Transform data from an SAP ODP source using the SAP CDC connector in Azure Data Factory or Azure Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use mapping data flow to transform data from an SAP ODP source using the SAP CDC connector. To learn more, read the introductory article for Azure Data Factory or Azure Synapse Analytics. For an introduction to transforming data with Azure Data Factory and Azure Synapse analytics, read mapping data flow or the tutorial on mapping data flow.
Tip
To learn the overall support on SAP data integration scenario, see SAP data integration using Azure Data Factory whitepaper with detailed introduction on each SAP connector, comparsion and guidance.
Supported capabilities
This SAP CDC connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Mapping data flow (source/-) | ①, ② |
① Azure integration runtime ② Self-hosted integration runtime
This SAP CDC connector uses the SAP ODP framework to extract data from SAP source systems. For an introduction to the architecture of the solution, read Introduction and architecture to SAP change data capture (CDC) in our SAP knowledge center.
The SAP ODP framework is contained in all up-to-date SAP NetWeaver based systems, including SAP ECC, SAP S/4HANA, SAP BW, SAP BW/4HANA, SAP LT Replication Server (SLT). For prerequisites and minimum required releases, see Prerequisites and configuration.
The SAP CDC connector supports basic authentication or Secure Network Communications (SNC), if SNC is configured.
Current limitations
Here are current limitations of the SAP CDC connector in Data Factory:
