GenAI gateway reference architecture using APIM
This section presents the reference architectures of a GenAI gateway for an enterprise that needs to access both Azure OpenAI (AOAI) resources and the custom LLM deployments on their own premises. There could be many possible ways to design a GenAI gateway using a combination of various Azure services. This section demonstrates using Azure API Management (APIM) Service as the main component to build the necessary features for a GenAI gateway solution.
Reference Architectures using Azure API Management
The Azure API Management(APIM) Landing Zone accelerator provides a comprehensive solution to deploy a GenAI gateway using Azure API Management with best practices around security and operational excellence. GenAI gateway using APIM is one of the reference scenario implemented in this accelerator.
Cloud-based GenAI Gateway
This design shows how to use APIM to create a GenAI gateway. It smoothly integrates with AOAI services in the cloud and any on-premises custom LLMs that are deployed and available as REST endpoints.
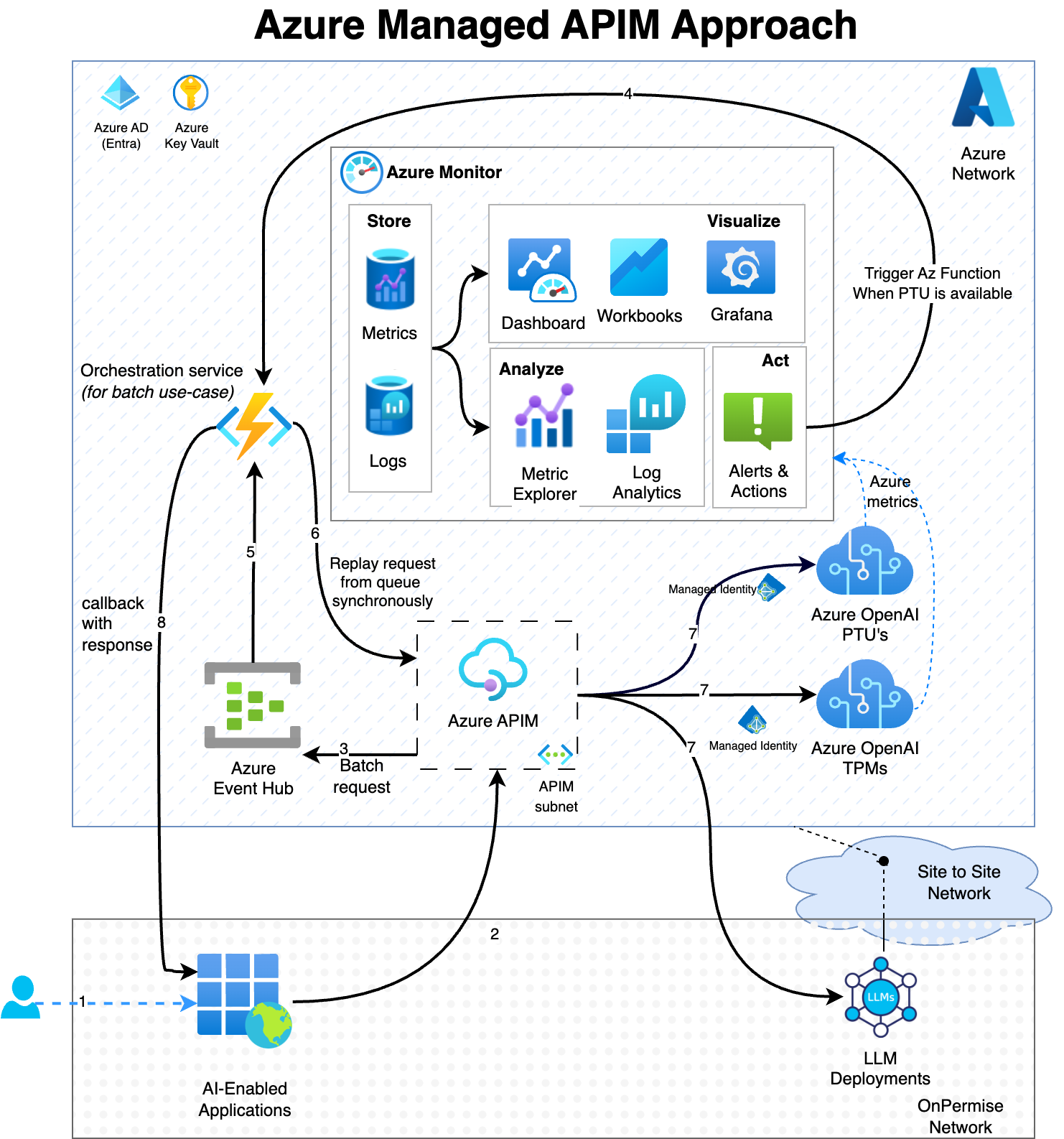 |
|---|
| Figure 1: Cloud-Based GenAI using APIM |
APIM products and subscription features can enable various Generative AI scenarios in an enterprise. Different products can offer the following different functionalities:
- Creating content.
