Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM2%3C/text%3E%3C/svg%3E)
Hi Team,
Some of the default packages present in a Synapse spark pool 'out of the box' are not up to date enough for my needs, so I want to be able to download specific versions.
I have:
But every attempt I have made to do this has resulted in a 'failed to apply settings' error, citing a message similar to:
...
INFO Running /usr/lib/miniforge3/bin/conda env update -p /home/trusted-service-user/cluster-env/clonedenv --file /usr/lib/library-manager/bin/lmjob/sparkpoolcustom/package_cleaned_environment.yml","Pip subprocess error:","ERROR: numpy-1.23.3-cp38-cp38-win32.whl is not a supported wheel on this platform.","","","CondaEnvException: Pip failed","","22/10/07 11:06:25 ERROR b\"Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you.\\nCollecting package metadata (repodata.json): ...working... done\\nSolving environment: ...working... done\\nPreparing transaction: ...working... done\\nVerifying transaction: ...working... done\\nExecuting transaction: ...working... done\\nInstalling pip dependencies: ...working... Ran pip subprocess with arguments:\\n['/home/trusted-service-user/cluster-env/clonedenv/bin/python', '-m', 'pip', 'install', '-U', '-r', '/usr/lib/library-manager/bin/lmjob/sparkpoolcustom/condaenv.t1h1b1b3.requirements.txt']\\nPip subprocess output:\\n\\nfailed\\n\"","22/10/07 11:06:25 INFO Cleanup following folders and files from staging directory:","22/10/07 11:06:29 INFO Staging directory cleaned up successfully"],"registeredSources":null}
It seems at though the version of Python running on Synapse is 3.8.10, hence I downloaded the cp38 version of the package, but no joy. Can anyone shed any light as to what might be wrong?
Thanks,
Matty
Hi,
Thanks for responding.
The Requirements.txt file is very simple. It contains the only following:
scikit-learn==1.1.2
Which is all I understand is needed for things to work?
Thanks,
Matty

Hello @Matty-2070 ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
In addition to the above, I have also tried to add a package via the 'Requirements files' option, using a Requirements.txt file. This has also failed. Message as follows:
ProxyLivyApiAsyncError
LibraryManagement - Spark Job for sparkpoolcustom in workspace **** in subscription **** failed with status:
{"id":9,"appId":"application_****","appInfo":{"driverLogUrl":"http://vm-****/node/containerlogs/container_****/trusted-service-user","sparkUiUrl":"http://vm-****/proxy/application_****/","isSessionTimedOut":null,"isStreamingQueryExists":"false","impulseErrorCode":null,"impulseTsg":null,"impulseClassification":null},"state":"dead","log":["Elapsed: -","","An HTTP error occurred when trying to retrieve this URL.","HTTP errors are often intermittent, and a simple retry will get you on your way.","'https://conda.anaconda.org/conda-forge/linux-64'","","","22/10/07 13:35:00 ERROR b\"Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you.\\nCollecting package metadata (repodata.json): ...working... failed\\n\"","22/10/07 13:35:00 INFO Cleanup following folders and files from staging directory:","22/10/07 13:35:04 INFO Staging directory cleaned up successfully"],"registeredSources":null}
This is incredibly frustrating, especially given that it takes about 10 minutes for the spark pool to respond each time you try!
Cheers,
Matty
Hello @Matty-2070 ,
Thanks for the question and using MS Q&A platform.
Could you please share the content of the requirements.txt?
As per the error message: "ERROR: numpy-1.23.3-cp38-cp38-win32.whl is not a supported wheel on this platform. - which clearly says .whl is not supported.