- You can't reset or delete ODQ subscriptions in Data Factory (use transaction ODQMON in the connected SAP system for this purpose).
- You can't use SAP hierarchies with the solution.
Prerequisites
To use this SAP CDC connector, refer to Prerequisites and setup for the SAP CDC connector.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service for the SAP CDC connector using UI
Follow the steps described in Prepare the SAP CDC linked service to create a linked service for the SAP CDC connector in the Azure portal UI.
Dataset properties
To prepare an SAP CDC dataset, follow Prepare the SAP CDC source dataset.
Transform data with the SAP CDC connector
The raw SAP ODP change feed is difficult to interpret and updating it correctly to a sink can be a challenge. For example, technical attributes associated with each row (like ODQ_CHANGEMODE) have to be understood to apply the changes to the sink correctly. Also, an extract of change data from ODP can contain multiple changes to the same key (for example, the same sales order). It's therefore important to respect the order of changes, while at the same time optimizing performance by processing the changes in parallel. Moreover, managing a change data capture feed also requires keeping track of state, for example in order to provide built-in mechanisms for error recovery. Azure data factory mapping data flows take care of all such aspects. Therefore, SAP CDC connectivity is part of the mapping data flow experience. Thus, users can concentrate on the required transformation logic without having to bother with the technical details of data extraction.