- Producing embeddings.
- Searching.
Subscriptions allow different teams to access these functionalities.
Key considerations
One important thing to keep in mind with this method is that the gateway component is on the cloud. On the cloud means that the Azure network has to process every request before any of the gateway policies apply. This processing can impact the total latency when other services are running on-premises. Besides that, if there are LLM models deployed on-premises, then the right network setup has to be there to enable inbound connection from the gateway to on-premises network.
On-premises GenAI Gateway using APIM Self-Hosted Gateways
Many enterprises would like to use existing in-house capabilities while also having network constraints to allow inbound connection from Azure to their internal network.
Azure API Management (APIM) self-hosted gateways can be used to create a GenAI gateway that seamlessly integrates with AOAI services and on-premises applications. The self-hosted APIM gateway acts as a crucial component, bridging AOAI services with the enterprise's internal network.
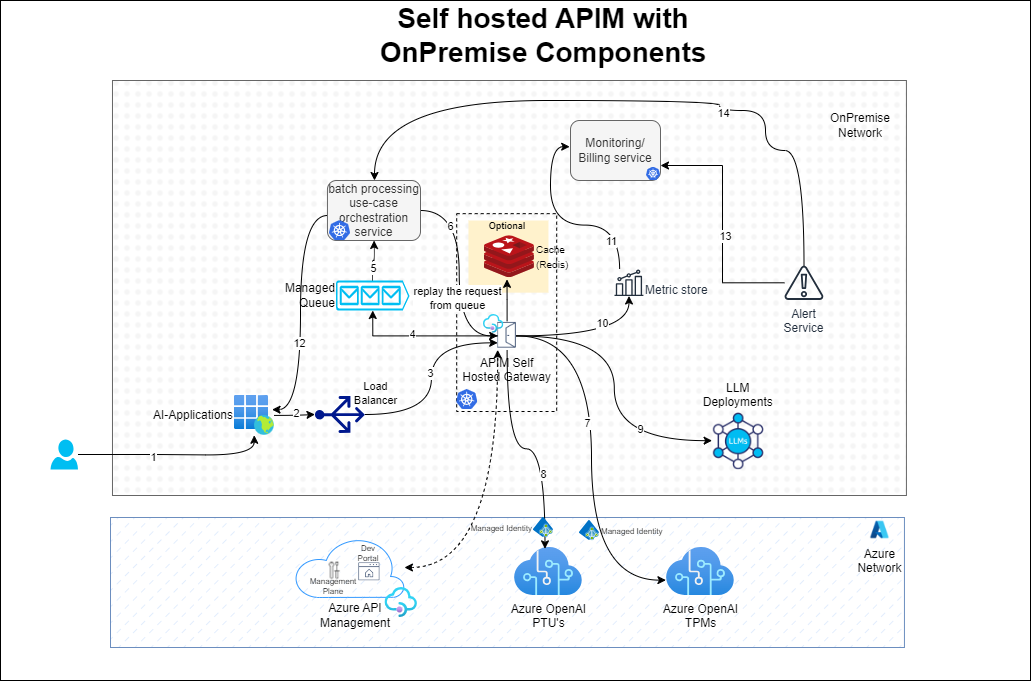 |
|---|
| Figure 2: On-premises Self-Hosted APIM Gateway |
With APIM self-hosted gateway, the requests from the enterprise's internal network stay within the network unless they reach out to the AOAI resource. This approach enables all the features of the gateway inside the network and eliminates the need for inbound connection from the cloud.
