How Node.js works
This unit explains how Node.js handles incoming tasks to the JavaScript runtime.
Types of tasks
JavaScript applications have two type of tasks:
- Synchronous tasks: These tasks happen in order. They aren't dependent on another resource to complete. Examples are mathematical operations or string manipulation.
- Asynchronous: These tasks might not complete immediately because they're dependent on other resources. Examples are network requests or file system operations.
Because you want your program to run as fast as possible, you want the JavaScript engine to be able to continue working while it waits for a response from an asynchronous operation. In order to do that, it adds the asynchronous task to a task queue and continues working on the next task.
Manage task queue with event loop
Node.js uses the JavaScript engine's event-driven architecture to process asynchronous requests. The following diagram illustrates how the V8 event loop works, at a high level:
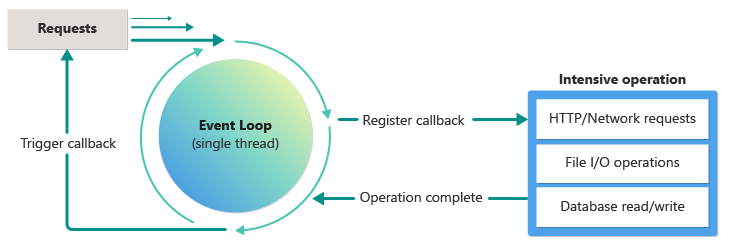
An asynchronous task, denoted by appropriate syntax (shown below), is added to the event loop. The task includes the work to be done and a callback function to receive the results. When the intensive operation completes, the callback function is triggered with the results.
Synchronous operations versus asynchronous operations
The Node.js APIs provide for both asynchronous and synchronous operations for some of the same operations such as file operations. While generally you should always think asynchronous-first, there are times when you might use synchronous operations.
An example is when a command line interface (CLI) reads a file and then immediately uses the data in the file. In this case, you can use the synchronous version of the file operation because there's no other system or person waiting to use the application.
However, if you're building a web server, you should always use the asynchronous version of the file operation in order to not block the single thread's execution ability to process other user requests.
In your work as a developer at TailWind Traders, you'll need to understand the difference between synchronous and asynchronous operations and when to use each.
Performance through asynchronous operations
Node.js takes advantage of the unique event-driven nature of JavaScript that makes composing server tasks fast and high-performing. JavaScript, when used correctly with asynchronous techniques, can produce the same performance results as low-level languages like C because of performance boosts made possible by the V8 engine.
The asynchronous techniques come in 3 styles, which you need to be able to recognize in your work:
- Async/await (recommended): The newest asynchronous technique that uses the
asyncandawaitkeywords to receive the results of an asynchronous operation. Async/await is used across many programming languages. Generally, new projects with newer dependencies will use this style of asynchronous code. - Callbacks: The original asynchronous technique that uses a callback function to receive the results of an asynchronous operation. You'll see this in older code bases and in older Node.js APIs.
- Promises: A newer asynchronous technique that uses a promise object to receive the results of an asynchronous operation. You'll see this in newer code bases and in newer Node.js APIs. You might have to write promise-based code in your work to wrap older APIs that won't be updated. By using promises for this wrapping, you allow the code to be used in a larger range of Node.js versioned projects than in the newer async/await style of code.
Async/await
Async/await is a newest way to handle asynchronous programming. Async/await is syntactic sugar on top of promises and makes asynchronous code look more like synchronous code. It is also easier to read and maintain.
The same example using async/await looks like this:
// async/await asynchronous example
const fs = require('fs').promises;
const filePath = './file.txt';
// `async` before the parent function
async function readFileAsync() {
try {
// `await` before the async method
const data = await fs.readFile(filePath, 'utf-8');
console.log(data);
console.log('Done!');
} catch (error) {
console.log('An error occurred...: ', error);
}
}
readFileAsync()
.then(() => {
console.log('Success!');
})
.catch((error) => {
console.log('An error occurred...: ', error);
});
When async/await was released in ES2017, the keywords could only be used in functions with the top-level function being a promise. While the promise didn't have to have then and catch sections, it was still required to have promise syntax to run.
An async function always returns a promise, even if it doesn't have an await call inside of it. The promise will resolve with the value returned by the function. If the function throws an error, the promise will be rejected with the thrown value.
Promises
Because nested callbacks can be difficult to read and manage, Node.js added support for promises. A promise is an object that represents the eventual completion (or failure) of an asynchronous operation.
A promise function has the format of:
// Create a basic promise function
function promiseFunction() {
return new Promise((resolve, reject) => {
// do something
if (error) {
// indicate success
reject(error);
} else {
// indicate error
resolve(data);
}
});
}
// Call a basic promise function
promiseFunction()
.then((data) => {
// handle success
})
.catch((error) => {
// handle error
});
The then method is called when the promise is fulfilled and the catch method is called when the promise is rejected.
