Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,374 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVM%3C/text%3E%3C/svg%3E)
Hi i could do with some help on a requirement I have that I need to achieve using synapse pipeline dataflow.
My data looks like this:
user_id, certification_id, certification_title, expiry_date
1000, "201, 202, 203", "Azure Certification1, Azure Certification2, Azure Certification3", "2099-12-31, 2022-12-12, 2023-05-05"
expected output is
user_id, certification_id, certification_title, expiry_date
1000, 201, Azure Certification1, 2099-12-31
1000, 202, Azure Certification2, 2022-12-12
1000, 203, Azure Certification3, 2023-05-05
this is how i tried it
my source data is from a rest api end point
certification_id stream 1: split function in dervied columns >> flatten >> denseRank function in window
new branch - certification_title stream 2: split function in dervied columns >> flatten >> denseRank function in window
new branch - expirry_date stream3: split function in dervied columns >> flatten >> denseRank function in window
then i am joining the data back again using a join with user_Id and rank as key columns.
the data works in most cases but because i need to sort the data to use the window option - i am losing the consistency in the output data format.
also i am not sure if its a very performant way of doing this.
any advice would be greatly appreciated.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Anonymous and welcome to Microsoft Q&A.
I think I understand your ask, the input and output helps greatly, but I do have one question.
Is the number of certifications in a row the same for all rows, or might some have 2, some have 3, some have 4 and so on?
The first problem I ran into, was dataflow not respecting the quotes.

Did you run into this @Anonymous ?
Anyway, here is what I had in mind:
certification_id, certification_title, and expiry_date to arrays of integers, strings, and dates respectively. This is assuming they are read as strings. maploop function to create a more complex dataform (seen below) unfold function on this new form to put each complex element into its own row This approach avoids joins, and makes it faster.
The code for creating the dataform vaguely looks like the below. I probably will need to make some corrections, but this should get the idea across.
unfold(
maploop(
size(certification_id),
{ certification_id[%index], certification_titel[%index], expiry_date[%index] }
)
)
... yeah I found another issue. That's not working.
Thanks for taking time to help Martin - i was only showing data for illustration purposes. there arent quotes in the data. they are all treated as strings.
Is the number of certifications in a row the same for all rows, or might some have 2, some have 3, some have 4 and so on? >> the number could be any - i have examples where one guy has 3, another has 14 certifications and some none. the number of delimited values are consistent across all columns even with no data - the delimieter is present eg: 2099-12-31,,
If there are no quotes, how do you tell when the collection starts and ends @Anonymous ? They seem kinda necessary, otherwise the number of columns would vary wildly on read.
Hello @Anonymous ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Martin
Hello @MartinJaffer-MSFT .. I must admit for some reason i didn't get a notification for your earlier post with the unfold which I feel is more efficient and might work better than what I did.
I did it in a crude way - split the data. Created a denserank on it that gave me certification_id + rank as key to join data back to each other.
But I will try that some time with your below suggestion. Thanks for taking so much time to respond to my question. Appreciate it
Thanks for letting me know @Anonymous . My colleague kept suggesting rank also, but I felt there had to be a better way.
If this works out for you, please mark as accepted answer.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Okay, I got it now @Anonymous !
Also, I found the blocker earlier; the space after the comma makes a difference! So putting space after the comma in delimiter took care of that.
Below I past the dataflow script. It works pretty much like I originally wanted.