The gateway can use any existing on-premises deployment of queue for scheduling requests and connect with enterprise-wide monitoring system. This queue would enable gateway logs and metrics to be combined with existing consumer application logs and metrics.
Key considerations
With this approach, the organization is responsible for deploying and maintaining the self-hosted gateway. This maintenance means scaling the gateway component horizontally to handle the load and keeping it elastic to handle surges in requests. If metrics and logs are sent to custom metrics store, each organization will have to build their own monitoring and alerting solution to support the following actions:
- Dynamic scheduling of request
- Making reports for charge back.
Reference Design for Key Individual Capabilities
The selection below describes the reference design for key GenAI gateway capabilities as discussed in this document using Azure API Management (APIM) service as a foundational technology.
1. Scalability
The Premium tier of APIM provides the capability to extend a single APIM instance across multiple Azure regions.
1.1 Supporting High Consumer Concurrency
A single Premium Tier APIM service instance is equipped to do the following actions:
- Support multi-region.
- Support Multi-Azure AOAI account configurations.
- Facilitate efficient traffic routing across various regions.
- Ensure support for high consumer concurrency.
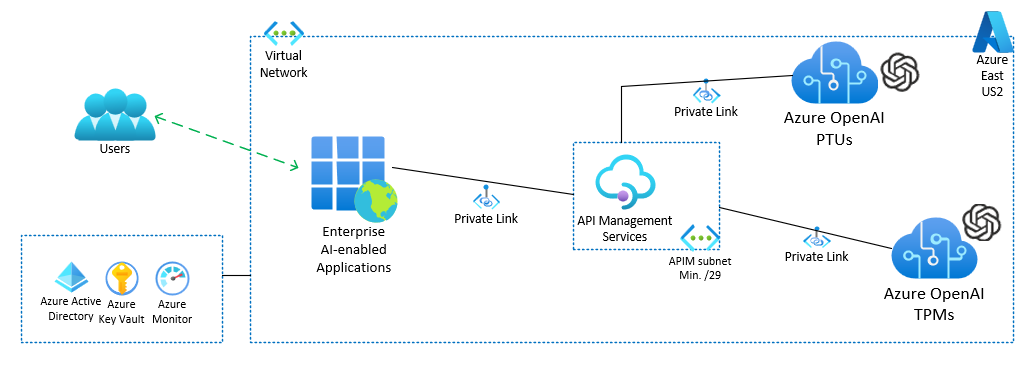
The below diagram illustrates this setup, where APIM efficiently routes traffic to multiple AOAI instances, deployed in distinct regions. This capability enhances the performance and availability of the service by using geographical distribution of resources.
More info about multiple regions.
