Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,563 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
I am able to read a parquet file from Azure blob storage generated using python. This file does not have any the partition structure.
Example: containername/project/year/month/File.parquet
Code
blob_name = f'{file_path}.parquet'
blob_client = container.get_blob_client(blob=blob_name)
stream_downloader = blob_client.download_blob()
stream = BytesIO()
stream_downloader.readinto(stream)
file_data = pd.read_parquet(stream, engine='pyarrow')
But if its a parquet file is generated by a spark engine then the file has partitions in it. I am not able to read this kind of parquet file using python module. I tried to look up for resources in Azure Python SDK but unable to find it.
Found an example from Apache arrow here but its similar to the above example for unpartitioned parquet file.
Is it possible to read download the parquet file from ADLS using python, having partitions in it ?
Is it possible to read using stream without downloading the blob?

Hello @Manash ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
---------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
When I tried it did not work for me. I will check this again and get back to you.
Unfortunately direct way of reading parquet file did not work for me so I have to perform the following.
or
Hello @Manash ,
Glad to know that your issue has been resolved. And thanks for sharing the solution, which might be beneficial to other community members reading this thread.
Hello @Manash ,
Thanks for the question and using MS Q&A platform.
Use pyarrowfs-adlgen2 is an implementation of a pyarrow filesystem for Azure Data Lake Gen2.
Note: It allows you to use pyarrow and pandas to read parquet datasets directly from Azure without the need to copy files to local storage first.
And also checkout the Reading a Parquet File from Azure Blob storage of the document Reading and Writing the Apache Parquet Format of pyarrow, manually to list the blob names with the prefix like dataset_name using the API list_blob_names(container_name, prefix=None, num_results=None, include=None, delimiter=None, marker=None, timeout=None) of Azure Storgae SDK for Python as the figure below, then to read these blobs one by one.
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
For some reason its not allowing me to post the below as comments though its withing the 1600 character range.
Thanks for your suggestion @PRADEEPCHEEKATLA .
My file is present at : Container_name/Project_name/Year/Month/File.parquet/
_SUCCESS
_committed_1387639002
_started_1387639002
part-00000-tid-3006757700744507944-2dececd1-5fa7-429a-9fbe-3b21c1415734-16-1-c000.snappy.parquet
After importing all libraries,
handler = pyarrowfs_adlgen2.AccountHandler.from_account_name('acc_name', azure.identity.DefaultAzureCredential())
fs = pyarrow.fs.PyFileSystem(handler)
print("Path is {}".format("Container_name/Project_name/Year/Month/File.parquet/" ))
ds = pyarrow.dataset.dataset( "Container_name/Project_name/Year/Month/File.parquet/" , filesystem=fs)
data from blob= ds.to_table()
Error message
azure.core.exceptions.HttpResponseError: (InvalidResourceName) The specifed resource name contains invalid characters.
Code: InvalidResourceName
Message: The specifed resource name contains invalid characters.
Then I tried this,
ds = pyarrow.dataset.dataset( "Container_name/Project_name/Year/Month/File.parquet/part-00000-tid-3006757700744507944-2dececd1-5fa7-429a-9fbe-3b21c1415734-16-1-c000.snappy.parquet" , filesystem=fs)
Same error message as above
Then I renamed the partition as
ds = pyarrow.dataset.dataset( "Container_name/Project_name/Year/Month/File.parquet/renamed.parquet" , filesystem=fs)
#or
ds = pyarrow.dataset.dataset( "Container_name/Project_name/Year/Month/File.parquet/renamed.snappy.parquet" , filesystem=fs)
Same error as above.
Is there anything wrong that I am doing?
Hello @Manash ,
When you provide the file path of the parquet file it will reads all the part* files in the table.
Example: The below parquet file name parquet-table-984371 has multiple part* files.
