Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,657 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EST%3C/text%3E%3C/svg%3E)
Currently we have a number of ADF's; each ADF contains one to several pipelines, each of which is related to a specific business function. There is an ongoing debate in our tech group: one camp wants to have a single ADF that contains all Pipelines, and one camp wants to have multiple ADF's with each ADF containing pipeline's that are related to a "functional concern" such as business process, or data ingress, or data egress. There may be a lot of pipelines that cross business lines and data ingress and egress, with some reading or writing data to on-prem resources via a SHIR. I am looking for a best practice guide that considers things like "separation of concerns" in the design of ADF's and in particular, the grouping of pipelines in an ADF.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Stephen Thomas Wheeler ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Martin
Hello @Stephen Thomas Wheeler ,
Thanks for the question and using MS Q&A platform.
As I understand, you are asking for advice or comments on whether to use a single Azure Data Factory, or multiple, in regards to "separation of concerns". I am not aware of a best practice guide on this topic, but one may yet exist.
I would like to make you aware of some options and ramifications of choosing one or the other approach. The chief option you may or may not be aware of, is pipeline folders. For ease of organization, you can create folders to organize the assets in a single Data Factory.
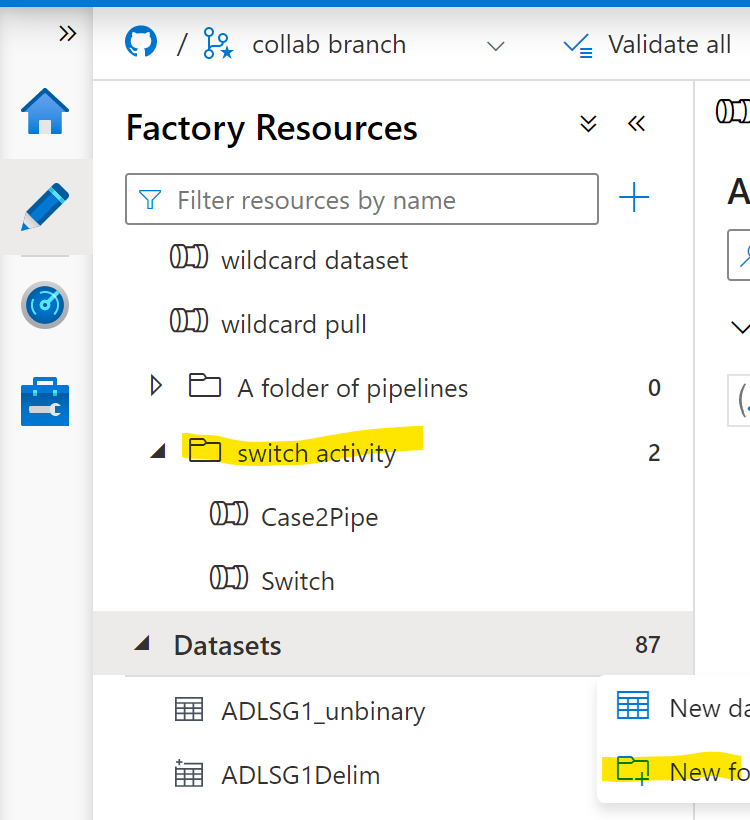
The ramifications include:
Keeping linked services synchronized. Naturally, data is ingested / ingressed for a purpose. This purpose may be embodied by a pipeline in another Factory. If for some reason, a change is made to the location of data, a change will need to be made in the Linked Service or Dataset. With multiple factories, both will need a copy of the Linked Service / Dataset. One for depositing, the other for reading. Should only one of these be changed, the other will not work properly. Using Azure Key Vault may help to some extent. If there is only a single Factory, you can re-use the Linked Service / Dataset in both the ingress and the processing piplines.
Trigger dependency and Executing child pipelines
. You may want to have the success of one step / business process / pipeline cause another step / business process/ pipeline to run. Naturally, this is easier when everything is inside the same Factory. This allows for use of Execute Pipeline activity. Execute Pipeline activity cannot be used on a pipeline is a different Factory. There are ways to cause pipelines to run in other factories, but that is more for exceptions than general use.
You can set up Tumbling Window Trigger dependencies, where one pipeline runs if and only if another pipeline was run successfully. This only works within a Data Factory, there are no cross-factory options.
Self-Hosted Integration Runtime (SHIR) complications
. Only one instance of SHIR can be running on a machine at a time. This SHIR is 'owned' (registered to) by exactly one (1) Data Factory. This SHIR can be shared with other factories (See Shared SHIR document). However when CI/CD , multiple environments, and delployment pipelines are involved, the issue becomes much harder to maintain. A recommended practice, when a SHIR is shared with many factories and environments, is to have a Factory dedicated to owning the SHIRS independent of environments.
You need to be mindful of the workload placed upon a SHIR. With multiple factories, that is like an entire office sharing a single printer. Same amount of work, but more coordination and monitoring. Azure Monitor may help.
Cost is not really a concern. There is a small bit of overhead, but unless you have 100 factories, it is insignificant to data processing cost.
There are limits to how much can go into a Factory, but there are subscription limits too. See link. Whether you even get close depends upon your organization. The most significant and relevant ones in my opinion are:
But I must ask, what are you really trying to accomplish? Is it limiting permissions, like only certain people should be able to edit pipeline X? That is a much trickier task to accomplish. If you seek to limit permissions per separation of concern, then you should use separate Data Factories. There is a way to make custom roles for specific assets, but it is difficult and not easy to maintain.
When it comes to Git / ADO integration and keeping code in repository, some options open up. You can give each separation of concern its own branch, and merge them before publish/deploy. Remember from my first point, the advantage of de-duplication of Linked Service/ Datasets. If each branch makes their own differently named copy, you lose some of that.
There is another feature you may find useful, especially for sorting your concerns. Annotations (pipelines) and User Properties (activities). These are more useful for tagging / documentation / notes. Annotation shows up in Monitoring and can be used for filtering.

(posting before I lose stuff)
Please do let me if you have any queries.
Thanks
Martin
------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how ' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EFD%3C/text%3E%3C/svg%3E)
This was an excelent explanation, thank you. My team is new to cloud data engineering and this was a huge concern for my team as well. We manage 1200 automations currently (many of these will be able to make use of triggering) and we were trying to decide what the best aproach would be. Thank you again!