To get started, create a pipeline with a mapping data flow.
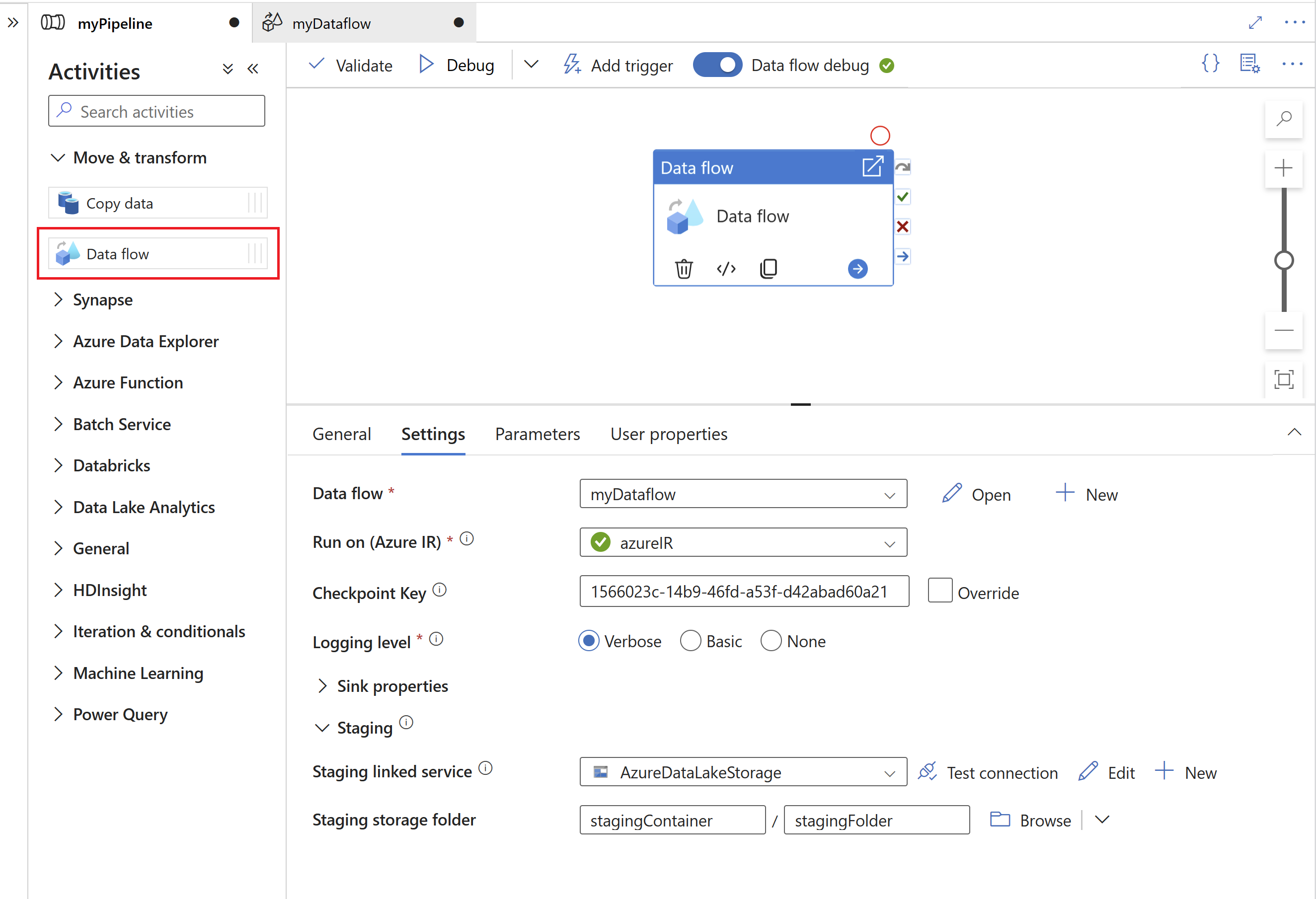
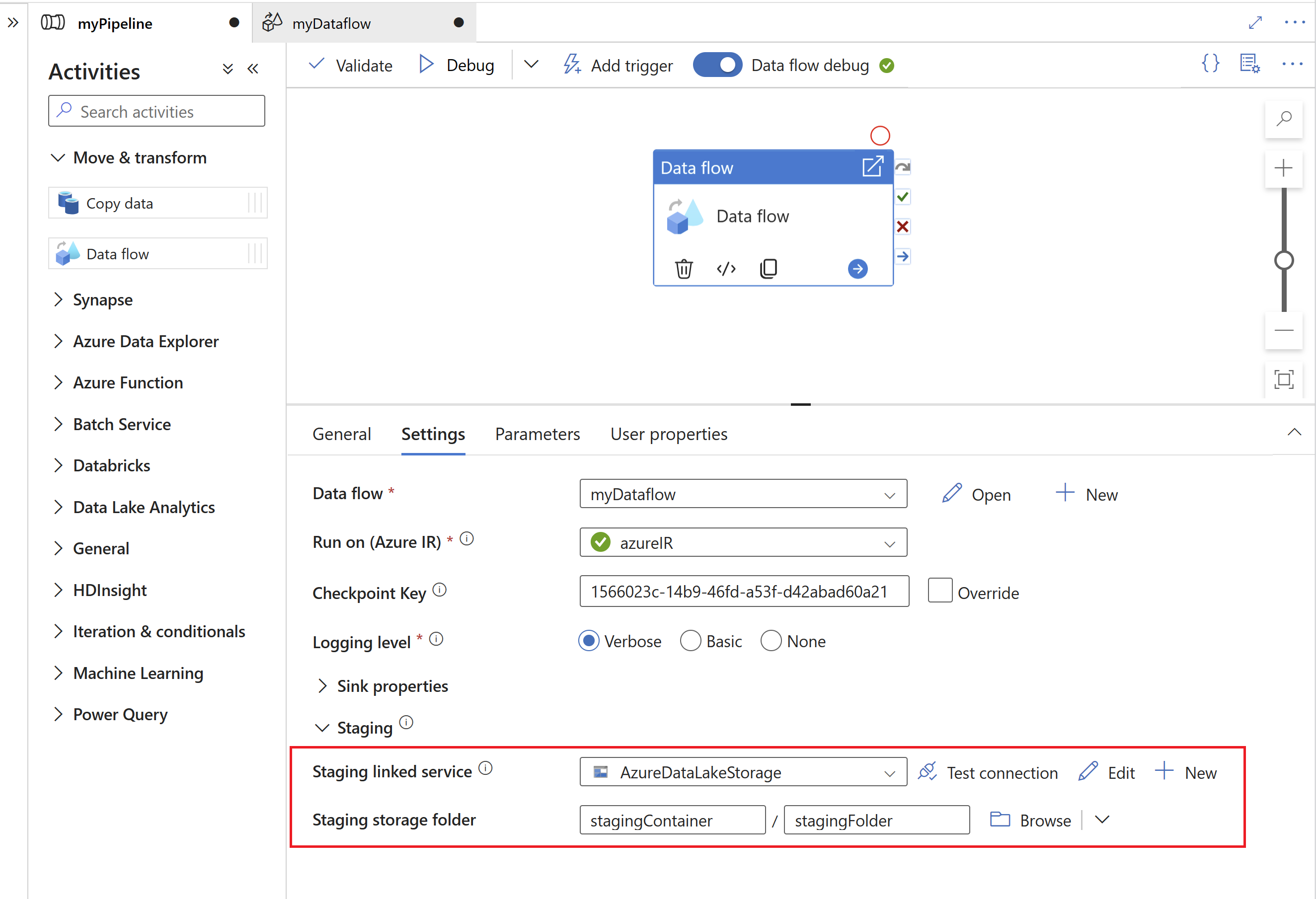
Next, specify a staging linked service and staging folder in Azure Data Lake Gen2, which serves as an intermediate storage for data extracted from SAP.
Note
- The staging linked service cannot use a self-hosted integration runtime.
- The staging folder should be considered an internal storage of the SAP CDC connector. For further optimizations of the SAP CDC runtime, implementation details, like the file format used for the staging data, might change. We therefore recommend not to use the staging folder for other purposes, e.g. as a source for other copy activities or mapping data flows.
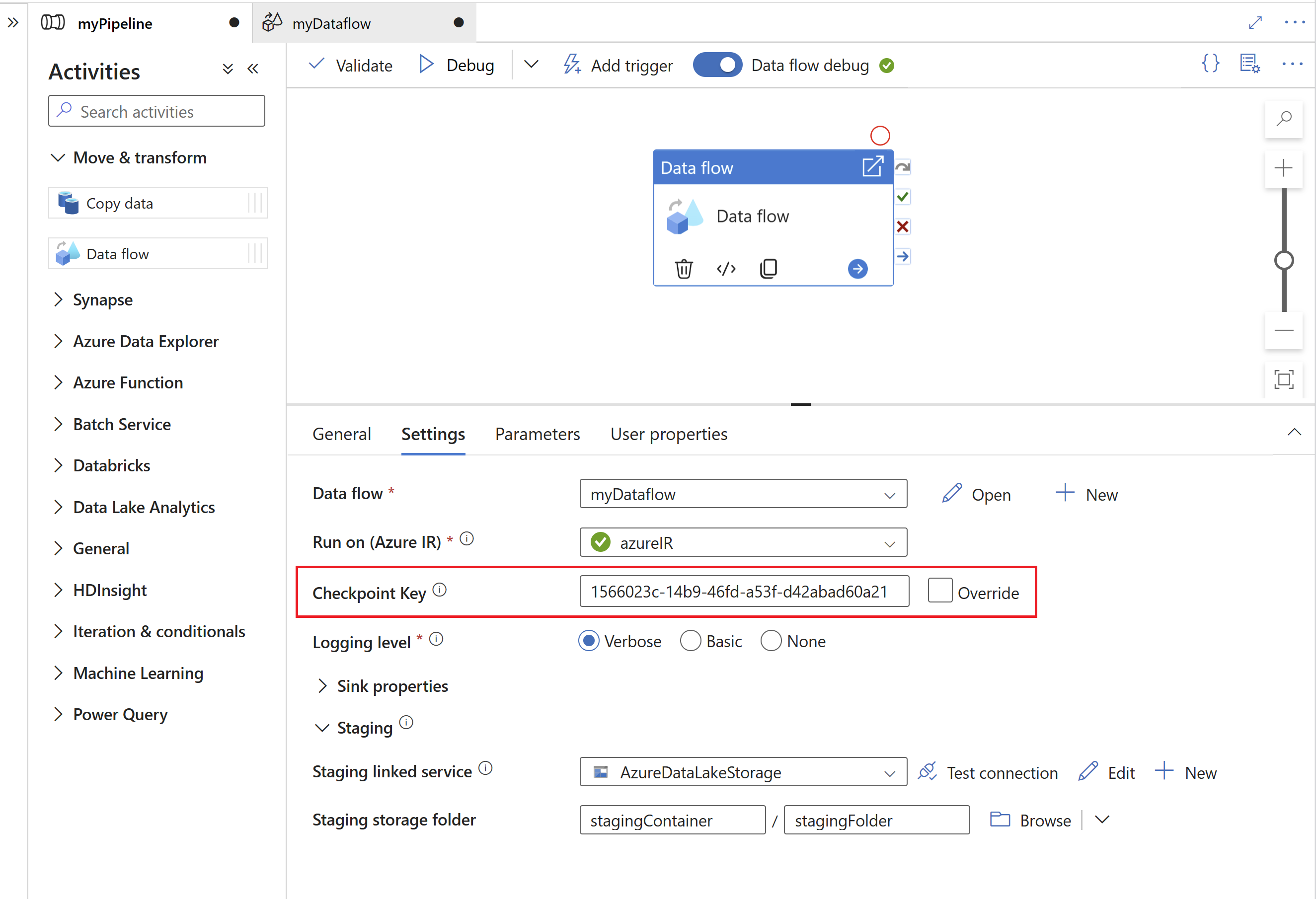
The Checkpoint Key is used by the SAP CDC runtime to store status information about the change data capture process. This, for example, allows SAP CDC mapping data flows to automatically recover from error situations, or know whether a change data capture process for a given data flow has already been established. It is therefore important to use a unique Checkpoint Key for each source. Otherwise status information of one source will be overwritten by another source.
Note
- To avoid conflicts, a unique id is generated as Checkpoint Key by default.
- When using parameters to leverage the same data flow for multiple sources, make sure to parametrize the Checkpoint Key with unique values per source.
- The Checkpoint Key property is not shown if the Run mode within the SAP CDC source is set to Full on every run (see next section), because in this case no change data capture process is established.