As per the repro - I'm able to successfully install numpy pacakge using
requirements.txtas shown below:
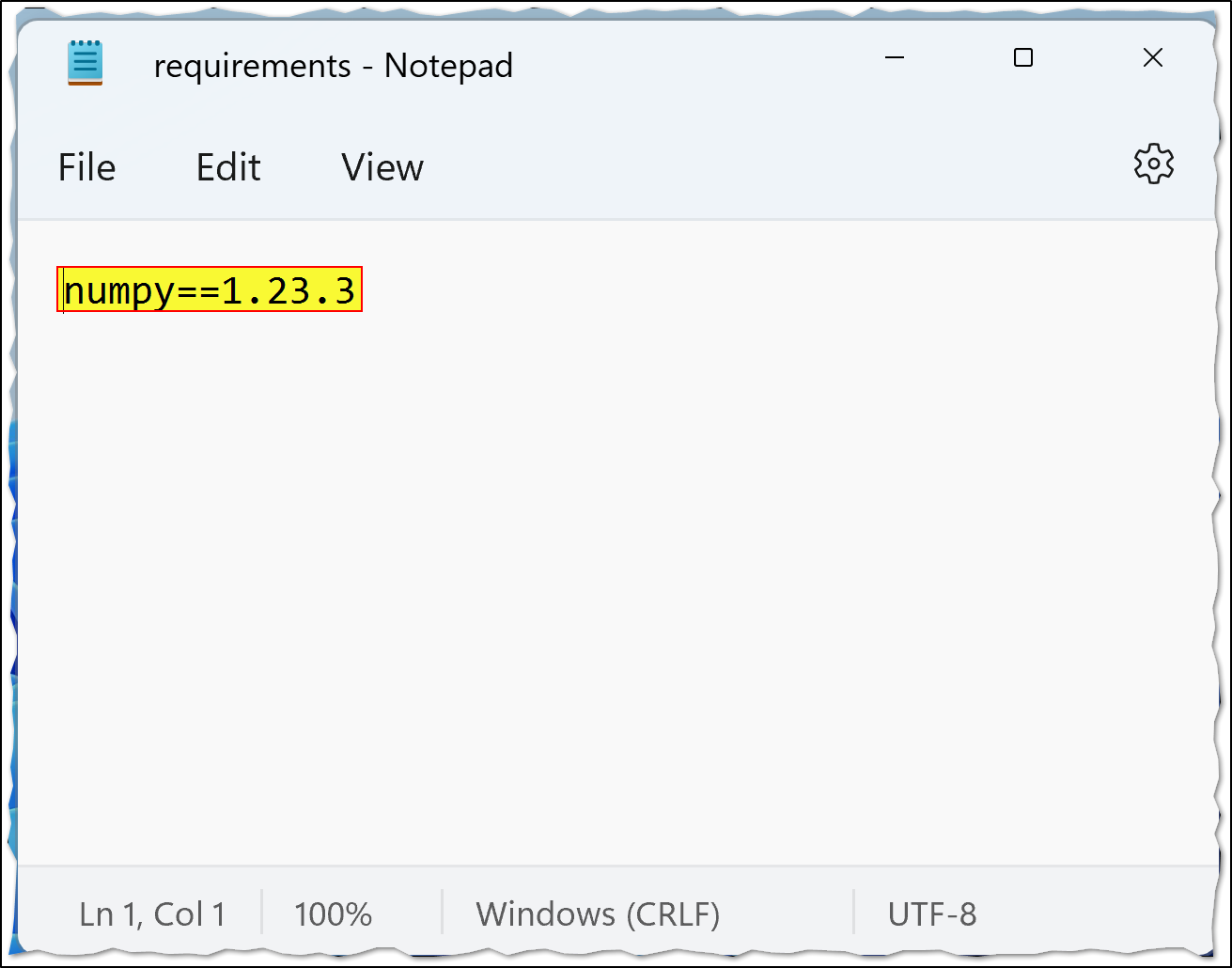
Above
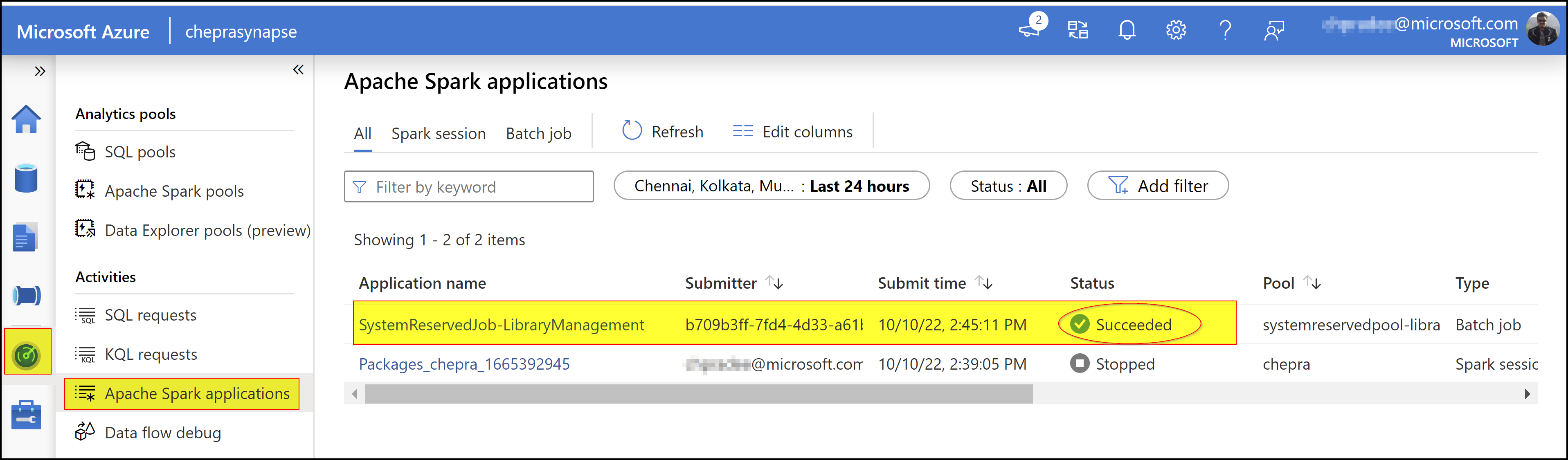
requirements.txtsuccessfully installed on the Apache Spark pool:
