Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3E8%3C/text%3E%3C/svg%3E)
I am getting a capacity error and going through the below forum. As per the thread, we need to request a capacity increase via the Azure portal by creating a new support ticket.
AVAILABLE_COMPUTE_CAPACITY_EXCEEDED: Livy session has failed. Session state: Error. Error code:
AVAILABLE_COMPUTE_CAPACITY_EXCEEDED. Your job requested 20 vcores. However, the pool only has 0 vcores available out of quota of 20 vcores. Try ending the running job(s) in the pool, reducing the numbers of vcores requested, increasing the pool maximum size or using another pool. Source: User.
Surprisingly, I was able to resolve the error by scaling up (node size to large).
My question is as per the Microsoft document, Vcores allocation is at two levels (https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-concepts)
1) Workspace level
2) Spark pool level.
Could you please guide me on how the V-cores are allocated at the workspace level? (how many cores I will get when I create a spark pool with large node). At what situation we need to submit a support ticket to increase the v-cores at workspace level? Can you give me a use case?
And when I create a spark pool with Large(16 vcores/128 GB) and 2 to 4 nodes, how many v-croes are allocated at spark pool level?
As per the StackOverflow document, The formula to calculate the maximum number of vcores is:
maximum_number_of_vcores = (number_of_executors + 1) * number_of_vcores_consumed_by_each
and then the number of executors:
number_of_executors = executor_per_node * number_of_nodes_configured
The formula doesn't make sense. Can you please give me more details about this formula? I am looking for a number of V-crores for a large nodes with 2 to 4 v-cores on the spark pool.
also, can you explain about number_of_executors mentioned in the stack overflow document? When does the number of executors come into the picture?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
Hello,
I am also having similar doubt. I am using notebook within Microsoft Fabric. when i am running the notebooks from pipeline i am getting an error as below:
Failed to create Livy session for executing notebook. Error: [TooManyRequestsForCapacity] Unable to submit this request because all the available capacity is currently being used. Cancel a currently running Notebook or Spark Job Definition job, increase your available capacity, or try again later. HTTP status code: 430.","traceback":["Exception: Failed to create Livy session for executing notebook. Error: [TooManyRequestsForCapacity] Unable to submit this request because all the available capacity is currently being used. Cancel a currently running Notebook or Spark Job Definition job, increase your available capacity, or try again later. HTTP status code: 430.
is this something similar to this,
Thank you
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello @897456 ,
Welcome to the MS Q&A platform.
Yes, you are right. You don't need to create a support ticket to increase the v-cores if you see an error related to spark pool capacity.
If you see the below error, then you will need to reach out to Microsoft to increase the cores on the workspace level.
Failed to start session: [User] MAXIMUM_WORKSPACE_CAPACITY_EXCEEDED
The number of Vcores allocated on the spark pool is depends on the spark pool size and the number of nodes.
When you choose a medium spark pool(8 vcores/64GB) with a maximum of 4 nodes, the total available number of vcores are = 8*4 = 32 (this is the total number of v-cores on your spark pool)
To run a single notebook (application), the minimum number of Vcores depends on the code. Some notebooks may use 12 Vcores, and some may use 20 Vcores. These are depending on the workload.
Spark instances
Spark instances are created when you connect to a Spark pool, create a session, and run a job. As multiple users may have access to a single Spark pool, a new Spark instance is created for each user that connects.
When you submit a second job, if there is capacity in the pool, the existing Spark instance also has capacity. Then, the existing instance will process the job. Otherwise, if capacity is available at the pool level, then a new Spark instance will be created.
Here is an example provided on the documentation page.
Example 1:
You create a Spark pool called SP1; it has a fixed cluster size of 20 nodes.
You submit a notebook job, J1 that uses 10 nodes, a Spark instance, SI1 is created to process the job.
You now submit another job, J2, that uses 10 nodes because there is still capacity in the pool and the instance, the J2, is processed by SI1.
If J2 had asked for 11 nodes, there would not have been capacity in SP1 or SI1. In this case, if J2 comes from a notebook, then the job will be rejected; if J2 comes from a batch job, then it will be queued.
Example 2
You create a Spark pool call SP2; it has an autoscale enabled 10 – 20 nodes
You submit a notebook job, J1 that uses 10 nodes, a Spark instance, SI1, is created to process the job.
You now submit another job, J2, that uses 10 nodes, because there is still capacity in the pool the instance auto grows to 20 nodes and processes J2.
Example 3
You create a Spark pool called SP1; it has a fixed cluster size of 20 nodes.
You submit a notebook job, J1 that uses 10 nodes, a Spark instance, SI1 is created to process the job.
Another user, U2, submits a Job, J3, that uses 10 nodes, a new Spark instance, SI2, is created to process the job.
You now submit another job, J2, that uses 10 nodes because there's still capacity in the pool and the instance, J2, is processed by SI1.
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-concepts
We can also configure the session for the notebook level
for ex: If your Spark pool is configured with Node size, large (16 Vcores/128GB), and number of nodes 3 to 6
So in total, we will get 16*6 = 96 Vcores available on the spark pool.