To read a file asynchronously with promises, the code is:
// promises asynchronous example
const fs = require('fs').promises;
const filePath = './file.txt';
// request to read a file
fs.readFile(filePath, 'utf-8')
.then((data) => {
console.log(data);
console.log('Done!');
})
.catch((error) => {
console.log('An error occurred...: ', error);
});
console.log(`I'm the last line of the file!`);
Top-level async/await
The most recent versions of Node.js added top-level async/await for ES6 modules. You need to add a property named type in the package.json with a value of module to use this feature.
{
"type": "module"
}
Then you can use the await keyword at the top level of your code
// top-level async/await asynchronous example
const fs = require('fs').promises;
const filePath = './file.txt';
// `async` before the parent function
try {
// `await` before the async method
const data = await fs.readFile(filePath, 'utf-8');
console.log(data);
console.log('Done!');
} catch (error) {
console.log('An error occurred...: ', error);
}
console.log("I'm the last line of the file!");
Callbacks
When Node.js was originally released, asynchronous programming was handled by using callback functions. Callbacks are functions that are passed as arguments to other functions. When the task is complete, the callback function is called.
The order of parameters of the function is important. The callback function is the last parameter of the function.
// Callback function is the last parameter
function(param1, param2, paramN, callback)
The function name in the code you maintain might not be called callback. It could be called cb or done or next. The name of the function isn't important, but the order of the parameters is important.
Notice there's no syntactic indication that the function is asynchronous. You have to know that the function is asynchronous by reading the documentation or continuing to read through the code.
Callback example with named callback function
The following code separates the async function from the callback. This is easy to read and understand and allows you to reuse the callback for other async functions.
// callback asynchronous example
// file system module from Node.js
const fs = require('fs');
// relative path to file
const filePath = './file.txt';
// callback
const callback = (error, data) => {
if (error) {
console.log('An error occurred...: ', error);
} else {
console.log(data); // Hi, developers!
console.log('Done!');
}
};
// async request to read a file
//
// parameter 1: filePath
// parameter 2: encoding of utf-8
// parmeter 3: callback function
fs.readFile(filePath, 'utf-8', callback);
console.log("I'm the last line of the file!");
The correct result is:
I'm the last line of the file!
Hi, developers!
Done!
First, the asynchronous function fs.readFile is started and goes into the event loop. Then, the code execution continues to the next code line, which is the last console.log. After the file is read, the callback function is called and the two console.log statements are executed.
Callback example with anonymous function
The following example uses an anonymous callback function, which means the function doesn't have a name and can't be reused by other anonymous functions.
// callback asynchronous example
// file system module from Node.js
const fs = require('fs');
// relative path to file
const filePath = './file.txt';
// async request to read a file
//
// parameter 1: filePath
// parameter 2: encoding of utf-8
// parmeter 3: callback function () => {}
fs.readFile(filePath, 'utf-8', (error, data) => {
if (error) {
console.log('An error occurred...: ', error);
} else {
console.log(data); // Hi, developers!
console.log('Done!');
}
});
console.log("I'm the last line of the file!");
The correct result is:
I'm the last line of the file!
Hi, developers!
Done!
When the code is executed, the asynchronous function fs.readFile is started and goes into the event loop. Next the execution continues to the following code line, which is the last console.log. When the file is read, the callback function is called and the two console.log statements are executed.
Nested callbacks
Because you might need to call a subsequent async callback and then another, the callback code might become nested. This is called callback hell and is difficult to read and maintain.
// nested callback example
// file system module from Node.js
const fs = require('fs');
fs.readFile(param1, param2, (error, data) => {
if (!error) {
fs.writeFile(paramsWrite, (error, data) => {
if (!error) {
fs.readFile(paramsRead, (error, data) => {
if (!error) {
// do something
}
});
}
});
}
});
Synchronous APIs
Node.js also has a set of synchronous APIs. These APIs block the execution of the program until the task is complete. Synchronous APIs are useful when you want to read a file and then immediately use the data in the file.
Synchronous (blocking) functions in Node.js use the naming convention of functionSync. For example, the asynchronous readFile API has a synchronous counterpart named readFileSync. It's important to uphold this standard in your own projects so your code is easy to read and understand.
// synchronous example
const fs = require('fs');
const filePath = './file.txt';
try {
// request to read a file
const data = fs.readFileSync(filePath, 'utf-8');
console.log(data);
console.log('Done!');
} catch (error) {
console.log('An error occurred...: ', error);
}
As a new developer at TailWind Traders, you might be asked to modify any type of Node.js code. It's important to understand the difference between synchronous and asynchronous APIs, and the different syntaxes for asynchronous code.