Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJJ%3C/text%3E%3C/svg%3E)
Hi All,
I'm trying to flatten the following JSON structure in Azure Data Factory so that I can get the data from ‘rows []’ in a tabular format to store in SQL table. The JSON response has columns [] and rows [], where columns [] hold the field names and rows [] hold the corresponding data for these fields. I want the data from columns [].name as the column names and data from rows [] as the rows in the result.
I have tried using an ADF Data Flow & the flatten transformation but couldn’t find a method for the desired result. New to Azure ADF and JSON so any help or suggestions would be much appreciated.
Thanks in advance for your help!
The sample JSON File Structure is below:
{
"id": "XXXX",
"name": "XYZ",
"type": "cost",
"location": null,
"sku": null,
"eTag": null,
"properties": {
"nextLink": null,
"columns": [
{
"name": "Amount",
"type": "Number"
},
{
"name": "Date",
"type": "Number"
},
{
"name": "Group",
"type": "String"
},
{
"name": "Type",
"type": "String"
},
{
"name": "Location",
"type": "String"
},
{
"name": "Currency",
"type": "String"
}
],
"rows": [
[
0.0012,
20220901,
"RAM",
"storage",
"EU",
"GBP"
],
]
}
}
The desired result is:
Amount Date Group Type Location Currency
0. 0012 20220901 RAM storage EU GBP

Hi @Anonymous ,
Welcome to Microsoft Q&A platform and thanks for posting your question here.
As I understand your question, you are trying to copy JSON into SQL table by flattening the complex data.
First of all, row[] has a single nested array within , however at the end of it, there seems to be ',' which is not required here. For processing it , I am removing one level