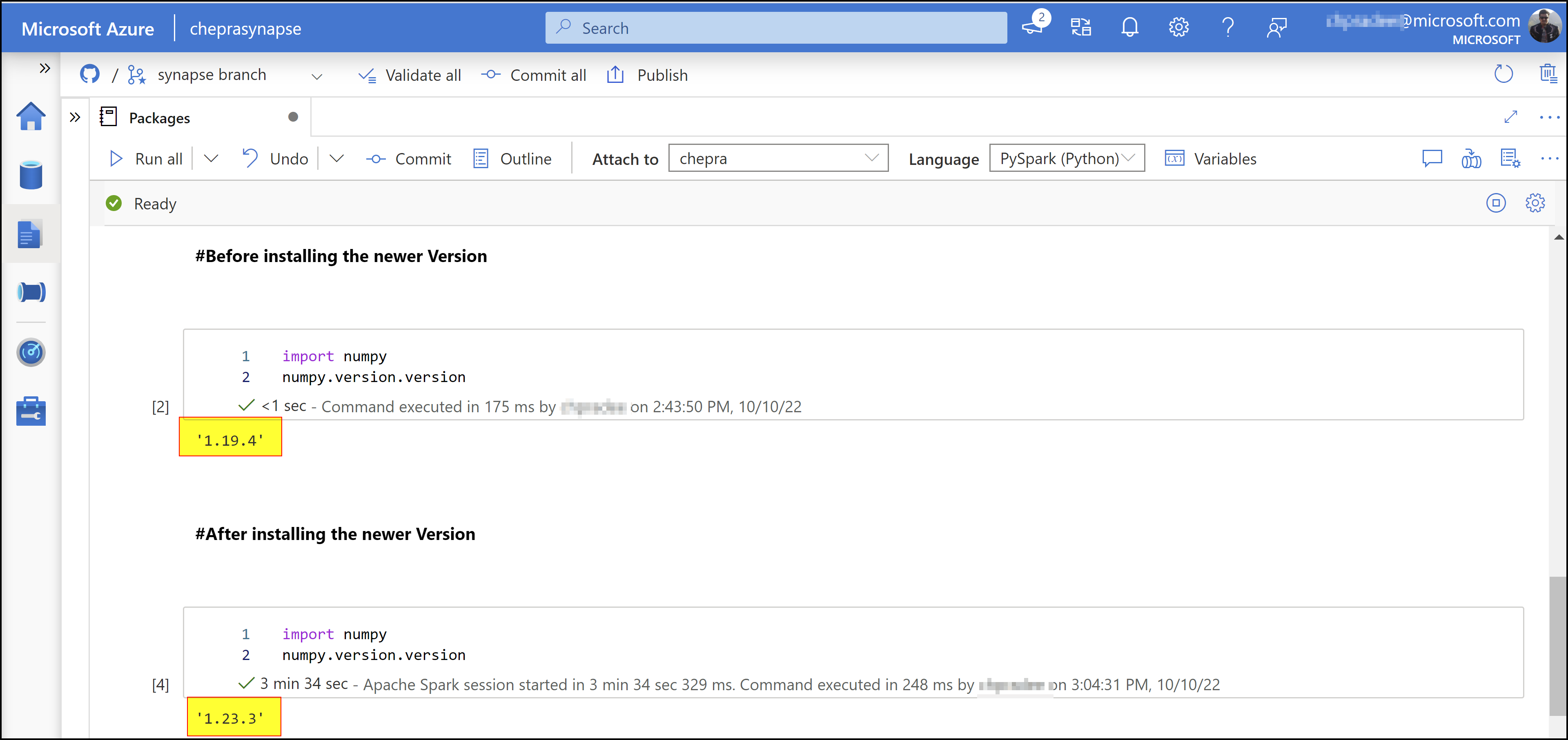
Checkout the numpy package update from the previous version as shown below:
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hi,
Thank you for your detailed response.