Parameterized checkpoint keys
Checkpoint keys are required to manage the status of change data capture processes. For efficient management, you can parameterize the checkpoint key to allow connections to different sources. Here's how you can implement a parameterized checkpoint key:
Create a global parameter to store the checkpoint key at the pipeline level to ensure consistency across executions:
"parameters": { "checkpointKey": { "type": "string", "defaultValue": "YourStaticCheckpointKey" } }Programmatically set the checkpoint key to invoke the pipeline with the desired value each time it runs. Here's an example of a REST call using the parameterized checkpoint key:
PUT https://management.azure.com/subscriptions/{subscriptionId}/resourceGroups/{resourceGroupName}/providers/Microsoft.DataFactory/factories/{factoryName}/pipelines/{pipelineName}?api-version=2018-06-01 Content-Type: application/json { "properties": { "activities": [ // Your activities here ], "parameters": { "checkpointKey": { "type": "String", "defaultValue": "YourStaticCheckpointKey" } } } }
For more detailed information refer to Advanced topics for the SAP CDC connector.
Mapping data flow properties
To create a mapping data flow using the SAP CDC connector as a source, complete the following steps:
In ADF Studio, go to the Data flows section of the Author hub, select the … button to drop down the Data flow actions menu, and select the New data flow item. Turn on debug mode by using the Data flow debug button in the top bar of data flow canvas.