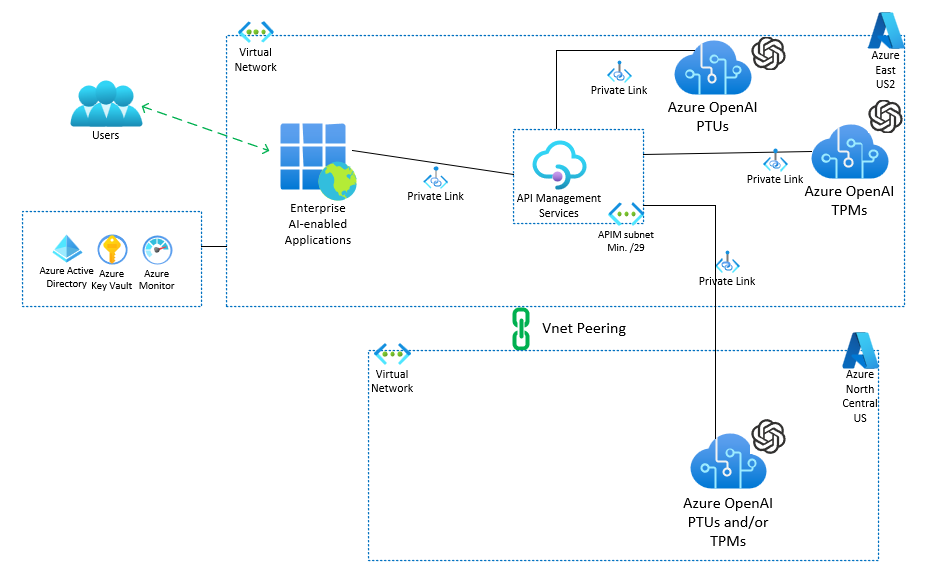 |
|---|
| Figure 1: Handling High Consumer Concurrency |
Scenario: Managing spikes with Provisioned Throughput Units (PTUs) and Pay As You Go (PAYG) endpoints
This diagram shows the implementation of spillover strategy. This strategy involves initially routing traffic to PTU-enabled deployments. In cases where PTU limits are reached, the overflow is redirected to TPM (Tokens Per Minute)-enabled Azure OpenAI (AOAI) endpoints. This redirection ensures all requests are processed.
More information Scaling (Single Region).
 |
|---|
| Figure 2: Managing Spikes on PTUs with PAYG |
1.2 Load Balancing across Multiple AOAI Instances
A simple round robin load balancing can be configured using APIM. An APIM policy, which distributes traffic across several AOAI instances can be configured to achieve scale. Refer to this article for a detailed implementation of round robin load-balancing in APIM. Also, a random load-balancing approach can be found here.
2. Performance Efficiency
APIM policies can be used to rate limit based on RPM and TPM.
2.1 Quota Management for Consumers
Different rate limit values can be set for different use cases based on their subscription IDs. In the below policy snippet, rate limiting is done based on both RPM and TPM. Throttling is expected when either of these limits is crossed.
2.1.1 Rate Limit based on TPM consumption
Throttling can be implemented based on token consumption as well. This
code snippet shows the XML policy defined in APIM to set up a rate limit. The limit is
based on the number of calls per minute (TPM: Transactions Per Minute).
The value used for counter-key concatenates the subscription ID with "tpm" to
uniquely identify the limit. The increment-condition value increments the
count only if the HTTP response status code falls within the 200 to 399
range, and it tracks the usage by extracting the total tokens from the
response body. Additionally, it specifies header names for remaining TPM
and total TPM counts to be included in the response.
<!-- Rate limit on TPM -->
<rate-limit-by-key calls="500" renewal-period="60"
counter-key="@(String.Concat(context.Subscription.Id,\"tpm\"))"
increment-condition="@(context.Response.StatusCode >= 200 && context.Response.StatusCode < 400)"
increment-count="@(context.Response.Body.As<JObject>(true).SelectToken(\"usage.total_tokens\").ToObject<int>())"
remaining-calls-header-name=\"remainingTPM\" total-calls-header-name=\"totalTPM\" \>
To mitigate the AOAI quota limits, Retries become an essential tool to ensure service availability. The request throttling happens for a window of a few seconds or minutes. A retry strategy with exponential back-offs can be implemented at the Gateway layer. This strategy will ensure that the request is served for the consumers.
Refer to this link for Sample APIM Policies for AOAI
3. Security and data integrity
Managed identities are used to protect PII.
3.1 Authentication
APIM with AOAI provides several options for authentication including the following:
- API keys.
- Managed identities.
- Service principal.
The managed identity approach can be used to authenticate between APIM and managed identity supported backend Azure services
The managed identity can be given the right access, "Azure AI Service User" for the AOAI instance as mentioned in How to configure OpenAI. APIM then transparently authenticates to the backend, that is, AOAI.
3.2 PII and data masking
This diagram depicts how PII detection and data masking are enabled using GenAI Gateway. Upon receiving a data request, the information is transmitted to an Azure function for PII detection. This function has the capability to employ a service like (PII) detection in Azure AI Language, a pre-packaged solution like Microsoft Presidio, or a custom machine learning model to identify PII data. The detected information is then utilized to mask the request. The masked data is forwarded to Azure APIM, which then sends it to AOAI.
