Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJJ%3C/text%3E%3C/svg%3E)
Hi All,
I'm trying to flatten the following JSON structure in Azure Data Factory so that I can get the data from ‘rows [[]]’ in a tabular format to store in SQL table. The JSON response has columns [] and rows [[]], where columns [] hold the field names and rows [[]] hold the corresponding data for these fields. I want the data from columns [].name as the column names and data from rows [[]] as the rows in the result.
I have already raised this query in the forum and got a valuable solution. However, this is a multi-array, I am still couldn’t copy the JSON into SQL table.
Thanks in advance for your help!
The sample JSON File Structure is below:
{
"id": "XXXX",
"name": "XYZ",
"type": "cost",
"location": null,
"sku": null,
"eTag": null,
"properties": {
"nextLink": null,
"columns": [
{
"name": "Amount",
"type": "Number"
},
{
"name": "Date",
"type": "Number"
},
{
"name": "Group",
"type": "String"
},
{
"name": "Type",
"type": "String"
},
{
"name": "Location",
"type": "String"
},
{
"name": "Currency",
"type": "String"
}
],
"rows": [
[
0. 0012,
20220901,
"RAM",
"storage",
"EU",
"GBP"
],
[
0. 0015,
20220902,
"VM",
"Compute",
"EU",
"GBP"
],
[
0. 0017,
20220903,
"Disk",
"storage",
"EU",
"GBP"
]
]
}
}
The desired result is:
Amount Date Group Type Location Currency
0. 0012 20220901 RAM storage EU GBP
0. 0015 20220902 VM Compute EU GBP
0. 0017 20220903 Disk storage EU GBP
(I will have 140 rows and 6 columns with real source data)

Hi @Anonymous ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here. I tried to create the dataflow and transforming the above JSON and am successfully able to achieve that. However, there are a lots of bits and pieces involved which makes it complex. Kindly try the below steps :
1. Add two source transformations pointing to the same source json. Select 'Array of documents' in the json settings for both the sources.
2. Add flatten transformations to each of the sources . For one flatten transformation, select rows[[]] to unroll by and for the other one, select columns[] to unroll by.
3. Add another flatten transformation to unroll row[] in the first branch so that we get individual rows out of the nested array.

4. Add surrogate key transformation to both the sources to create a incremental identity column RowNum
5. In the first branch , add a derived column transformation and create a new column , say Rankingwith this expression: iif(RowNum%6==0,6,toInteger(RowNum%6)) . This would assign ranking to the data based on the number of columns(i.e. 6). That means this column will have data like 1,2,3,4,5,6 again 1,2,3,4,5,6 upto the last row. This will help in joining the two sources

6. Add Join transformation and select join type as 'inner join' based on Ranking column and RowNum column coming from below branch

7. Add Select transformation and deselect the unwanted columns. Keep only rows and name
8. Add Surrogate key transformation to create incremental identity column called NewId
9. Add derived column transformation to create a new dummy column with the value : iif(NewID%3==0,3,toInteger(NewID%3)) . Here 3 is based on the number of rows. In your case, you can either hardcode it by giving 140 instead of 3 , or you can parameterize it so that this value would be passed via pipeline parameter during the runtime so that when the number of rows changes , you don't have to update anything in dataflow, rather you can pass the number of rows while debugging the pipeline.

