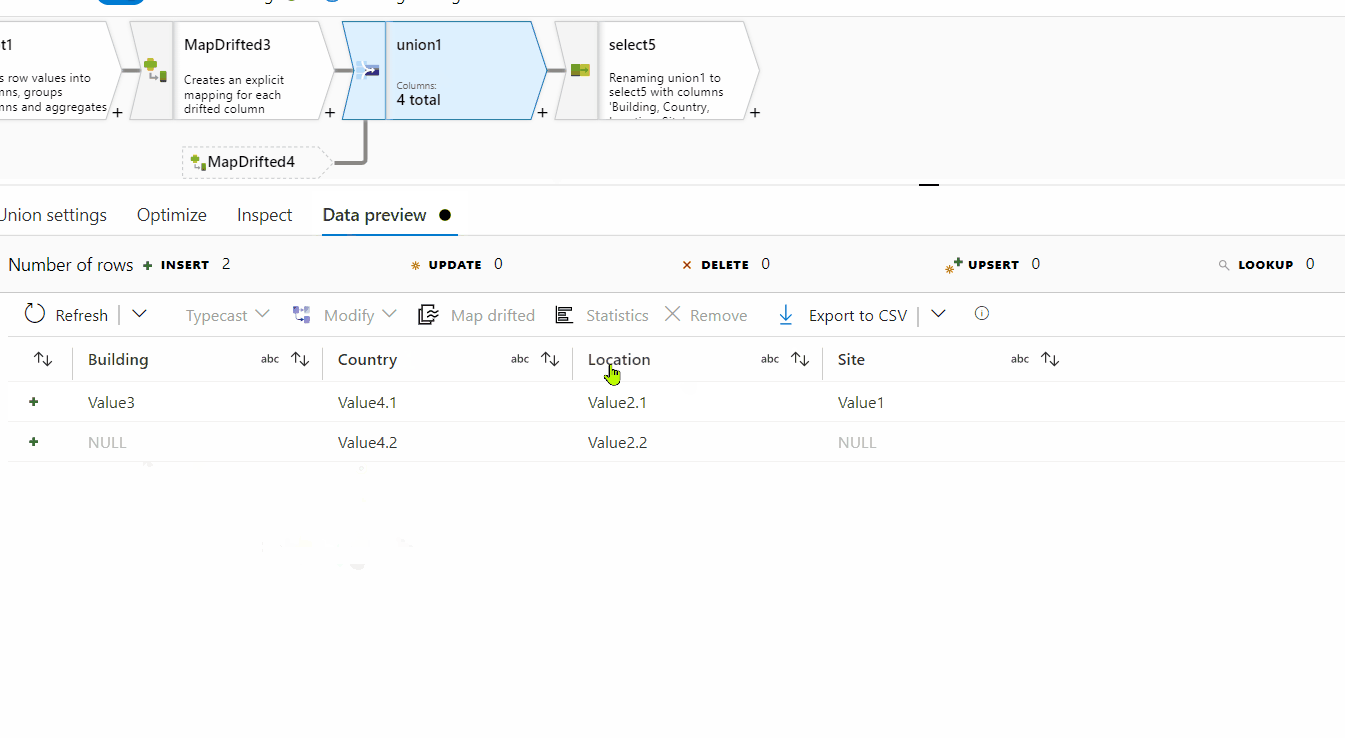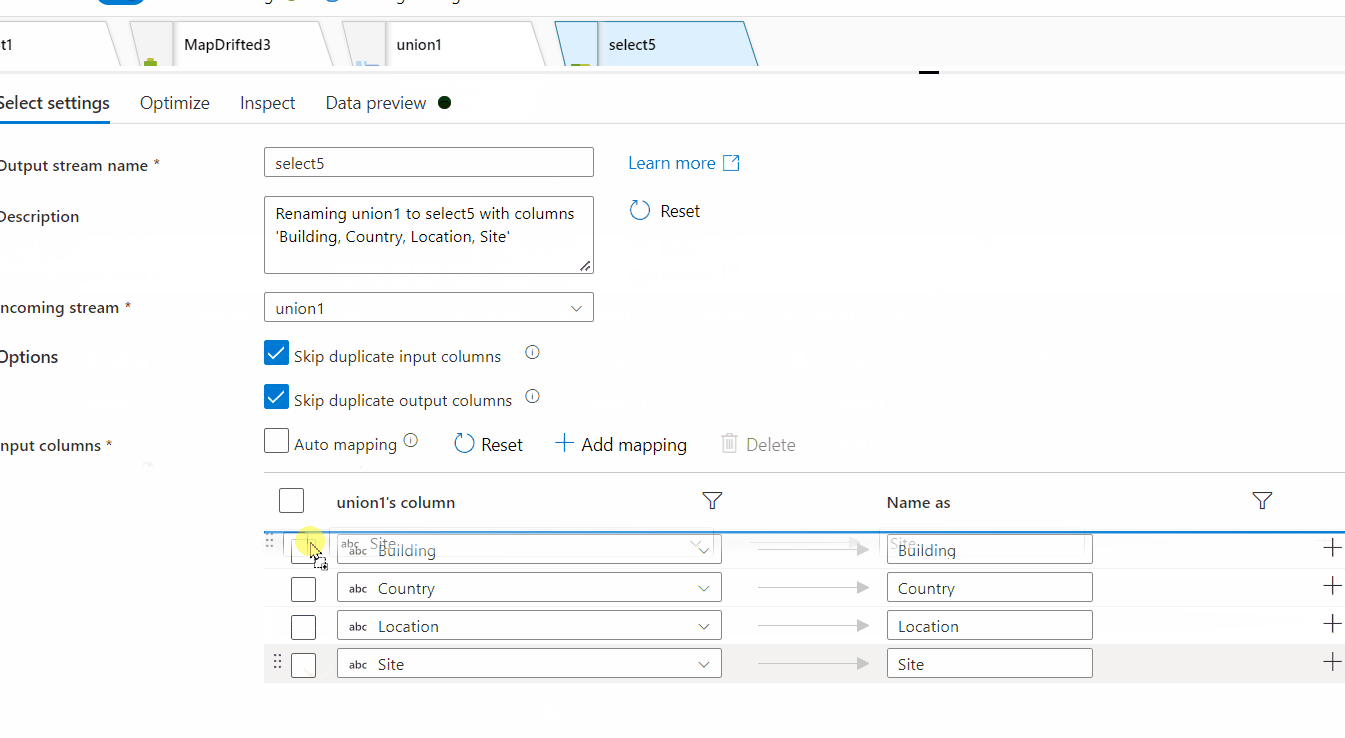