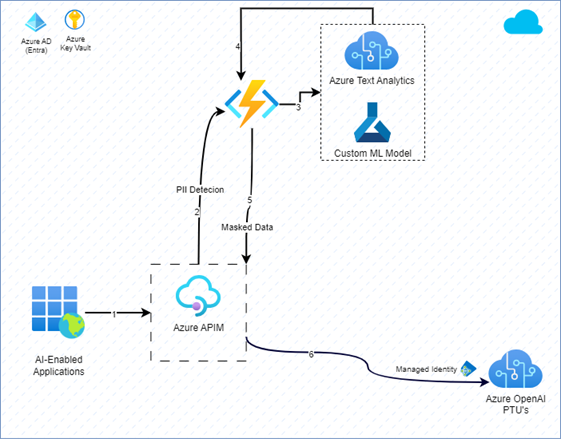 |
|---|
| Figure 3: PII and Data Masking |
3.3 Data Sovereignty
This diagram depicts how data is restricted to customer-specific regions using GenAI Gateway. Here we have two regions, and each region hosts AI-Enabled applications, APIM and AOAI. Traffic is routed to region-specific APIM and OpenAI using Traffic manager. APIM helps with routing requests to the region-specific Azure OpenAI instance.
To learn more about APIM multi-regional deployment, refer to Deploy Azure API management to multiple Azure regions.
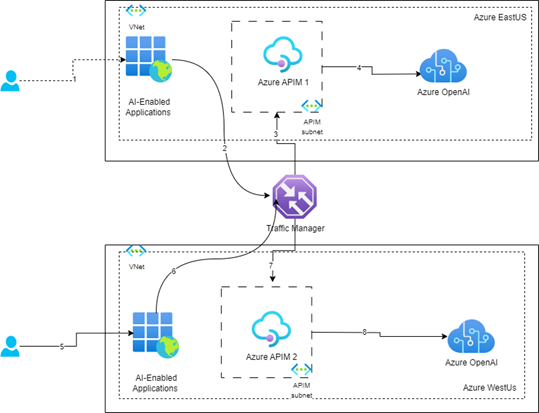 |
|---|
| Figure 4: Data Sovereignty via Multiple APIMs |
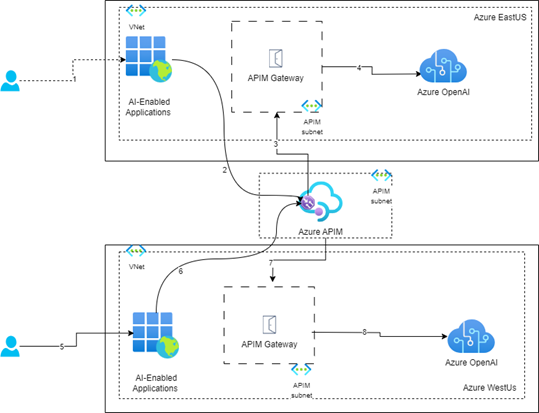 |
|---|
| Figure 5: Data Sovereignty via multi-instance APIM |
4. Operational Excellence
4.1 Monitoring and Observability
Azure Monitor Integration
By using the native integration of APIM with Azure Monitor, the requests, and responses (payload) and APIM metrics can be logged into Azure Monitor. In addition, Azure Monitor can be used to collect and log metrics from other Azure services like AOAI making it the default choice for monitoring and observability.
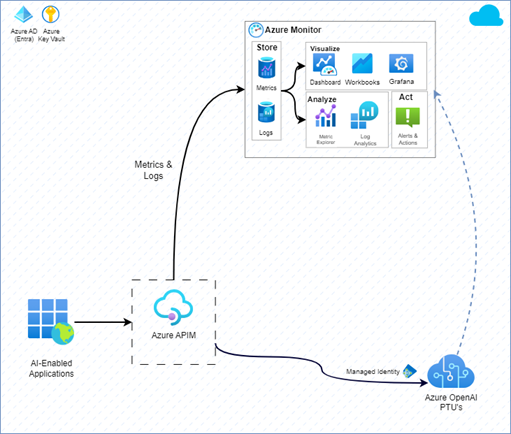 |
|---|
| Figure 6: Monitoring using Azure Monitor |
When configuring, Azure Monitor provided a low-code/no-code way of generating insights, this approach has the following possible limitations:
Azure monitor may introduce latency ranging from 30 sec to 15 mins, which is an important consideration for consumers who need this information for real-time monitoring and decision-making processes.