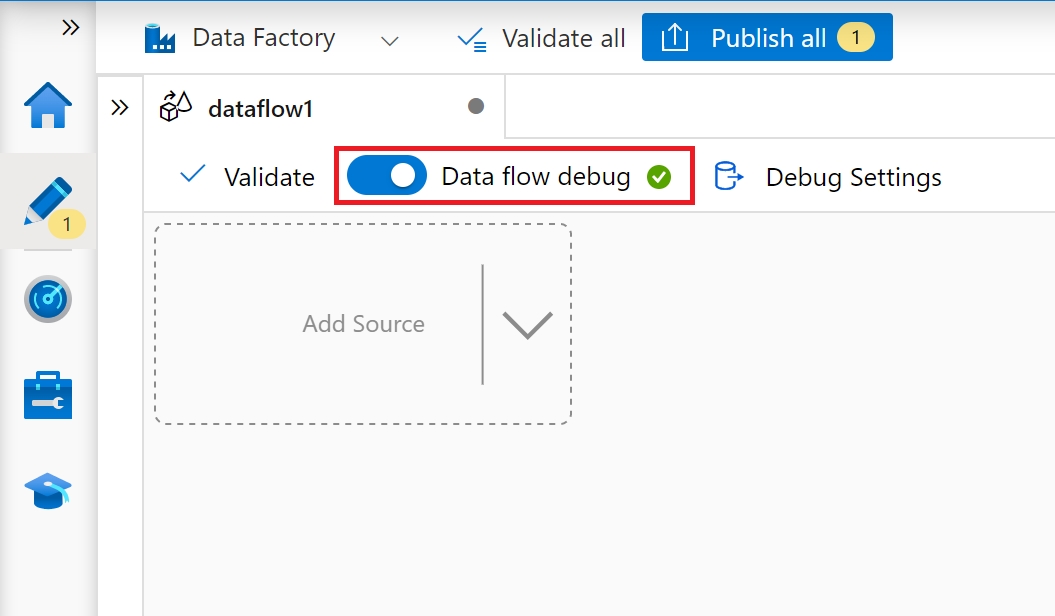
In the mapping data flow editor, select Add Source.
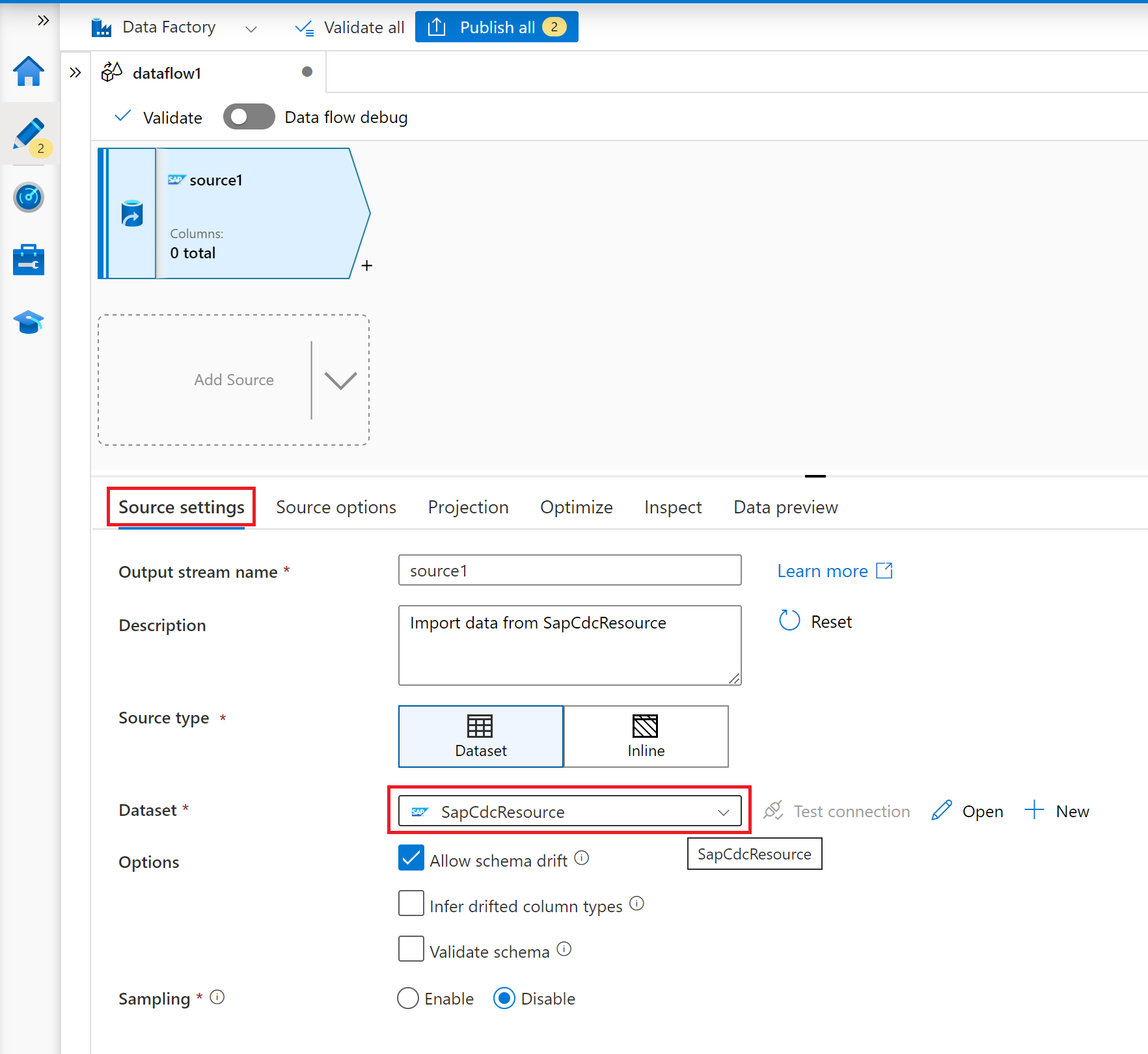
On the tab Source settings, select a prepared SAP CDC dataset or select the New button to create a new one. Alternatively, you can also select Inline in the Source type property and continue without defining an explicit dataset.