source(output(
user_id as short,
certification_id as string,
certification_title as string,
expiry_date as string
),
useSchema: false,
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'delimited',
container: 'input',
fileName: 'vasmi.csv',
columnDelimiter: ', ',
escapeChar: '',
quoteChar: '\"',
columnNamesAsHeader: true) ~> source1
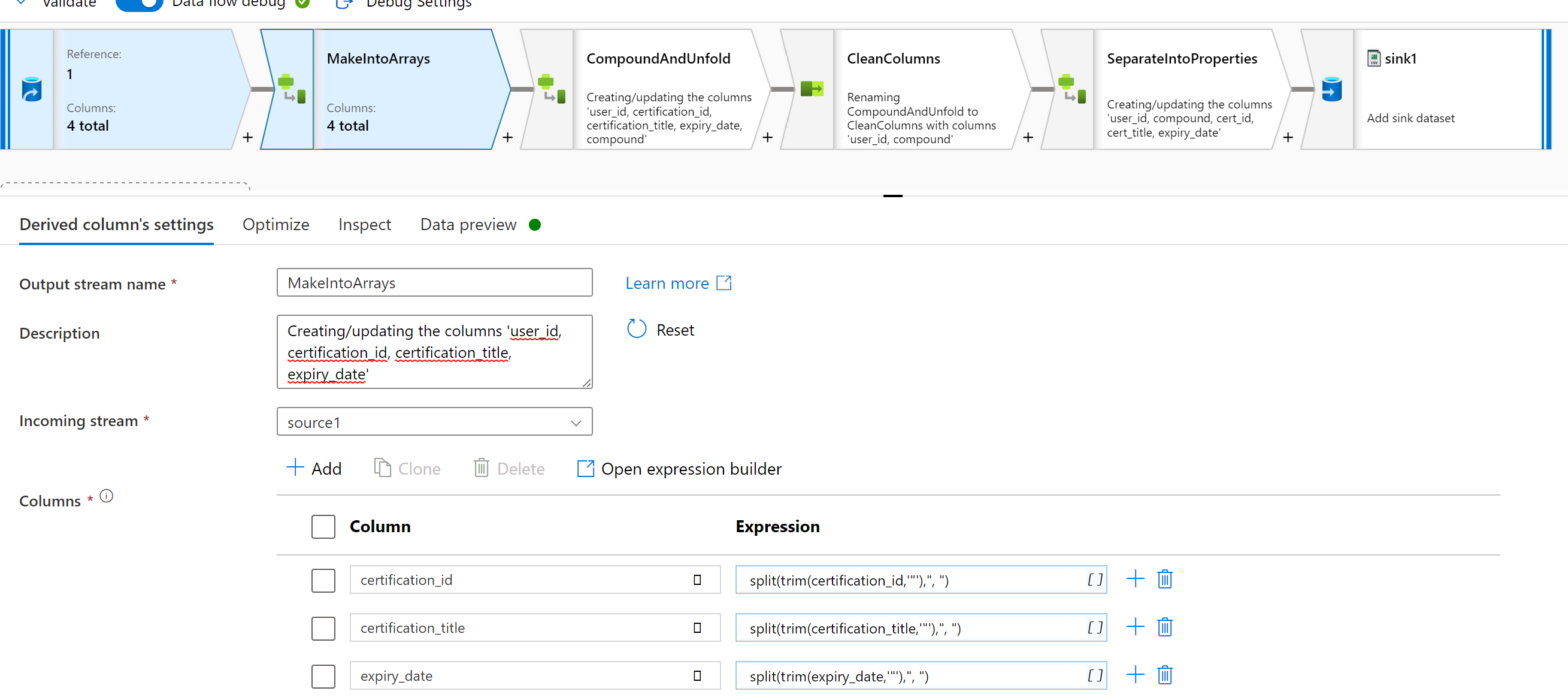
source1 derive(certification_id = split(trim(certification_id,'"'),", "),
certification_title = split(trim(certification_title,'"'),", "),
expiry_date = split(trim(expiry_date,'"'),", ")) ~> MakeIntoArrays
MakeIntoArrays derive(compound = unfold(mapLoop(
size(certification_id),
array(certification_id[#index],certification_title[#index],expiry_date[#index])
))) ~> CompoundAndUnfold