Employing Azure Monitor for capturing request/response payload requires configuring the desired sampling rate in APIM. A high sampling rate has potential impact on throughout of APIM and increased latency for consumers.
When dealing with large payloads in requests or responses, the complete data may not be logged since APIM imposes a log size limitation. Azure Monitor imposes a log size limit of 32KB (9182 bytes). If the combined size of all logged headers and payloads exceeds this limit, some logs may not be recorded.
Monitoring via Custom Events
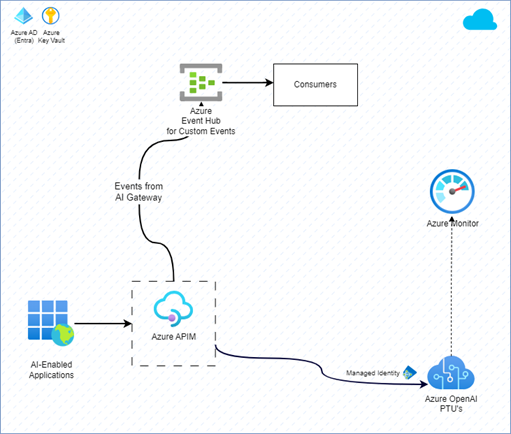 |
|---|
| Figure 7: Monitoring using Custom Events |
In this approach, requests, responses and other data from Azure API Management (APIM) can be logged as custom events to a messaging system like Event Hubs. The event stream from Event Hubs can be consumed by other services to perform various operations like data aggregation in near-real-time fashion, generating alerts or performing other actions.
While this approach offers more near real-time experience, it requires writing custom aggregation services.
5. Cost Optimization
5.1 Tracking Consumption
Non-Streaming endpoints
A Product in APIM can have multiple subscriptions. Metrics at a product level can be tracked and aggregated for consumption at consumer level. To measure the consumption, the response body of the payload that has the total token count can be logged to Azure Event Hubs.
These techniques have been discussed in maximizing PTU and Monitoring sections.
Streaming endpoints
There's no built-in option for tracking consumption within streaming endpoints with APIM as of now. However, there are alternatives.
- One alternative has been discussed here](https://medium.com/microsoftazure/when-invoking-apis-hosted-by-azure-api-management-configured-azure-openai-service-as-a-backend-bd8f2648cfa5)
Work around presented in the article:
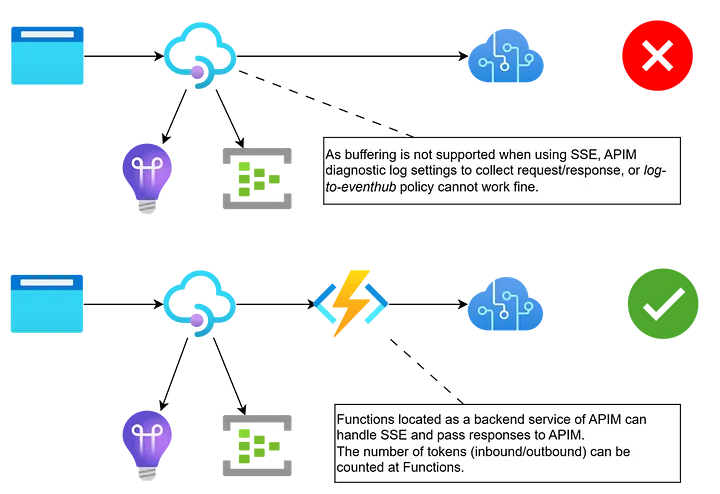 |
|---|
| Figure 8: Handling Streaming |
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for