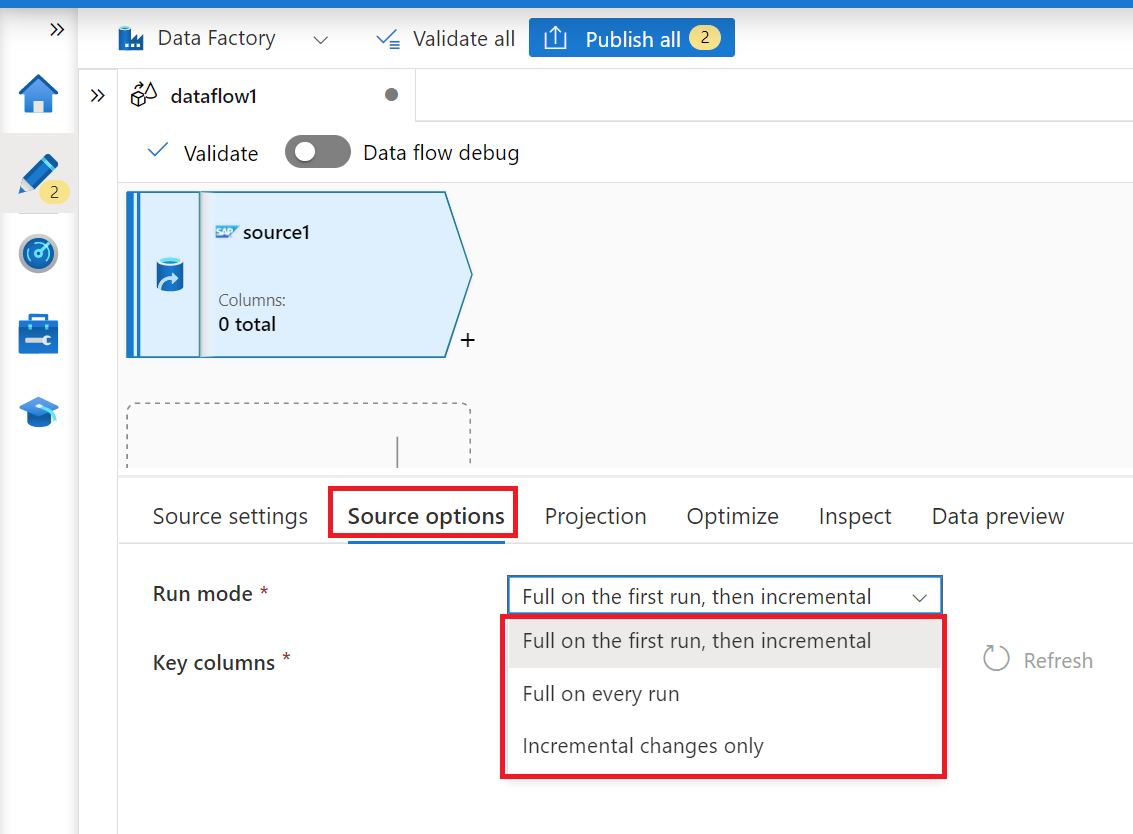
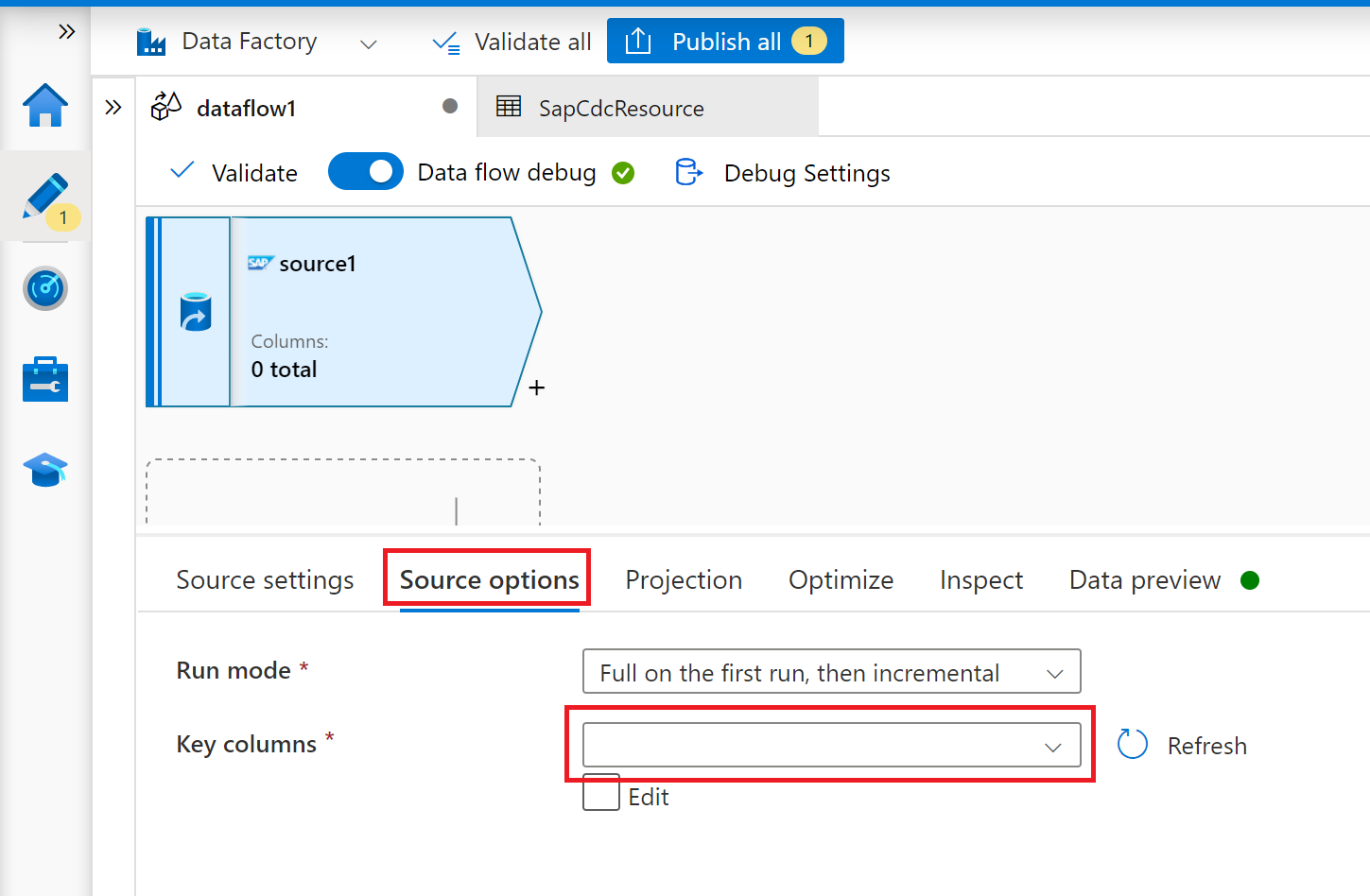
On the tab Source options, select the option Full on every run if you want to load full snapshots on every execution of your mapping data flow. Select Full on the first run, then incremental if you want to subscribe to a change feed from the SAP source system including an initial full data snapshot. In this case, the first run of your pipeline performs a delta initialization, which means it creates an ODP delta subscription in the source system and returns a current full data snapshot. Subsequent pipeline runs only return incremental changes since the preceding run. The option incremental changes only creates an ODP delta subscription without returning an initial full data snapshot in the first run. Again, subsequent runs return incremental changes since the preceding run only. Both incremental load options require to specify the keys of the ODP source object in the Key columns property.
For the tabs Projection, Optimize and Inspect, follow mapping data flow.