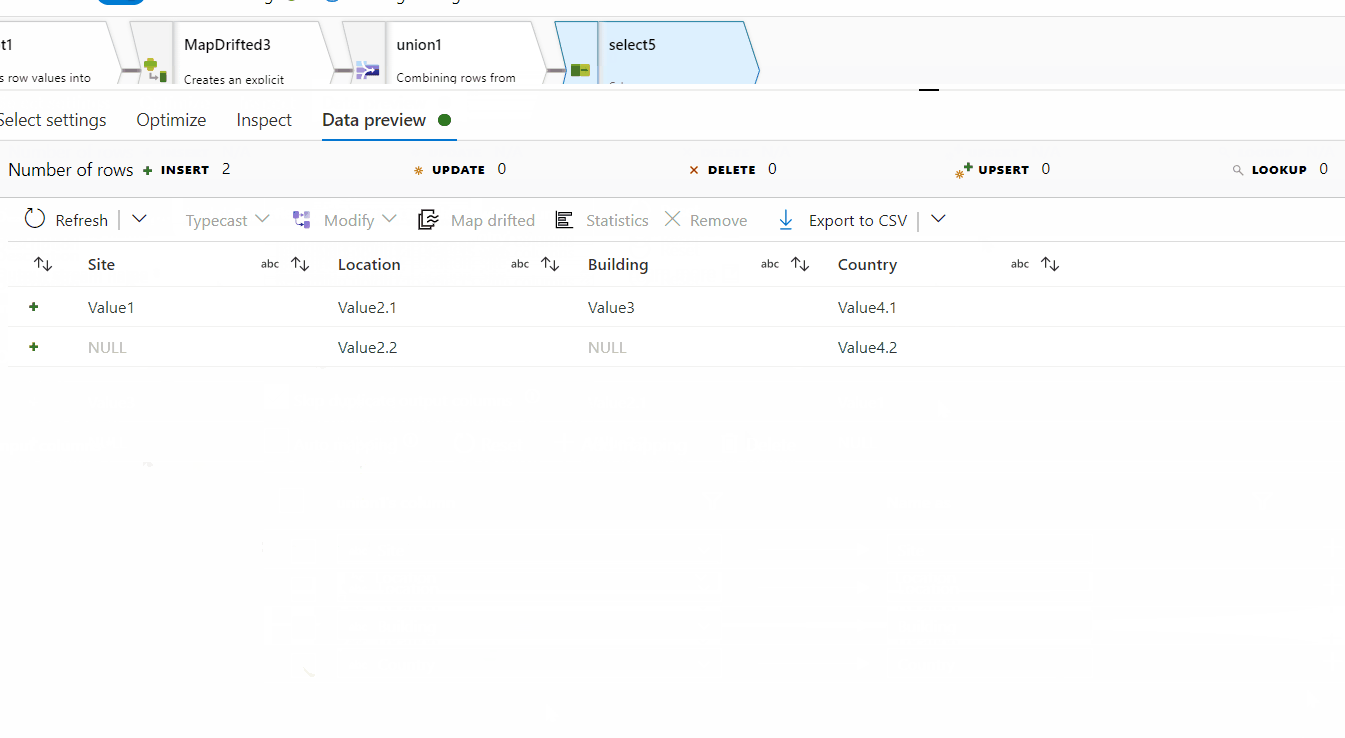
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.