of array . Instead of row[[]] , I am providing row[] . You can follow the same steps on the original source data:
rows[] to unroll by and for the other one, select columns[] to unroll by. 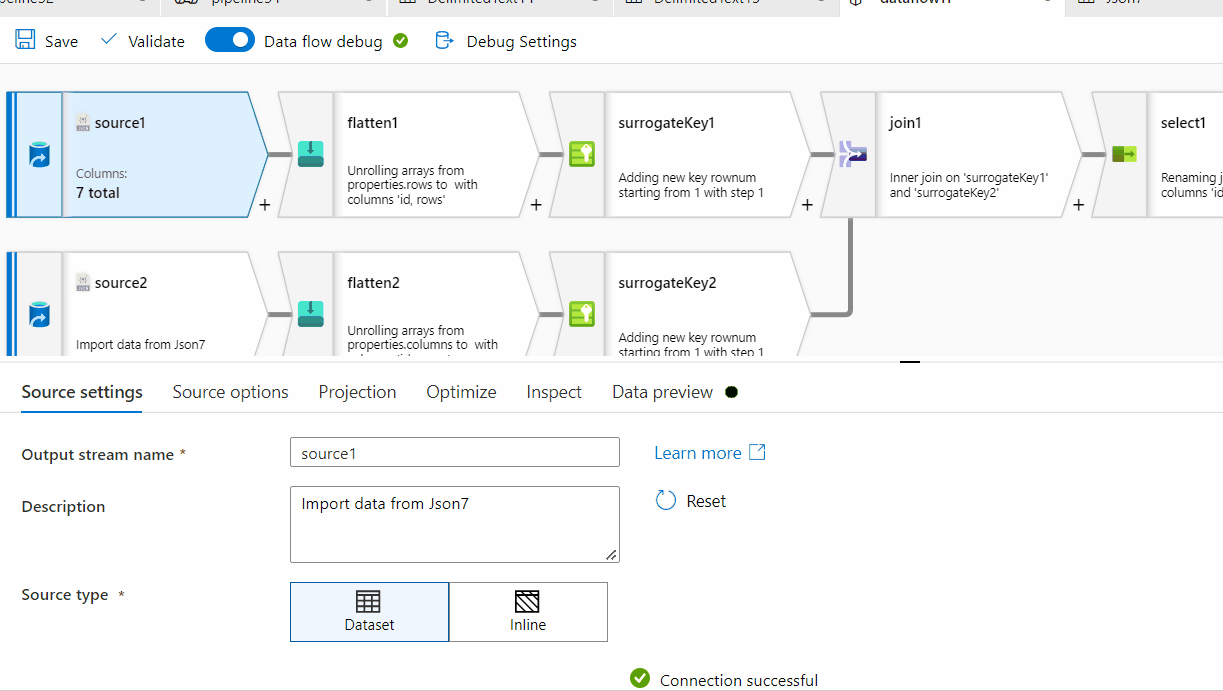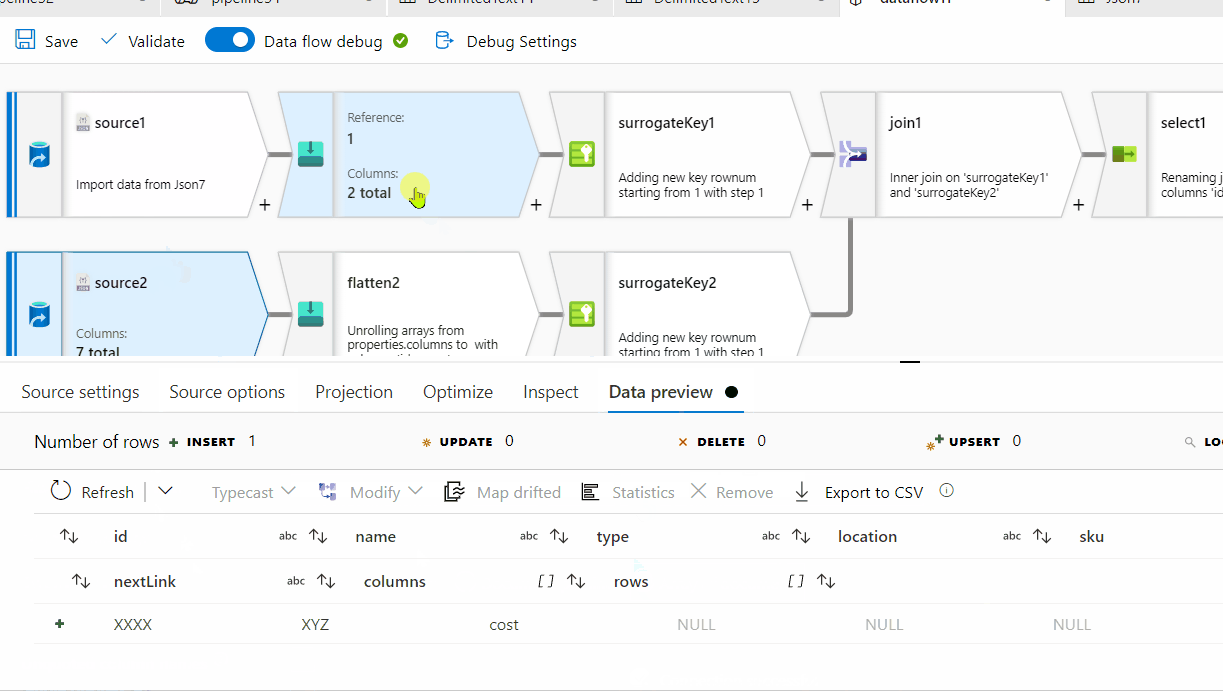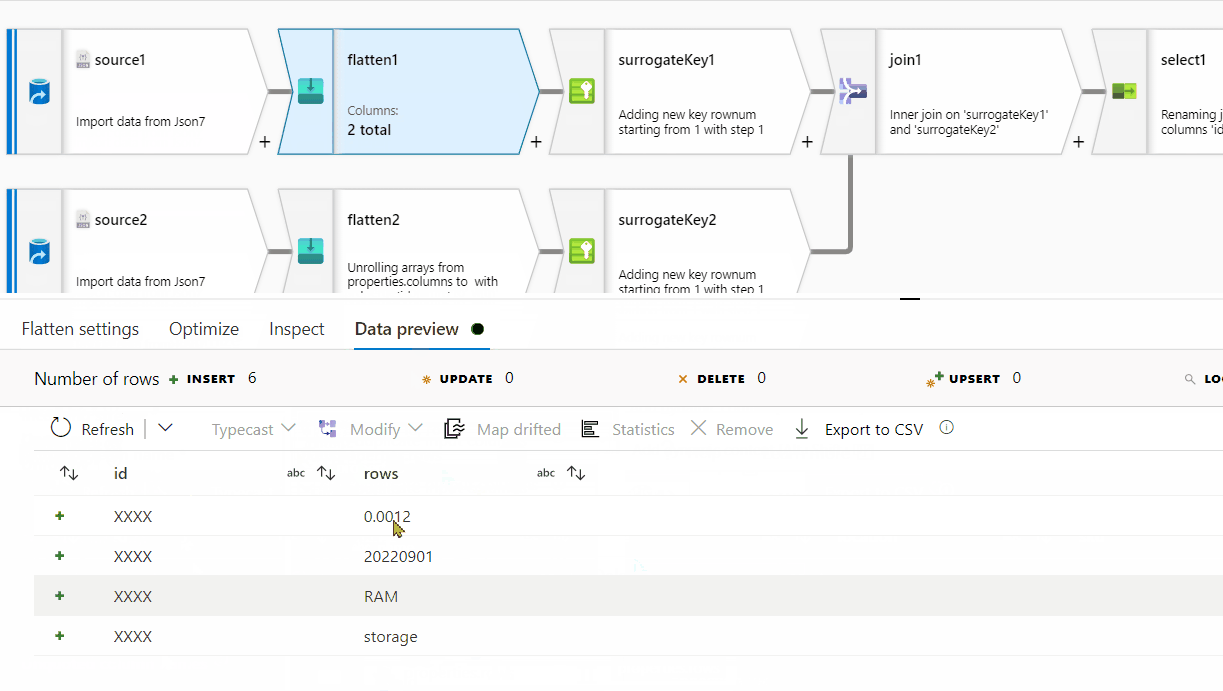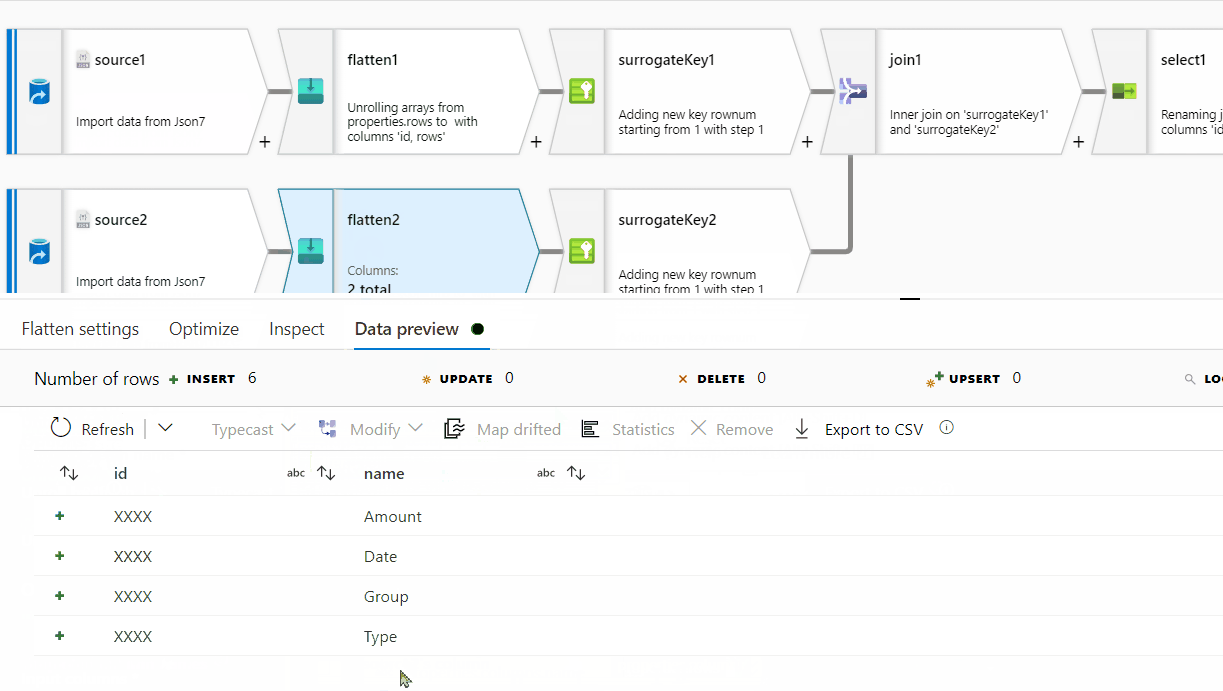
rownum 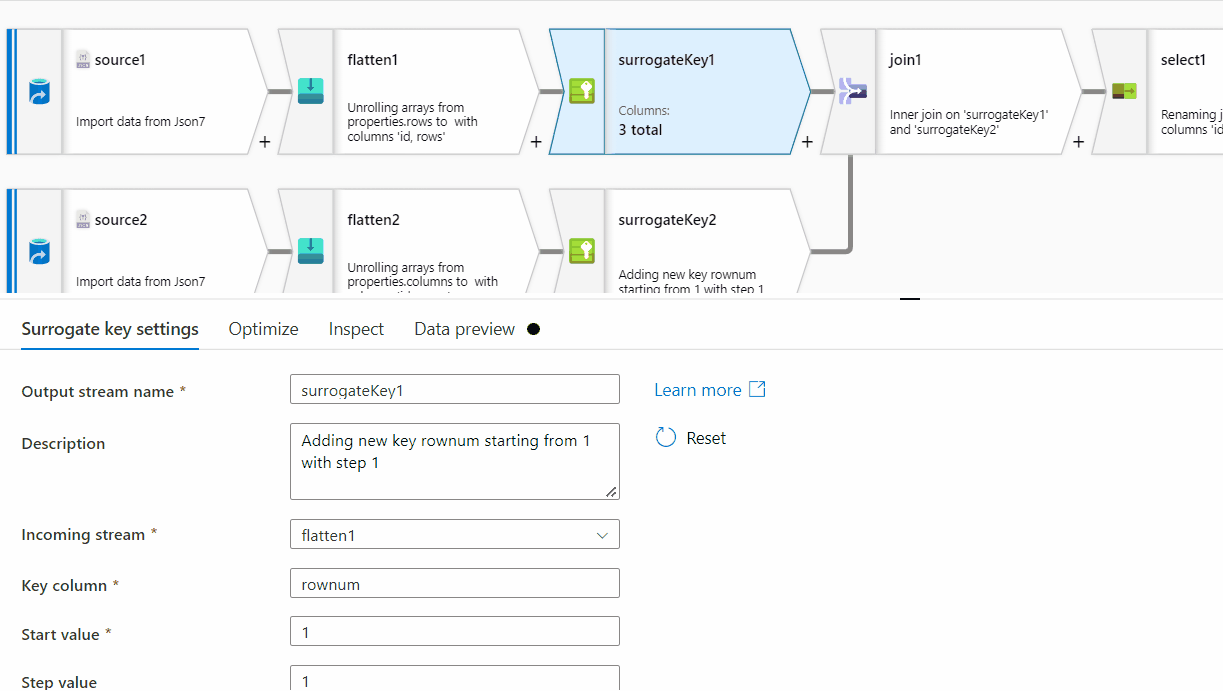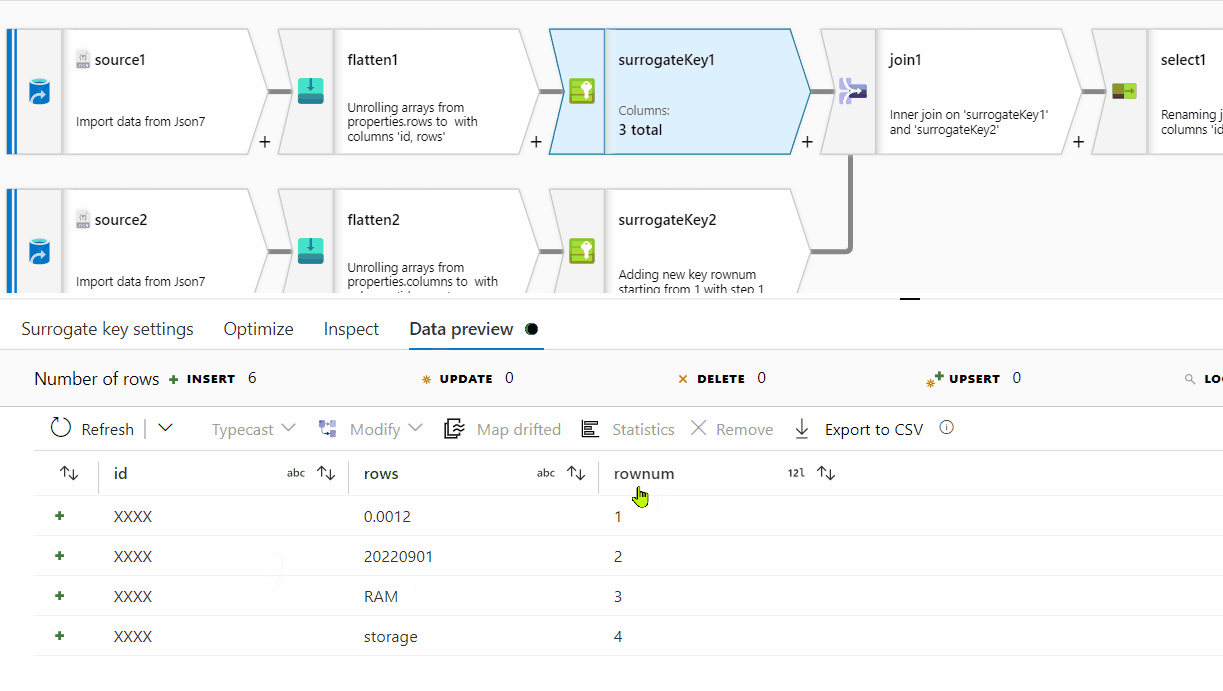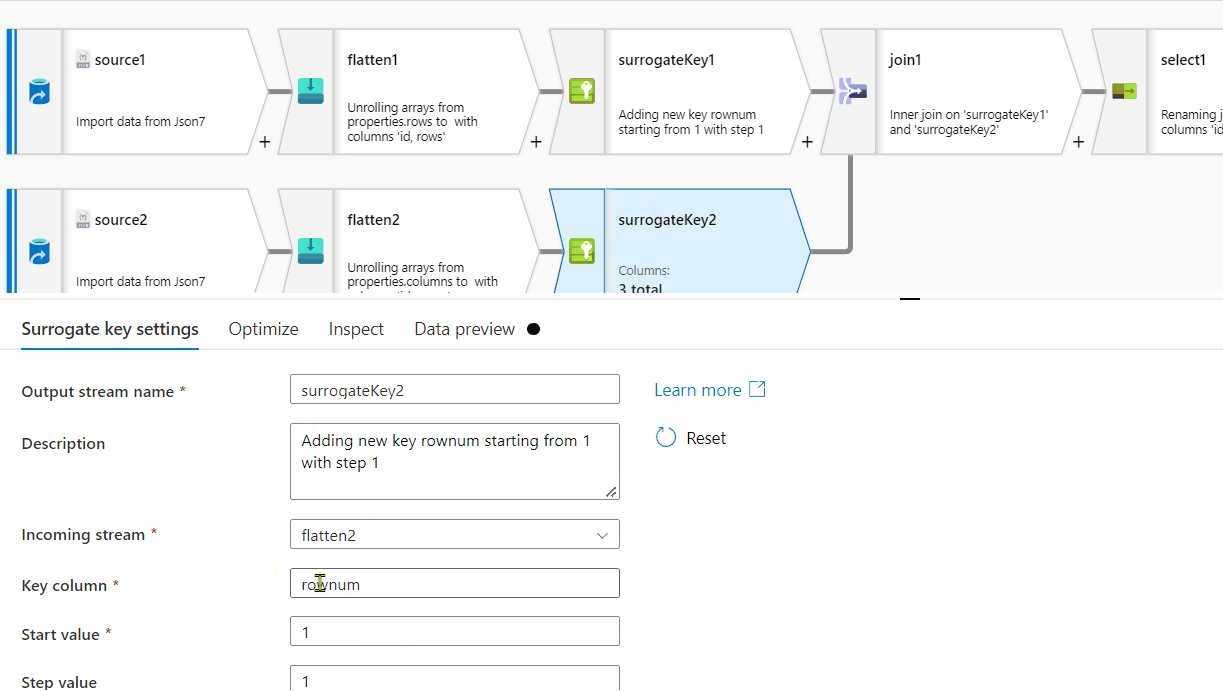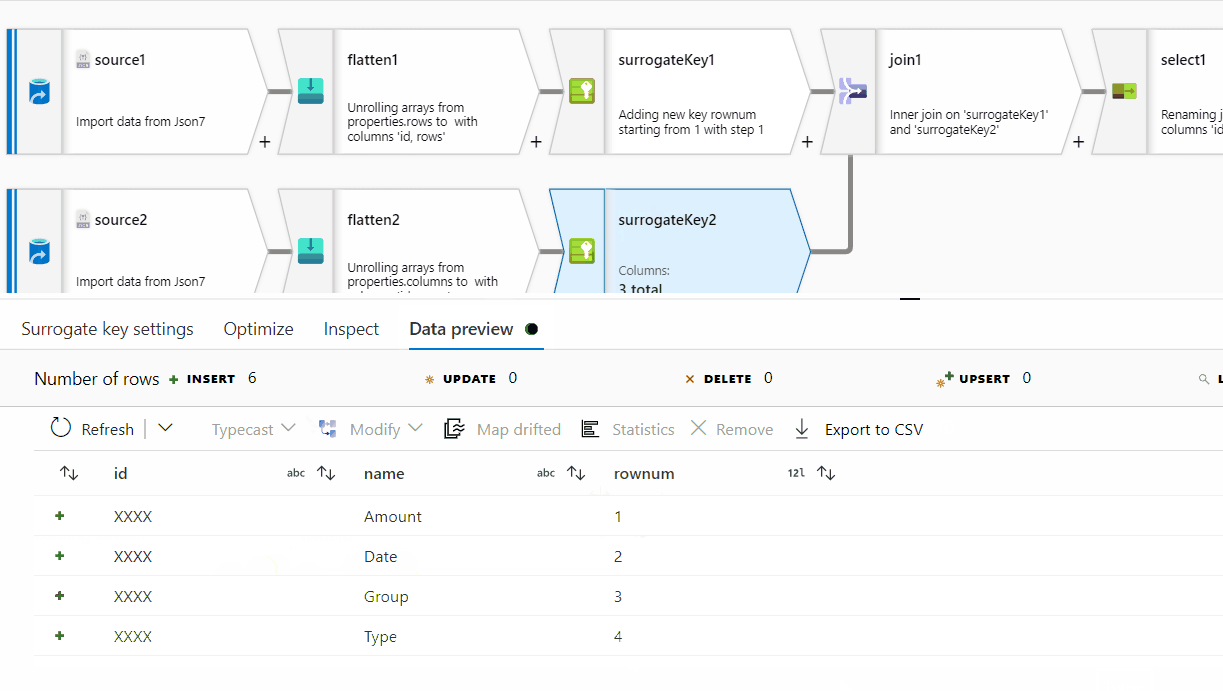
