Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,657 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EOB%3C/text%3E%3C/svg%3E)
Azure Data Factory - Data Wrangling with Data Flow - Array bug.
I have a tricky firewall log file to wrangle using Azure data factory. The file consists of 4 tab-separated columns. Date and Time, Source, IP and Data.
The Data column consists of key-value pairs separated with equal signs and text delimited by double-quotes. The challenge is that the data column is inconsistent and contains any number of key-value pair combinations.
Three lines from the source file.
2022-02-13 00:59:59 Local7.Notice 192.168.40.1 date=2022-02-13 time=00:59:59 devname="NoHouse" devid="FG100ETK18006624" eventtime=1644706798637882880 tz="+0200" logid="0000000013" type="traffic" subtype="forward" level="notice" vd="root" srcip=192.168.41.200 srcport=58492 srcintf="port1" srcintfrole="undefined" dstip=216.239.36.55 dstport=443 dstintf="wan1" dstintfrole="undefined" srccountry="Reserved" dstcountry="United States" sessionid=137088638 proto=6 action="client-rst" policyid=5 policytype="policy" poluuid="c2a960c4-ac1b-51e6-8011-6f00cb1fddf2" policyname="All LAN over WAN1" service="HTTPS" trandisp="snat" transip=196.213.203.122 transport=58492 appcat="unknown" applist="block-p2p" duration=6 sentbyte=3222 rcvdbyte=1635 sentpkt=14 rcvdpkt=8 srchwvendor="Microsoft" devtype="Computer" osname="Debian" mastersrcmac="00:15:5d:29:b4:06" srcmac="00:15:5d:29:b4:06" srcserver=0
2022-02-13 00:59:59 Local7.Notice 192.168.40.1 date=2022-02-13 time=00:59:59 devname="NoHouse" devid="FG100ETK18006624" eventtime=1644706798657887422 tz="+0200" logid="0000000013" type="traffic" subtype="forward" level="notice" vd="root" srcip=192.168.41.200 srcport=58496 srcintf="port1" srcintfrole="undefined" dstip=216.239.36.55 dstport=443 dstintf="wan1" dstintfrole="undefined" srccountry="Reserved" dstcountry="United States" sessionid=137088640 proto=6 action="client-rst" policyid=5 policytype="policy" poluuid="c2a960c4-ac1b-51e6-8011-6f00cb1fddf2" policyname="All LAN over WAN1" service="HTTPS" trandisp="snat" transip=196.213.203.122 transport=58496 appcat="unknown" applist="block-p2p" duration=6 sentbyte=3410 rcvdbyte=1791 sentpkt=19 rcvdpkt=11 srchwvendor="Microsoft" devtype="Computer" osname="Debian" mastersrcmac="00:15:5d:29:b4:06" srcmac="00:15:5d:29:b4:06" srcserver=0
2022-02-13 00:59:59 Local7.Notice 192.168.40.1 date=2022-02-13 time=00:59:59 devname="NoHouse" devid="FG100ETK18006624" eventtime=1644706798670487613 tz="+0200" logid="0001000014" type="traffic" subtype="local" level="notice" vd="root" srcip=192.168.41.180 srcname="GKHYPERV01" srcport=138 srcintf="port1" srcintfrole="undefined" dstip=192.168.41.255 dstport=138 dstintf="root" dstintfrole="undefined" srccountry="Reserved" dstcountry="Reserved" sessionid=137088708 proto=17 action="deny" policyid=0 policytype="local-in-policy" service="udp/138" trandisp="noop" app="netbios forward" duration=0 sentbyte=0 rcvdbyte=0 sentpkt=0 rcvdpkt=0 appcat="unscanned" srchwvendor="Intel" osname="Windows" srcswversion="10 / 2016" mastersrcmac="a0:36:9f:9b:de:b6" srcmac="a0:36:9f:9b:de:b6" srcserver=0
My strategy for wrangling this data set is as follows.
This all sounds good but unfortunately step 5 fails with the following error. “Indexing is only allowed on the array and map types”.
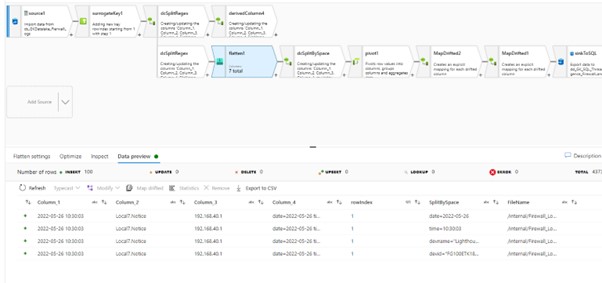
The output after step 4.

The unfold function returns an array according to the inspect tab, see below. I would expect a string here!!

Now in step 5, I split by “=” with the expression split(unfoldSplitBySpace, '=') but this errors in the expression builder with the message “Split expect string type of argument”
Changing the expression to split(unfoldSplitBySpace1, '=') remove the error from the expression Builder.
BUT THEN the spark execution engines errors with “Indexing is only allowed on the array and map types”