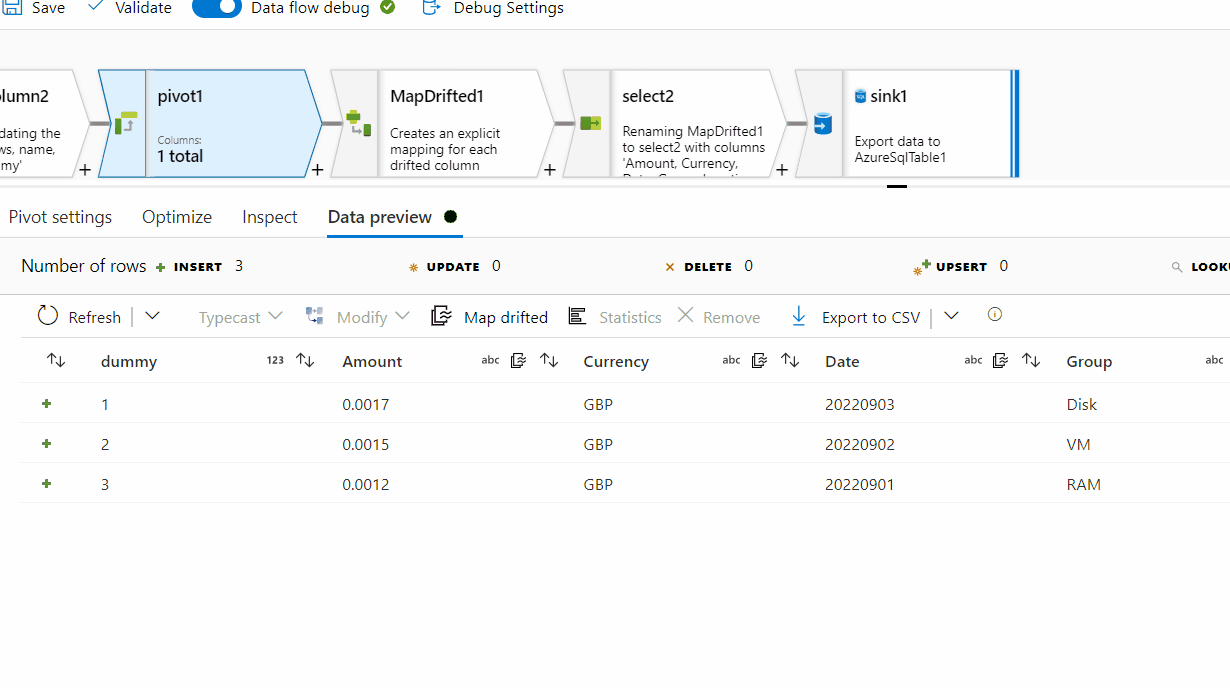