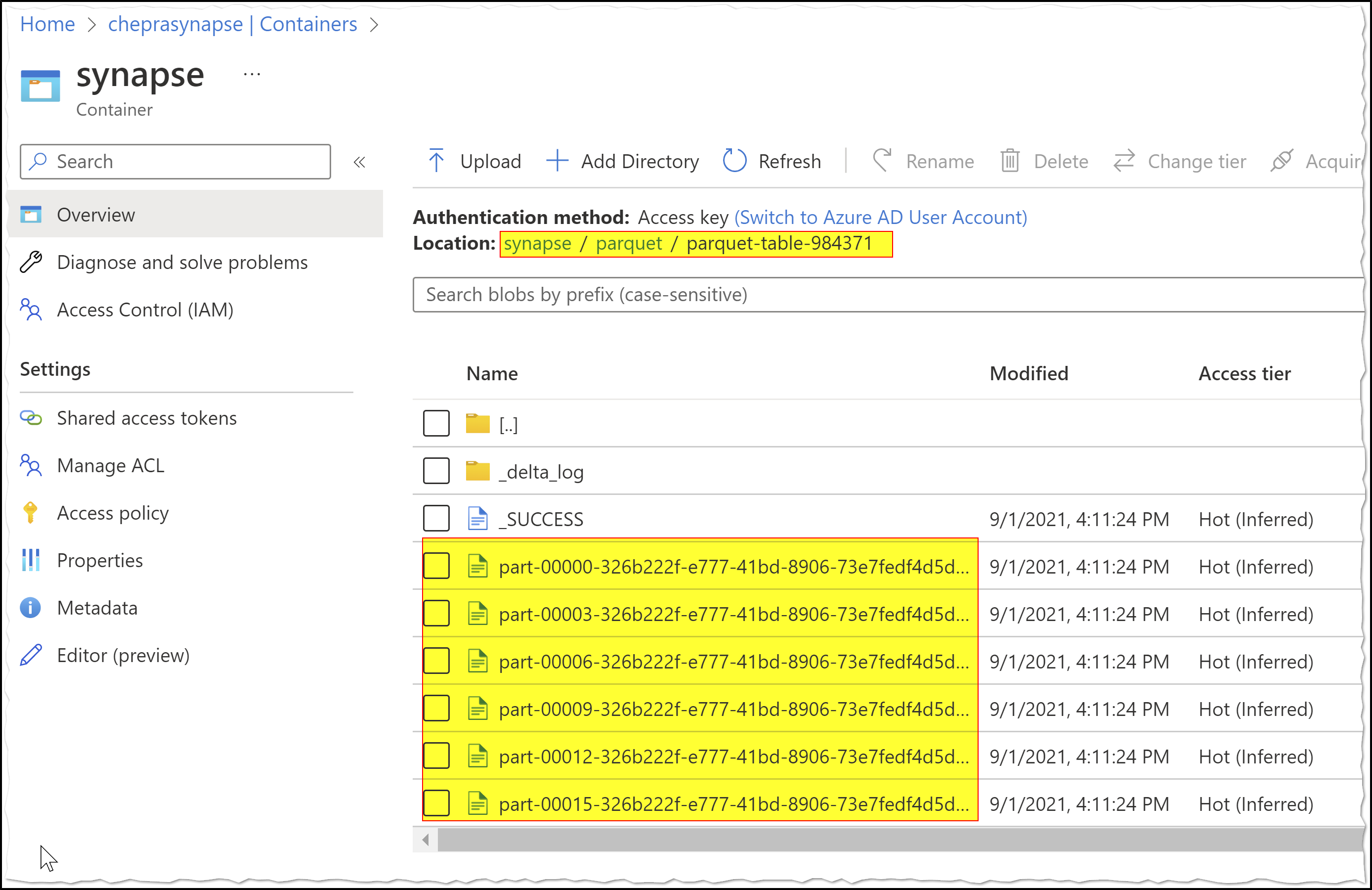
I'm able to read parquet files using spark API or panda as shown below:
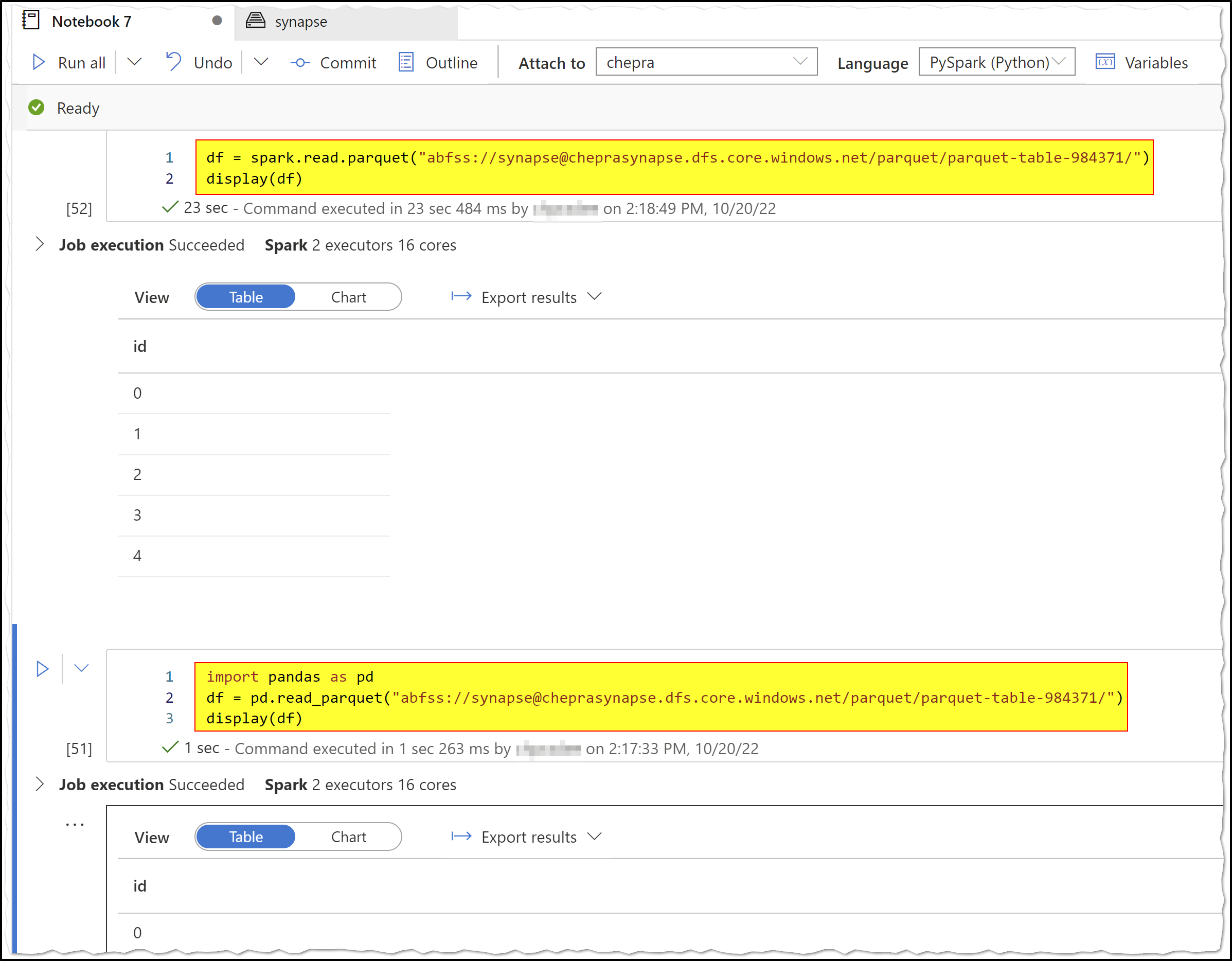
Hope this helps.
@PRADEEPCHEEKATLA , I above method works only when the blob has public access permitted. In my case it's not allowed and so when I try your latest syntax I get the error as
ErrorCode:PublicAccessNotPermitted
Content: <?xml version="1.0" encoding="utf-8"?><Error><Code>PublicAccessNotPermitted</Code><Message>Public access is not permitted on this storage account.
RequestId:32dcca6c-401e-000b-2865-e48f9d000000
I have no troubles to read this file in spark. But I want to avoid spark because for reading one file I don't want to spin up a cluster. Even SAS token does not work.
Pyarrow.parquet and many other libraries says that it's possible to read multiple partitions, but I did not succeed in replicating it and there is no clear example available on the internet.
Hello @Manash ,
I had tested this on the Public access level as
Privateas shown below and it works as excepted.