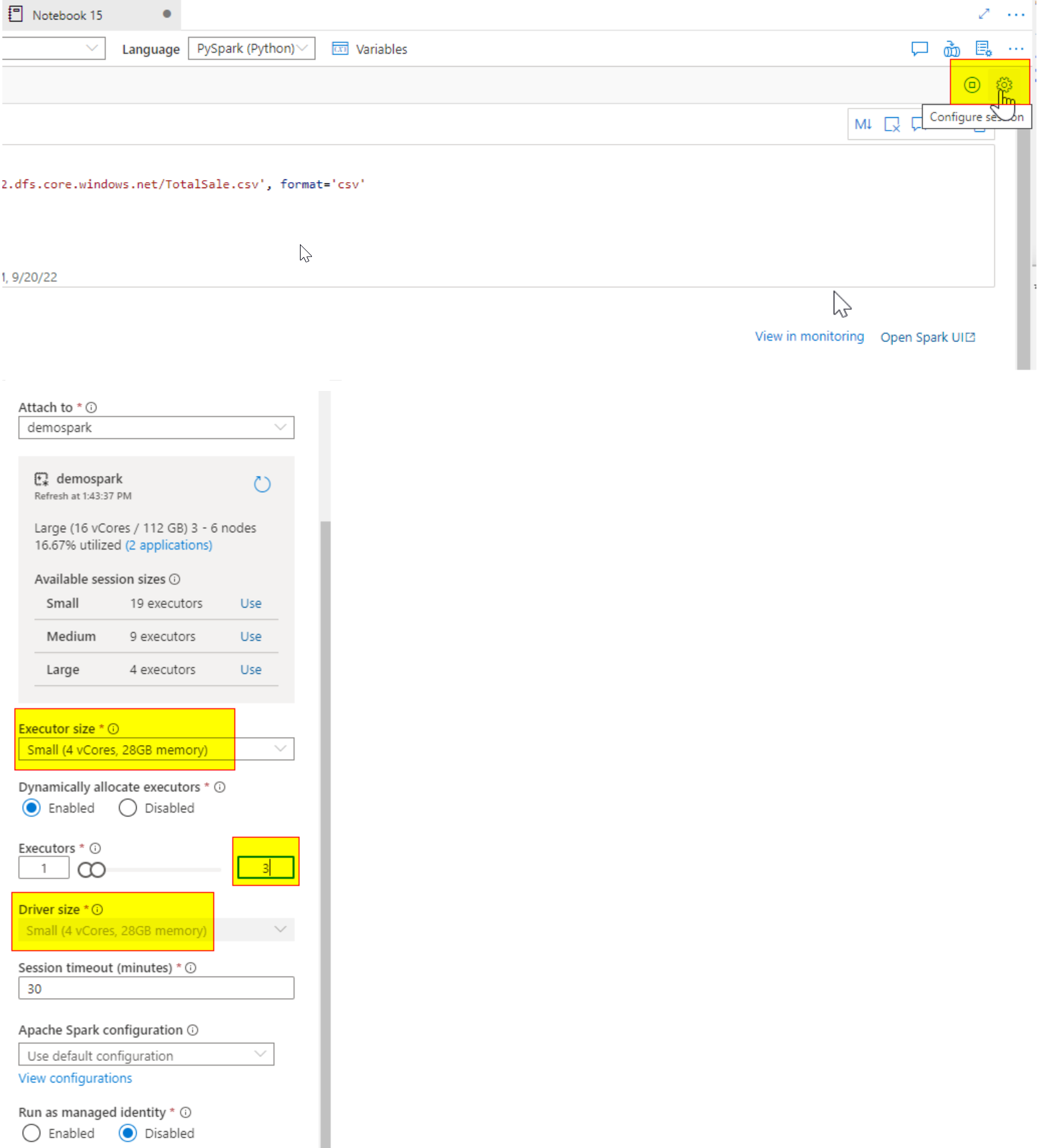
How to configure the session on the notebook level:
Click on the Gear ICON on the notebook
You will see the executor size, Driver size, and Executors. These are the main components of any Notebook session.
When you select the spark pool with Node size- large, you will see available executor size -small, medium, and large
If I choose my session to small and executors to 3, my notebook session will use max- 12 Vcores + 1 driver (4 vcores) in my case
So total= 16 Vcores will be used in my notebook out of 96 V-cores.
Please note: Driver Size is equal to Executor size.
How resources are allocated to a notebook:
consider I have a Spark pool with 16 vCores that can scale up to 10 nodes, then there will be 160 vCores available
for ex: the user1 is running notebook 1
to run notebook 2: user2 needs to define the resources using the session, which means a number of executors and their size. based on this information, spark instance 2 will be created
let's say user1 selects the executor size small 4, number of executors 2 = total 3*(4 vcores & 28 gb of ram) = 12v cores will be used on the note book1
total v-cores remaining is 160-12 = 148 v-cores
user 2 running a notebook 2, with a small size 4 and number of executor 3 = total 4*(4) = 16 v cores will be used
remaining v-cores = 148- 16 = 132 v-cores
I hope this helps. Please let me know if you have any further questions.
------------------------------
 and upvote
and upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Thank you for the detailed explanation.
Please correct me if my understanding is wrong.
I have a large spark pool (16cores and 8 nodes). So my total vcores are 16*8 = 128.
If I choose an executor size small and 2 executors for all my notebooks.. in this case, each notebook will take 12 vcores.
in total, I can run 10 parallel notebooks with this configuration.
Hello @897456 ,
Yes, your understanding is correct. Please let us know if you have any further questions.
Hello @897456 ,
I am just checking in to see if you have any further questions here.
If this answers your question, please consider accepting the answer by hitting the Accept answer button, as it helps the community.