Id and RowNum 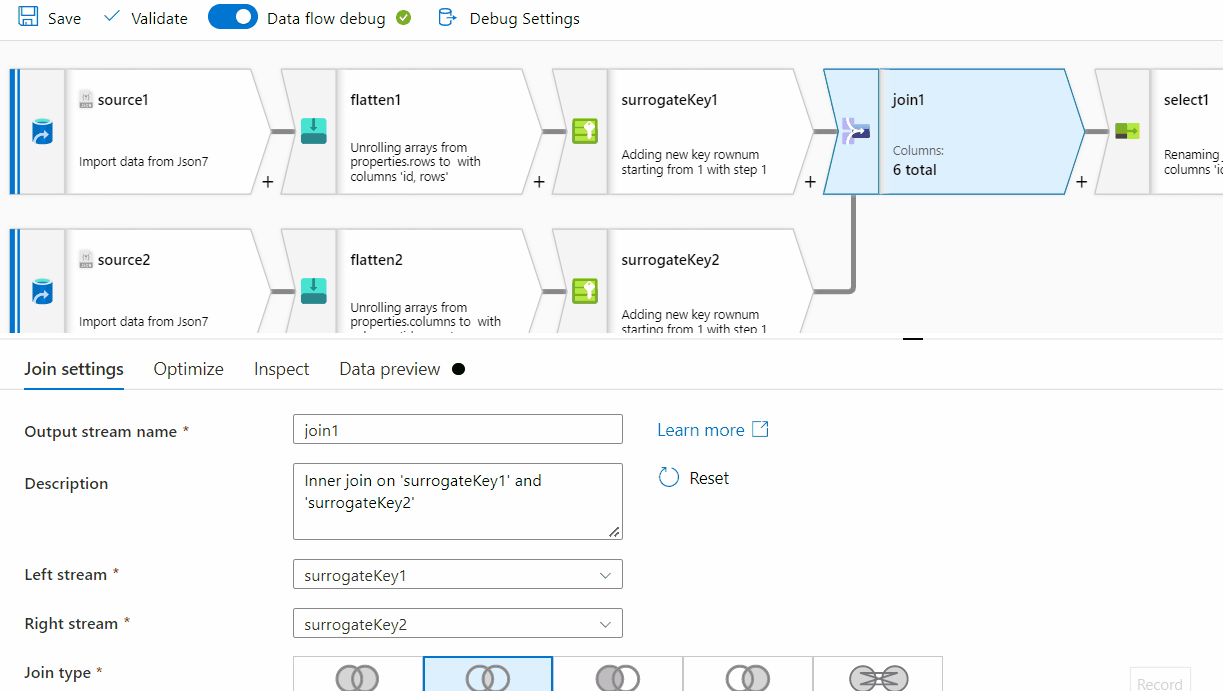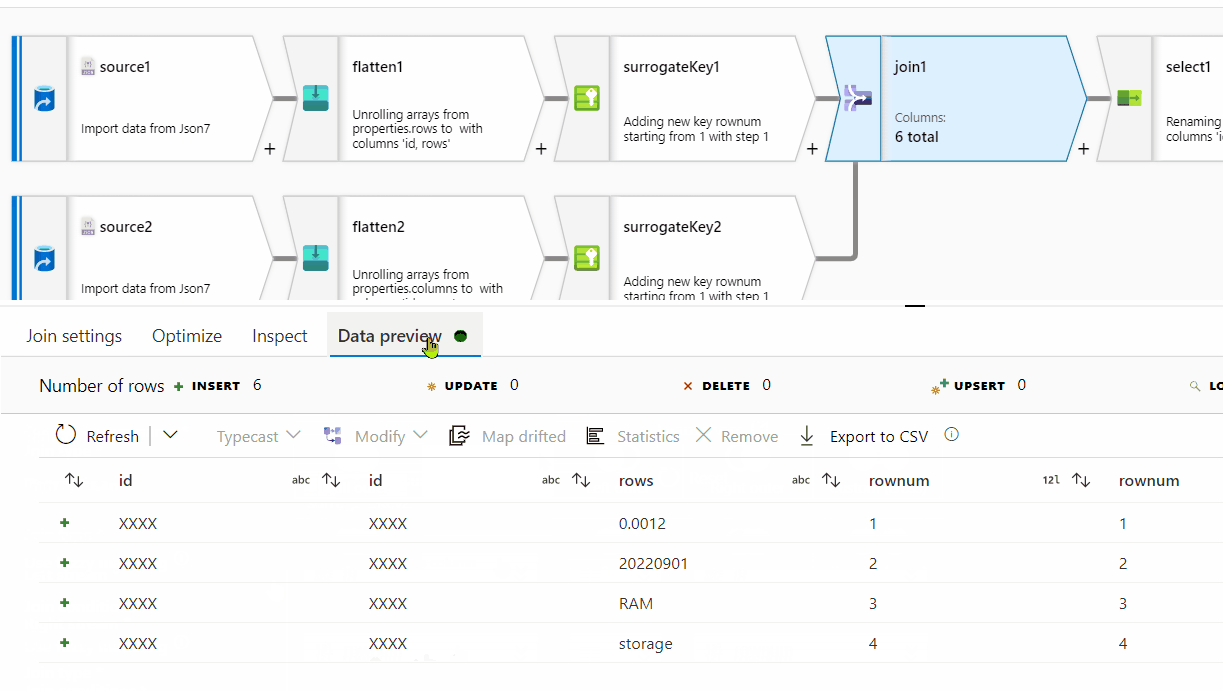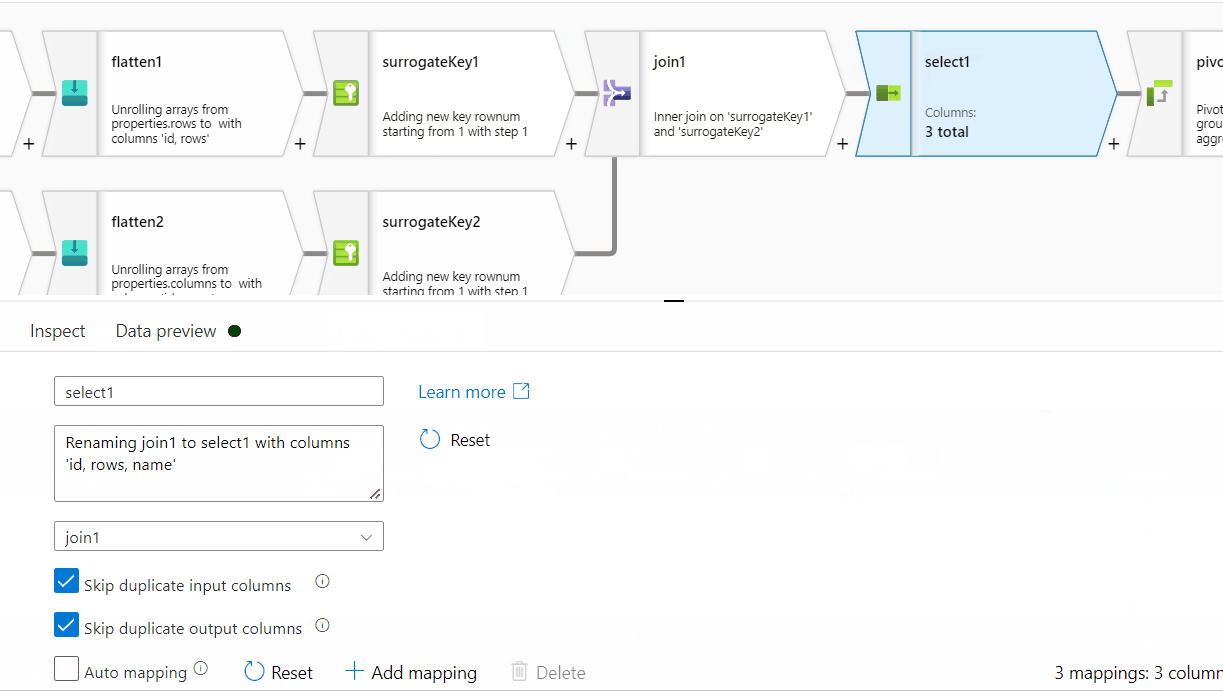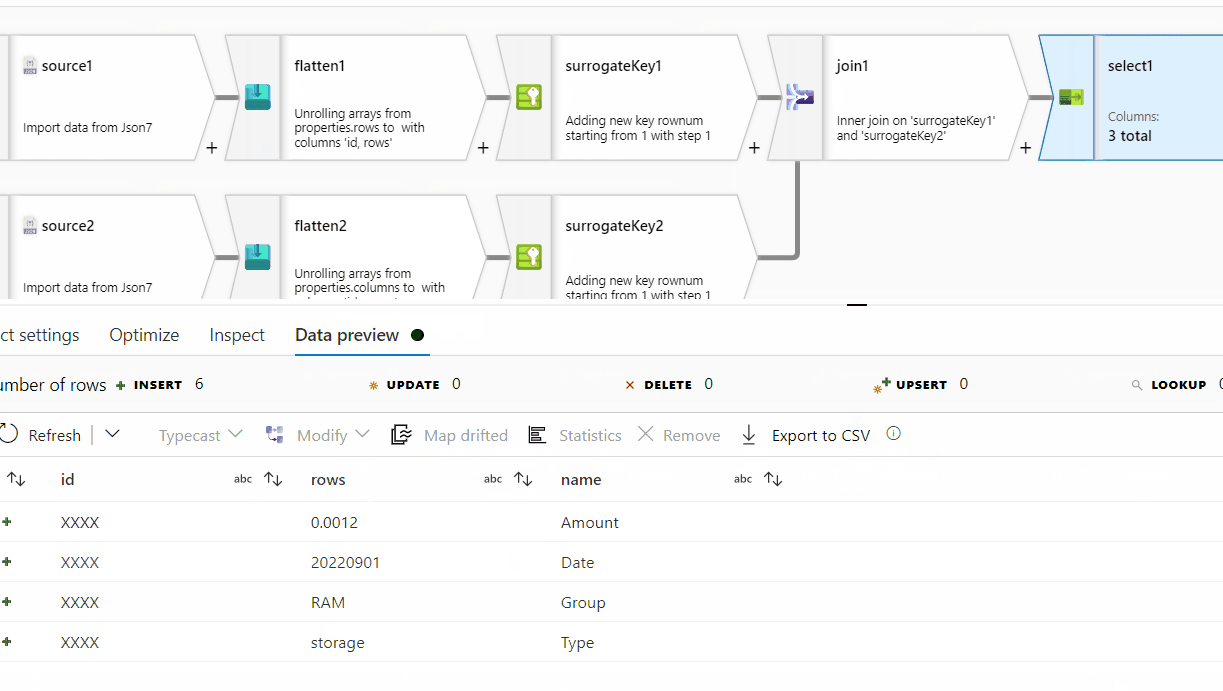
id column . In the Pivot key tab, use name column and in the pivoted columns , provide aggregate function like min(rows) or max(rows) or avg(rows). 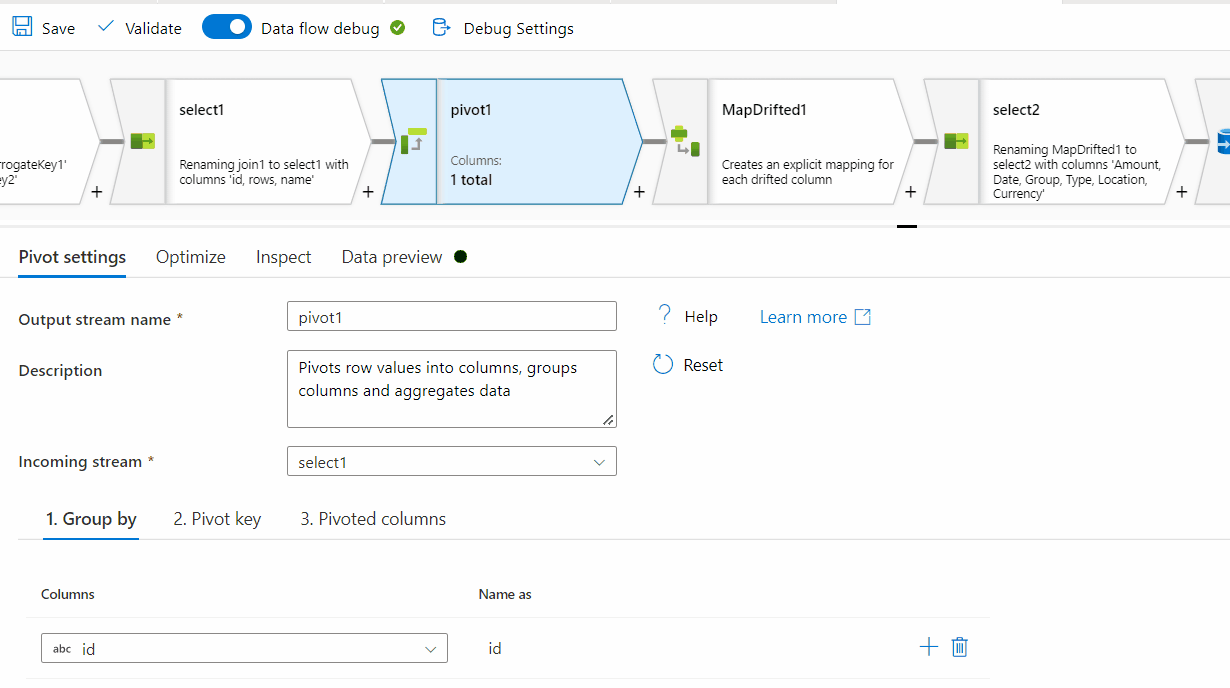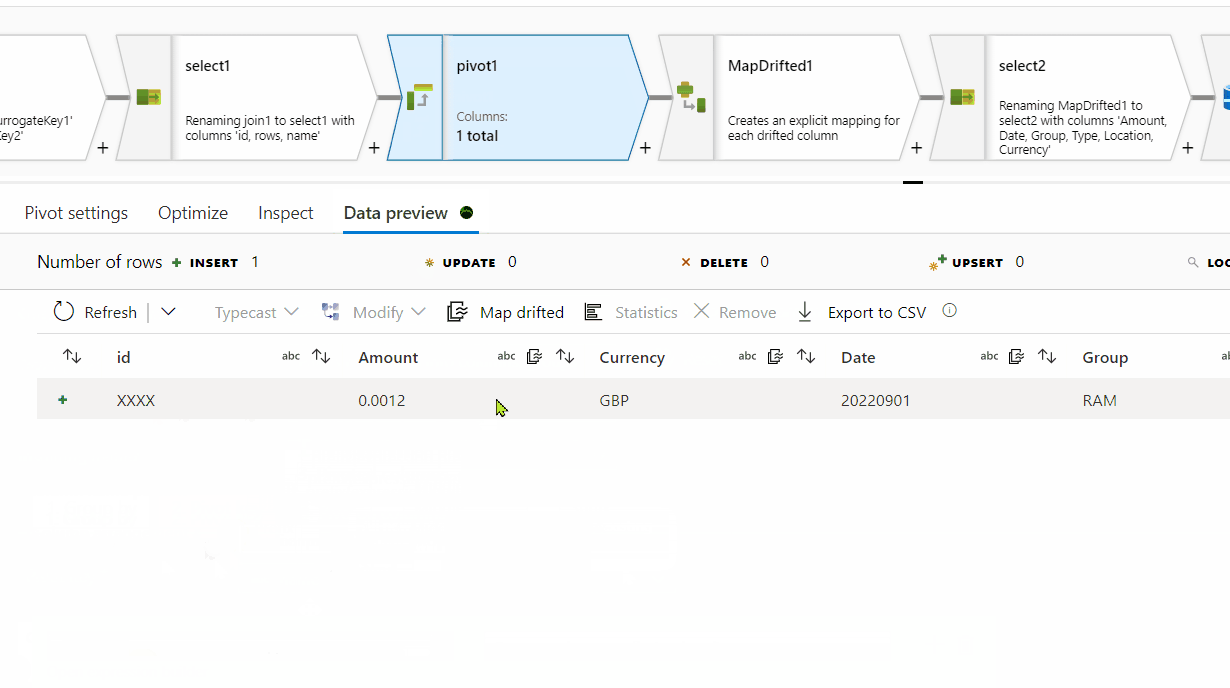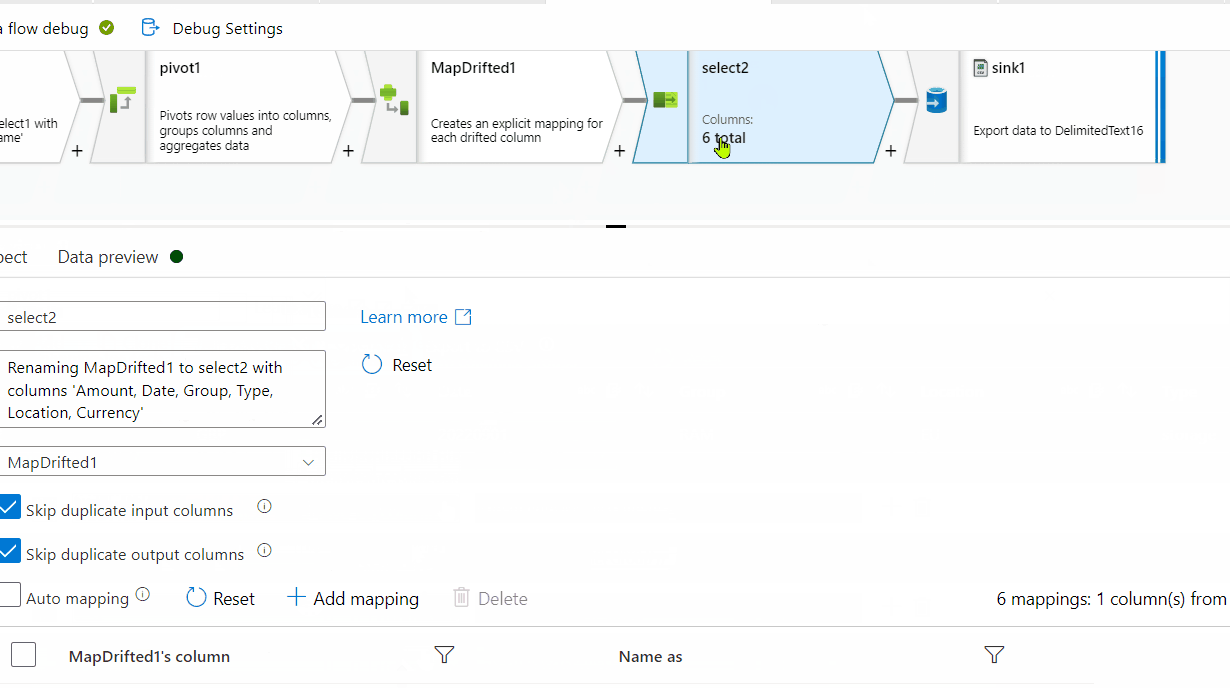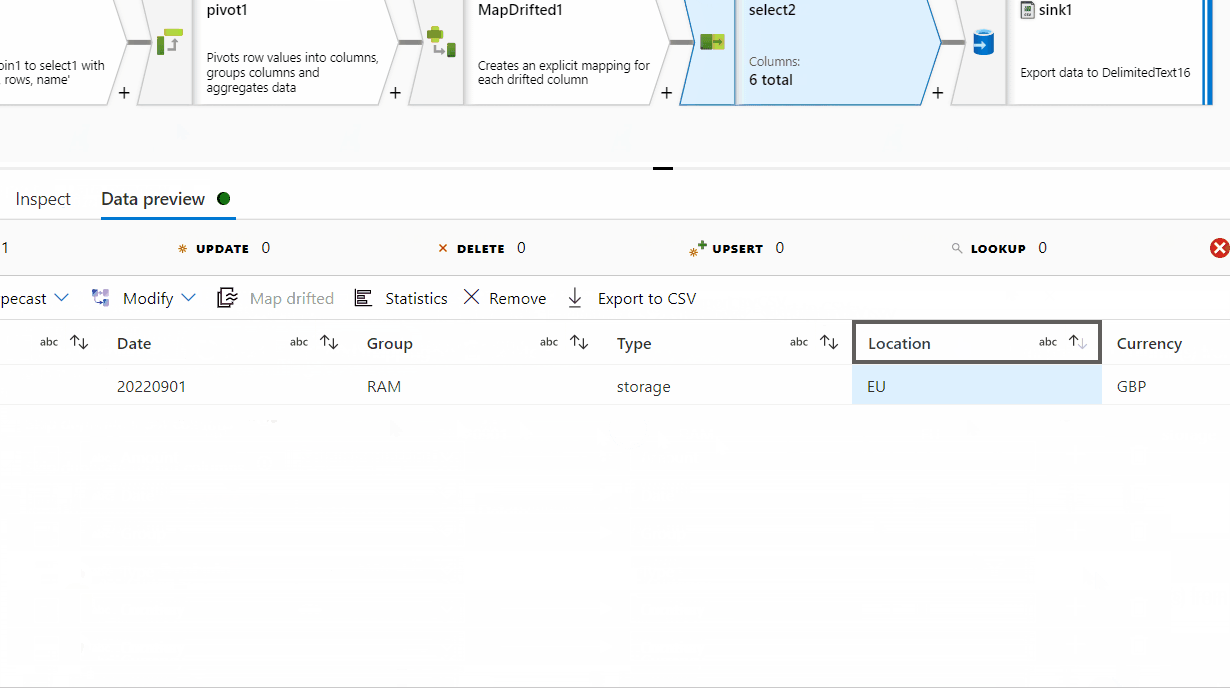
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Thank you so much for your valuable time in resolving my query. It really helped and I am now able to replicate the same.