The problem.
According to the Azure Data Factory UI, the output of the Unfold() function is an array type but when accessing the array elements or any other function the spark engine does not recognise the object as in array type.
Is this a bug in the execution or do I have a problem in my understanding of how the data factory and a spark engine understand arrays?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Okker Botes ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is to take your sample data and make it into either
2022-02-13 00:59:59 | Local7.Notice | 192.168.40.1 | date | 2022-02-13
2022-02-13 00:59:59 | Local7.Notice | 192.168.40.1 | time | 00:59:59
or
2022-02-13 00:59:59 | Local7.Notice | 192.168.40.1 | 2022-02-13 | 00:59:59
I am trying to reproduce via your steps, but found a few anomalies. I suspect the cause of anomalies in not in your work, but some formatting done by Q&A.
; you mentioned. I haven't found any semicolons ;. I also haven't found any spaces next to colons :, before or after. 
Instead you can see the regex captured everything in a single element, and plunked that into an array.
I suspect this all can be explained by formatting caused by Q&A or maybe you put in the wrong sample data. After all, you have pictures of it working. I suggest attaching / upload file to Q&A instead of pasting as text in post.
I did have another idea to try, but the regex cut me off. Use Flatten instead of unfold + unpivot. I suspect I'll run into an issue of needing to define all keys though. In that case unfold + unpivot is the way to go.
So right after the unfolding step and before the SplitByEquals, I put a derived column. In this I tried:
toString( unfoldIntoRows[0] )
This gave the index error. Next I tried:
toString( unfoldIntoRows )
This previewed find and showed as strings.

Now I expect things to behave in the split by equals step, now that I have a transform dedicated to ensuring the type , whatever craziness is happening.

So, my conclusion is that you found a bug or glitch. I think the type was falsely reported somewhere in the process, but for now explicitly casting to string seems to be a work-around. I'll bring this to the attention of @MarkKromer-MSFT .
I have attatched my script so you may inspect it, @Okker Botes .
205582-script-for-type-bug.txt
Let if know if this was the only blocker, or if I should try the unpivot. BTW, are you sure you don't mean regular pivot?
Wow, What fantastic support!!!
I think your regex (the dark art of strings) is much simpler and more functional than mine. To be honest I did not know how mine worked.
“I'm thinking it is either a bug somewhere, or a strange rule that isn't evident event to me”
I concur, expecting a fix sone.
I tried the Stringify component without success. So your toString( unfoldIntoRows ) is brilliantly simple. I only realised that I could write code in the Derived Column component yesterday. Plaining to use this loss in the future.
I solved my problem with a different approach. I replaced the unfold with a flatten component. Witch achieved the same outcome. But to be honest I'm not exactly sure how this works. :)

I think your solution is cleaner. What's your opinion? I’m wondering which one will be more performant. My biggest log file to process is, currently, 2.46 GiB. So performance is going to be a big factor. ( at present when processing the large file the debug runtime errors with “Failed to execute dataflow with internal server error”. But I will log a new issue for this. )
“are you sure you don't mean regular pivot?” Yes I mean pivot. Thanks for the offer, but I was successful with this and the sink step. :)
Thanks again for the amazing support.
Okker
@Okker Botes , the engineers have taken note of this bug, but I have yet to receive a tracking number for this item. Good find, and thank you for the great feedback!
I tried many things, and they are all muddled together now.
Anyway, great to hear things are working fine for you.
Flatten is used more often with nested JSON. Flatten is somewhat similar to cross-apply. If you are using flatten, I recommend you double verify all expected fields are there in later records. In the past I ran into some issues when the first item I flattened did not have the same schema as later items that flattened. It needed to have all properties specified.
Given that you are flattening just a single array with no possibility of deeper layers, you might not run into the same issue.
I have converted comment to answer so you may mark as accepted answer.
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
As for performance of Flatten vs Unfold, I'm not really sure. They might even end up being the same on the back-end. I would expect the pivot to be more compute intensive than either fold or flatten.
If you are really interested, you can run data a couple times with each, and then in the monitoring section, look at how long each phase took. Remember, sample size is key! (How many times you try, not just the size of the data.)
For performance, partitioning , indexing, and parallelism are the big drivers. You could develop a bad flow design, but to the best of my knowledge flatten vs unfold isn't one of those decisions.
This is some of the best support I have ever had on any software product, thank you for your contribution MartinJaffer-MSFT!!!!
Thanks for your response and for clarifying the difference between Unfold and Flatten.
I have run some tests on a relatively large data set and found the processing time for both to be comparable. As you suspected the pivot is much more compute-intensive.
Thanks for taking the time to reply, Martin, it is much appreciated.
The ask is to split Column4 (the data) into columns with the key as the heading and the values in the rows. the sink will be Azure SQL server.
I have attached a smaller sample file.
205432-firewall-logs-20220524-113003-2022-05-24t081338-so.txt
Hmm, the file didn't make that much difference. Now that I have a fresh mind, I tried making my own regex. I haven't done heavy regex in a long time, so I may be mistaken, but something seemed off with yours.
Specifically, yours ended with $ which means end of string. If the end of string is mandatory for a match, then it can only happen once.
So I tried with something simpler. Keeping in mind we are doing a split, I only want to get hits for a single blank space, asserted to be followed by at least one or more alphanumeric characters followed by an equals sign =. I am making the asumption, equals does not occur inside value string. I came up with:
regexSplit(toString(byPosition(4)), ` (?=\w+\=)` )
` (?=\w+\=)`
(?=\w+\=)
This gets me past that step. Now I believe I have reproduced your findings.
Strangely enough, the unfolding step outputs an array of strings, length 1. Not what I expected.
Splitting by equals does give me that same error message about indexing on array and map types. Also not what I expected.
So I don't think you are doing anything wrong. I'm thinking it is either a bug somewhere, or a strange rule that isn't evident event to me.
Now, there is one thing that could possible make sense. The indexing message would make sense if I tried to do it on a string, not array. So if it is a string, not array, then the previous step must be telling us something incorrect. I've got an idea to force the matter. Message you later, @Okker Botes