Optimizing performance of full or initial loads with source partitioning
If Run mode is set to Full on every run or Full on the first run, then incremental, the tab Optimize offers a selection and partitioning type called Source. This option allows you to specify multiple partition (that is, filter) conditions to chunk a large source data set into multiple smaller portions. For each partition, the SAP CDC connector triggers a separate extraction process in the SAP source system.
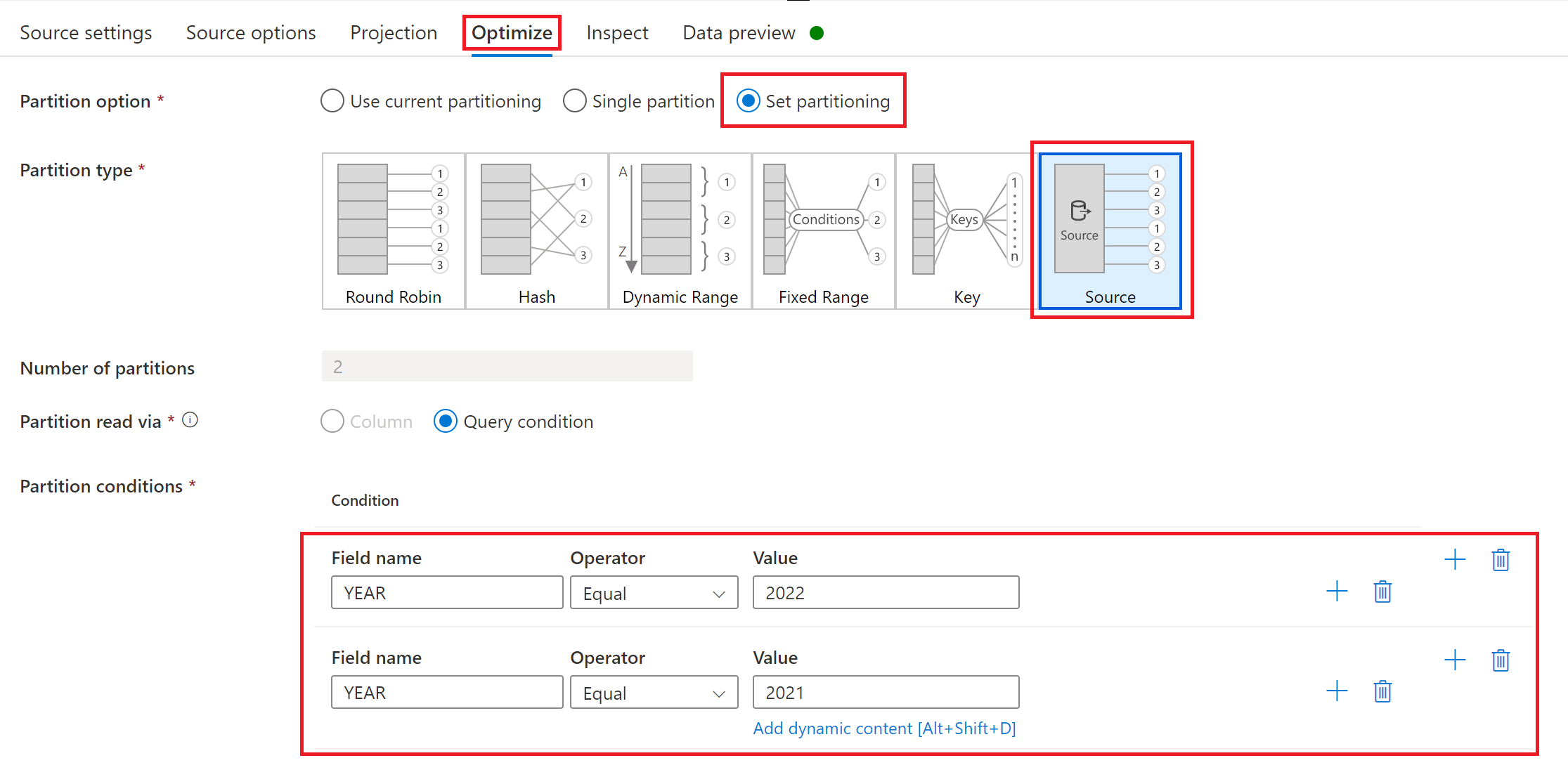
If partitions are equally sized, source partitioning can linearly increase the throughput of data extraction. To achieve such performance improvements, sufficient resources are required in the SAP source system, the virtual machine hosting the self-hosted integration runtime, and the Azure integration runtime.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for