Use Exploratory Data Analysis (EDA) to explore and understand your data
Every machine learning project requires a deep understanding of the data to understand whether the data is representative of the problem. A systematic approach to understanding the data should be undertaken to ensure project success. Every machine learning project demands a deep understanding of the data to be used to be sure it represents the problem.
Understanding of the data typically takes place during the Exploratory Data Analysis (EDA) phase. It is a complex part of an AI project where data cleansing takes place, and outliers are identified. In this phase, suitability of the data is assessed to inform hypothesis generation and experimentation. EDA is typically a creative process used to find answers to questions about the data.
EDA relates to using AI to analyze and structure data, aimed at better understanding the data and includes:
- Its distribution, outliers, and completeness
- Its relevance to solving a specific business problem using ML
- Does it contain PII data and will redaction or obfuscation be required
- How it can be used to generate synthetic data if necessary
Also as part of this phase data suitability is assessed for hypothesis generation and experimentation.
The following image illustrates the various phases, their respective complexity and roles during a typical machine learning project:
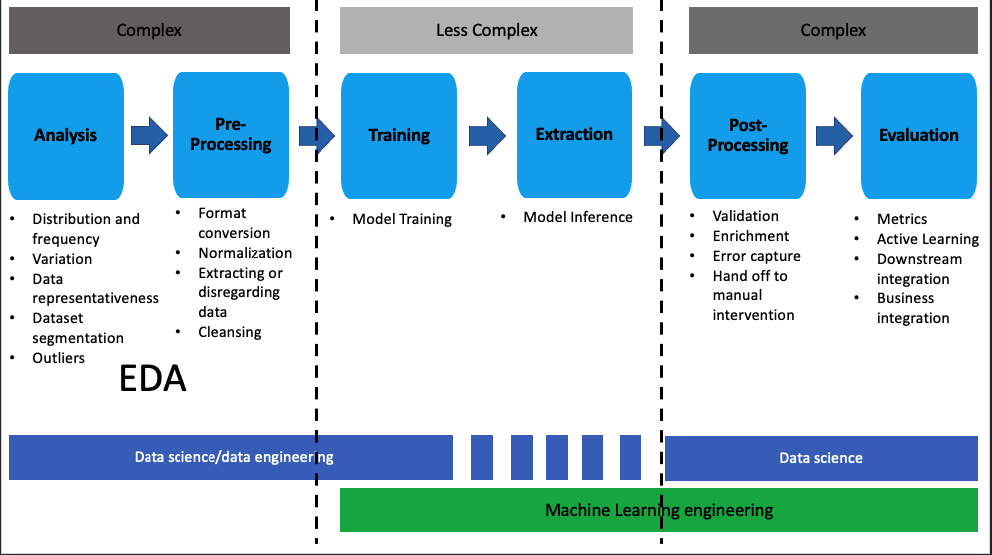
Hypothesis driven development and experiment tracking 🧪
Code written during EDA may not make it to production, but treating it as production code is a best practice. It provides an audit and represents the investment made to determine the correct ML solution as part of a hypothesis-driven development approach.
It allows teams to not only reproduce the experiments but also to learn from past lessons, saving time and associated development costs.
Data versioning
In an ML project it is vital to track the data that experiments are run on and models are trained on. Tracking this relationship or lineage between the ML solution and experiment ensures repeatability, improves interpretability, and is an engineering best practice.
During iterative labeling, data ingestion, and experimentation it is critical that experiments can be recreated. It can be for simple reasons, such as re-running demos, or for critical reasons like auditing for bias in a model, years after deployment. To replicate the creation of a given model, it is not enough to reuse the same hyperparameters, the same training data must be used as well. In some cases, it is where Feature Management Systems come in. In other cases, it may make more sense to implement data versioning in some other capacity (on its own, or with a Feature Management System).
ℹ️ Refer to the Data: Data Lineage section for more information nuanced to a Data Engineer/Governance role.
Basic implementation in Azure ML
A common pattern adopted in customer engagements follows these given guidelines:
- Data is stored in blob storage, organized by ingestion date
- Raw data is treated as immutable
- Azure ML Data assets are used as training data inputs
- All Data assets are tagged with date ranges related to their source.
- Different versions of Data assets point to different date folders.
With these guidelines in place, the guidance in the Azure ML Docs for Versioning and Tracking ML Datasets can be followed. The current docs reference the v1 SDK, but the concept translates to v2 as well.
Some useful resources for data registration and versioning:
| Resource | Description |
|---|---|
| Azure ML Python SDK v2 to train a symbol detection using P&ID synthetic dataset | This project provides a sample implementation of an AML workflow to train a symbol detection model. It includes a ‘data registration’ step that demonstrates registering a data asset for later use in AML, including stratified splitting techniques for consistent feature representation across the training and validation sets. |
Third-party tools
Third-party data versioning tools, such as DVC, also provide full data versioning and tracking with the overhead of using their tool set. They may work well for customers who are in a greenfield state, looking to build a robust MLOps pipeline. But it requires more work to integrate with existing data pipelines.
Considerations for small datasets
Relatively small datasets, a few hundred MB or less, that change slowly are candidates for versioning within the project repository via Git Large File Storage (LFS). The commit of the repo at the point of model training will thus also specify the version of the training data used. Advantages include simplicity of setup and cross compatibility with different environments, such as, local, Databricks, and Azure ML compute resources. The disadvantages include large repository size and the necessity of encoding the repository commit at which training occurs.
Drift
Data evolves over time and the key statistic values of data, used for training an ML Model, might undergo changes as compared to the real data used for prediction. It degrades the performance of a model over time. Periodic comparison and evaluation of both the datasets, training and inference data, is performed to find any drift in them. With enough historical data, this activity can be integrated into the Exploratory Data Analysis phase to understand expected drift characteristics.
Refer to the following page for a checklist on Data Drift questions to ask a customer
Refer to the following page for detailed overview of Data Drift and Adaption
Experiment tracking
When tracking experiments, the goal is to not only be able to formulate a hypothesis and track the results of the experiment, but to also be able to fully reproduce the experiment if necessary, whether during this project or in a future related project.
In order to be able to reproduce an experiment, below are details illustrating what needs to be tracked at a minimum:
- Code and scripts used for the experiment
- Environment configuration files (docker is a great way to reliably and easily reproduce an environment)
- Data versions used for training and evaluation
- HyperParameters and other parameters
- Evaluation metrics
- Model weights
- Visualizations and reports such as confusion matrices
Case studies
Here are some case studies that help illustrate how EDA is performed on real-world projects
Setting up a Development Environment
Refer to Experimentation in Azure ML for guidance on conducting experiments in Azure ML and best practices to set up the development environment.
Working with unstructured data
The Data Discovery solution for unstructured data aims to quickly provide structured views on your text, images and videos. All at scale using Synapse and unsupervised ML techniques that exploit state-of-the-art deep learning models.
The goal is to present this data to and facilitate discussion with a business user/data owner quickly via Power BI visualization. Then the customer and team can decide the next best action with the data, identify outliers, or generate a training data set for a supervised model.
Another goal is to help simplify and accelerate the complex Exploratory Data Analysis phase of the project by democratizing common data science functions.It also accelerate your project so that you can focus more on the business problem you are trying to solve.
Working with structured data
- Forms: for working with forms, refer to the auto-labeling section of the forms knowledge extraction repo
- Azure Custom Translator: for analyzing unstructured data and translation memory files for translation using Custom Translator
Good places to start for EDA
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for