However, I still need your help with one more query I have in this. This is definitely my mistake while drafting the sample JSON response.
row [] is actually a nested array with more than one group of items. I have around 140 arrays inside row [] in the original JSON response. I was just giving a sample JSON due to the confidentiality of data and forgot to mention that row [] is a nested array row [[]].
I have replicated your solution in ADF and added one more flatten transformation (after flatten1) and flattened the nested row and got the first row of data in output. However, I would like to have multiple rows, as per the real JSON. Could you please help me with the necessary changes to be made in surrogatekey and join transformations.

Thank you very much for your kind help on this.
The sample JSON File Structure is below:
{
"id": "XXXX",
"name": "XYZ",
"type": "cost",
"location": null,
"sku": null,
"eTag": null,
"properties": {
"nextLink": null,
"columns": [
{
"name": "Amount",
"type": "Number"
},
{
"name": "Date",
"type": "Number"
},
{
"name": "Group",
"type": "String"
},
{
"name": "Type",
"type": "String"
},
{
"name": "Location",
"type": "String"
},
{
"name": "Currency",
"type": "String"
}
],
"rows": [
[
0. 0012,
20220901,
"RAM",
"storage",
"EU",
"GBP"
],
[
0. 0015,
20220902,
"VM",
"Compute",
"EU",
"GBP"
],
[
0. 0017,
20220903,
"Disk",
"storage",
"EU",
"GBP"
]
]
}
}
The desired result is: So I should have 140 rows and 6 columns with real source data
Amount Date Group Type Location Currency
0. 0012 20220901 RAM storage EU GBP
0. 0015 20220902 VM Compute EU GBP
0. 0017 20220903 Disk storage EU GBP