CompoundAndUnfold select(mapColumn(
user_id,
compound
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CleanColumns
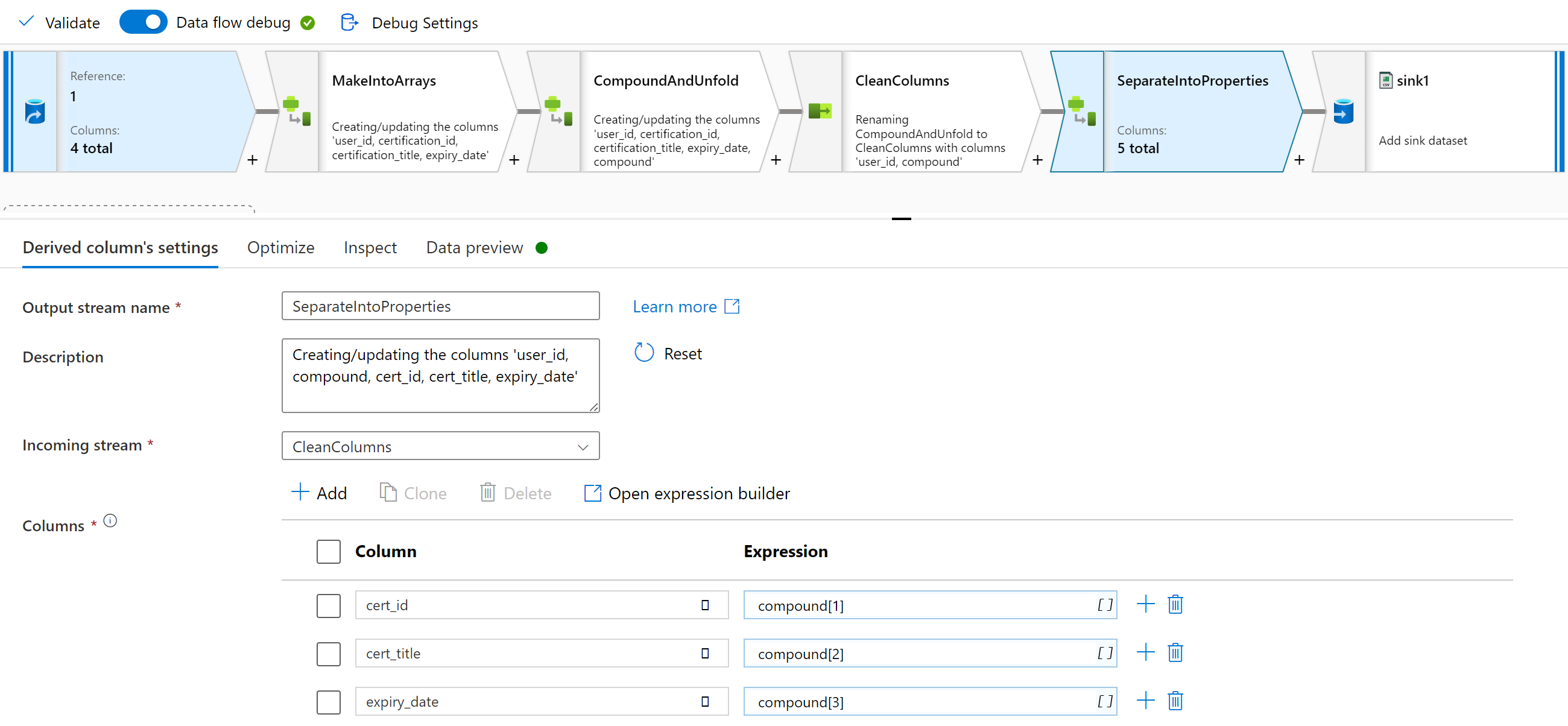
CleanColumns derive(cert_id = compound[1],
cert_title = compound[2],
expiry_date = compound[3]) ~> SeparateIntoProperties
SeparateIntoProperties sink(allowSchemaDrift: true,
validateSchema: false,
format: 'delimited',
fileSystem: 'data',
folderPath: 'out',
columnDelimiter: ',',
escapeChar: '\\',
quoteChar: '\"',
columnNamesAsHeader: true,
umask: 0022,
preCommands: [],
postCommands: [],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
mapColumn(
user_id,
cert_id,
cert_title,
expiry_date
)) ~> sink1
unfold(mapLoop(
size(certification_id),
array(certification_id[#index],certification_title[#index],expiry_date[#index])
))