Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGS%3C/text%3E%3C/svg%3E)
So, I have some parquet files stored in azure devops containers inside a blob storaged. I used data factory pipeline with the "copy data" connector to extract the data from a on premise Oracle database.
I'm using Synapse Analytics to do a sql query that uses some of the parquet files store in the blob container and I want to save the results of the query in another blob. Which Synapse connector can I use the make this happen? To do the query I'm using the "develop" menu inside Synapse Analytics.

Hi @GABRIEL SOLON PADILHA ,
Just checking in to see if the below answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Welcome to Microsoft Q&A platform and thanks for posting your question here.
As per my understanding , you are trying to load the output of parquet file from one container to another using synapse analytics. Please correct me if my understanding is wrong.
You can consider using Notebook in synapse analytics where you can write pyspark code to create a dataframe and load the output of parquet file into the same dataframe and then write that dataframe into blob storage in specified file format.
Note: Kindly make sure that your Azure AD user has read/write permissions on the storage account.
Kindly check the below code where I am trying to read parquet file and writing it as csv in the storage account.
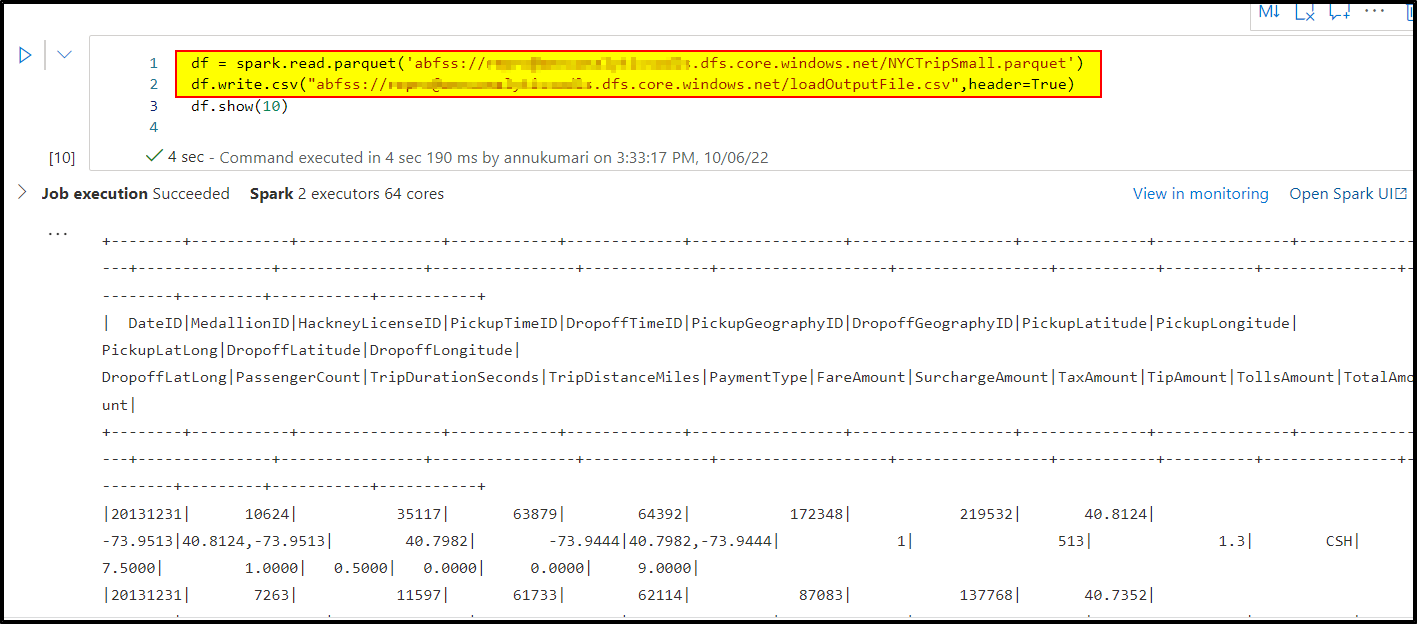
For more details, kindly check : Read & write parquet files using Apache Spark in Azure Synapse Analytics
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @GABRIEL SOLON PADILHA ,
Alternatively , you can also make use of Microsoft Spark File System(mssparkutils.fs) Utilities in Azure Synapse analytics to copy the file from one location to another within the storage account. Use the below command to perform the copy:
mssparkutils.fs.cp(src,dest)
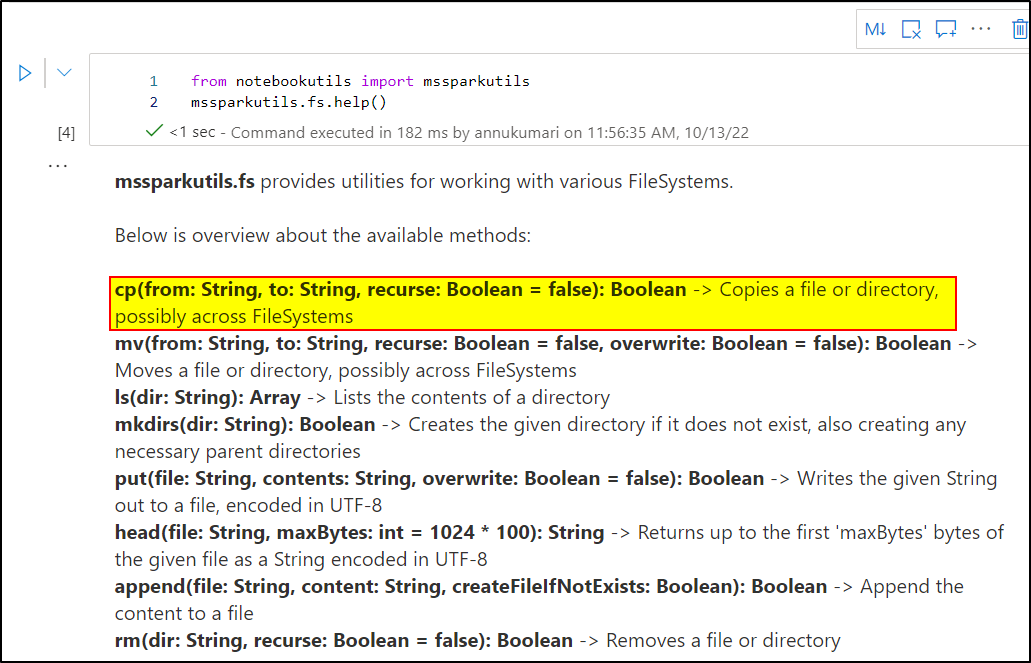
For more details, kindly watch out: Microsoft Spark File System(mssparkutils.fs) Utilities in Azure Synapse analytics
----------------------
Hope it helps. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well.