I've tried to install numpy==1.23.3 exactly as suggested, but I get an error after around 10 minutes of it running.
The method I am using:
Requirements.txt file contains numpy==1.23.3
Then upload the file via the following method:
'Manage' > 'Apache Spark pools' > choose 'Packages' on the specific spark pool > upload Requirements.txt file via the 'Requirements files' section > 'Upload' > 'Apply'
Then wait patiently for 10 mins for it to work (or fail in this case).
Do you know what the issue might be? Are there any other configs that I might need to change to get things to work?
Cheers,
Matty
Hi,
Interestingly, when I try the above using a different Azure account, it works fine. So the issue is exclusively related to the specific account/Synapse instance.
If there's anything you can recommend I check, that would be appreciated.
Thanks,
Matty
Hello @Matty-2070 ,
Could you please try to create a new Apache Spark pool in the workspace and try to install the package and see if that works?
Hi,
I have tried loading to a completely new spark pool this morning, but it failed again. Here's the error:
Error details
Notifications
ProxyLivyApiAsyncError
LibraryManagement - Spark Job for sparkpooltest in workspace **** in subscription **** failed with status:
{"id":18,"appId":"application_****","appInfo":{"driverLogUrl":"http://vm-****/node/containerlogs/container_****/trusted-service-user","sparkUiUrl":"http://vm-****/proxy/application_****/","isSessionTimedOut":null,"isStreamingQueryExists":"false","impulseErrorCode":null,"impulseTsg":null,"impulseClassification":null},"state":"dead","log":["Elapsed: -","","An HTTP error occurred when trying to retrieve this URL.","HTTP errors are often intermittent, and a simple retry will get you on your way.","'https://conda.anaconda.org/conda-forge/linux-64'","","","22/10/11 08:16:58 ERROR b\"Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you.\\nCollecting package metadata (repodata.json): ...working... failed\\n\"","22/10/11 08:16:58 INFO Cleanup following folders and files from staging directory:","22/10/11 08:17:01 INFO Staging directory cleaned up successfully"],"registeredSources":null}
I am now wondering whether the issue is linked to how Azure has been configured within our corporate environment given that things are working fine when I use my personal Azure account, but I wouldn't know what to check. Any ideas?
Cheers,
Matty
Hello @Matty-2070 ,
This issue looks strange with your synapse workspace. For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
Hi,
I've noticed in the logs that exfiltration protection is set to true:
INFO Data exfiltration protection set to: true
I wonder if this is the issue? Link to the Microsoft article on this below:
Cheers,
Matty
Hello @Matty-2070 ,
Users can provide an environment configuration file to install Python packages from public repositories like PyPI. In data exfiltration protected workspaces, connections to outbound repositories are blocked. As a result, Python libraries installed from public repositories like PyPI are not supported.
As an alternative, users can upload workspace packages or create a private channel within their primary Azure Data Lake Storage account. For more information, visit Package management in Azure Synapse Analytics.
Thanks for responding - your explanation makes sense.
I will now have a look at uploading via the method described in order to overcome the data exfiltration protection that exists.
Cheers,
Matty
Hello @Matty-2070 ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
------------------------------
or upvote button whenever the information provided helps you.