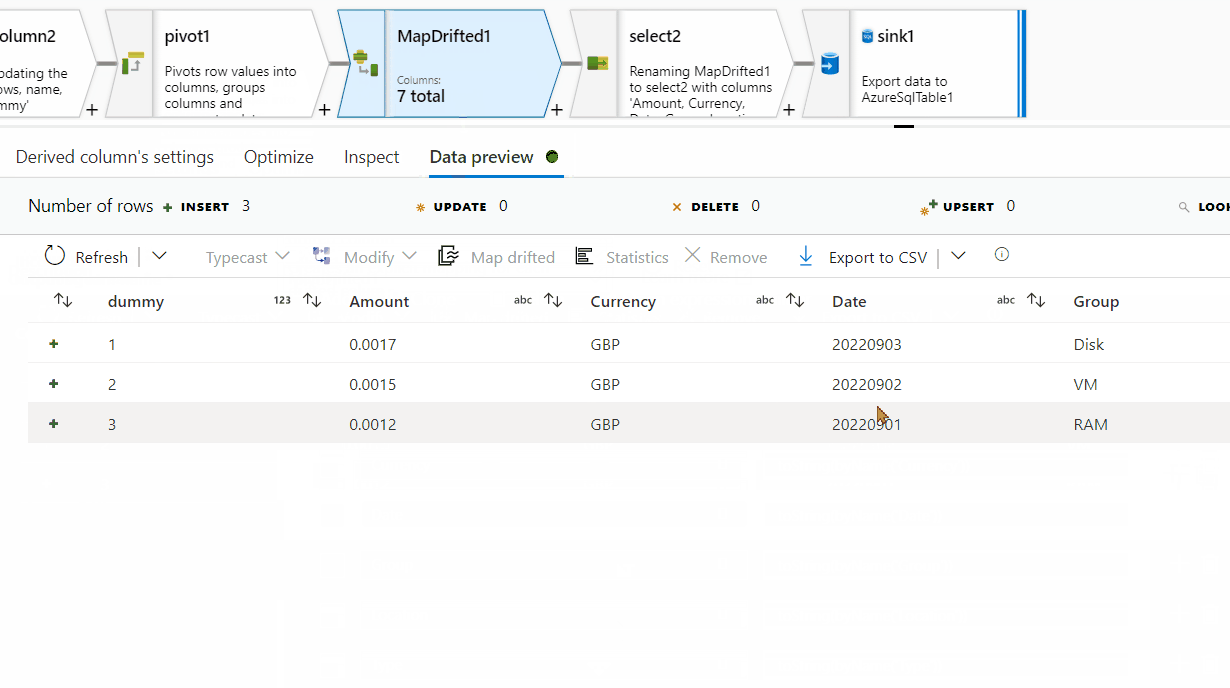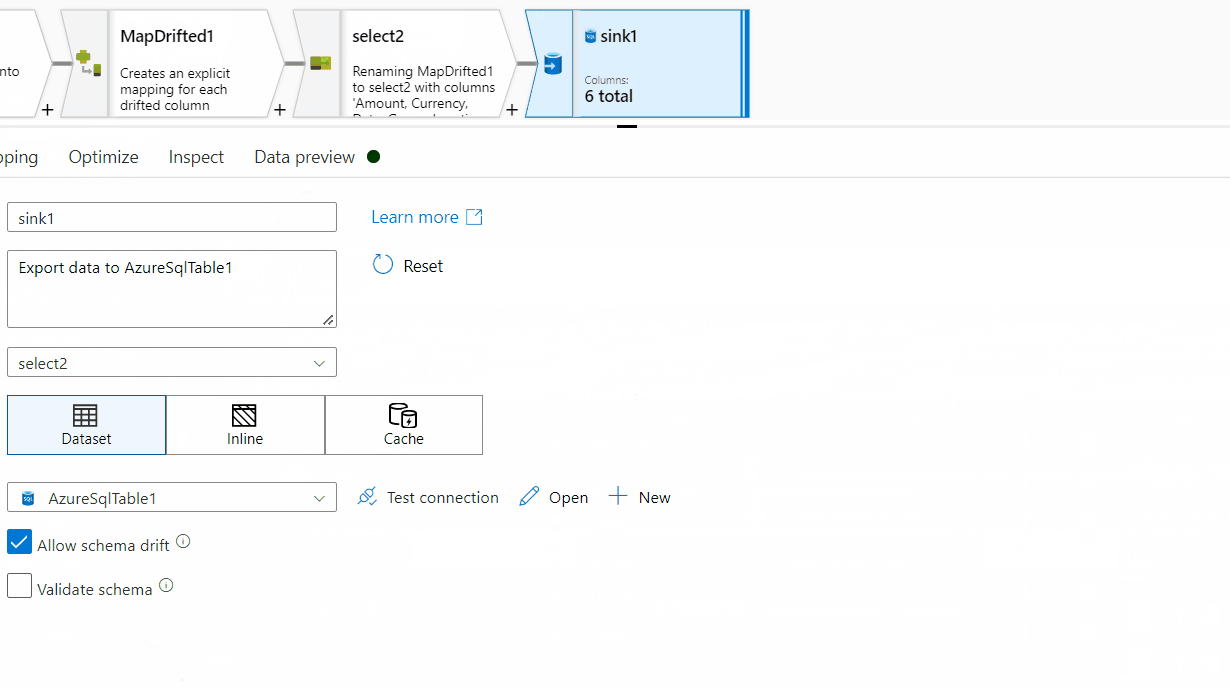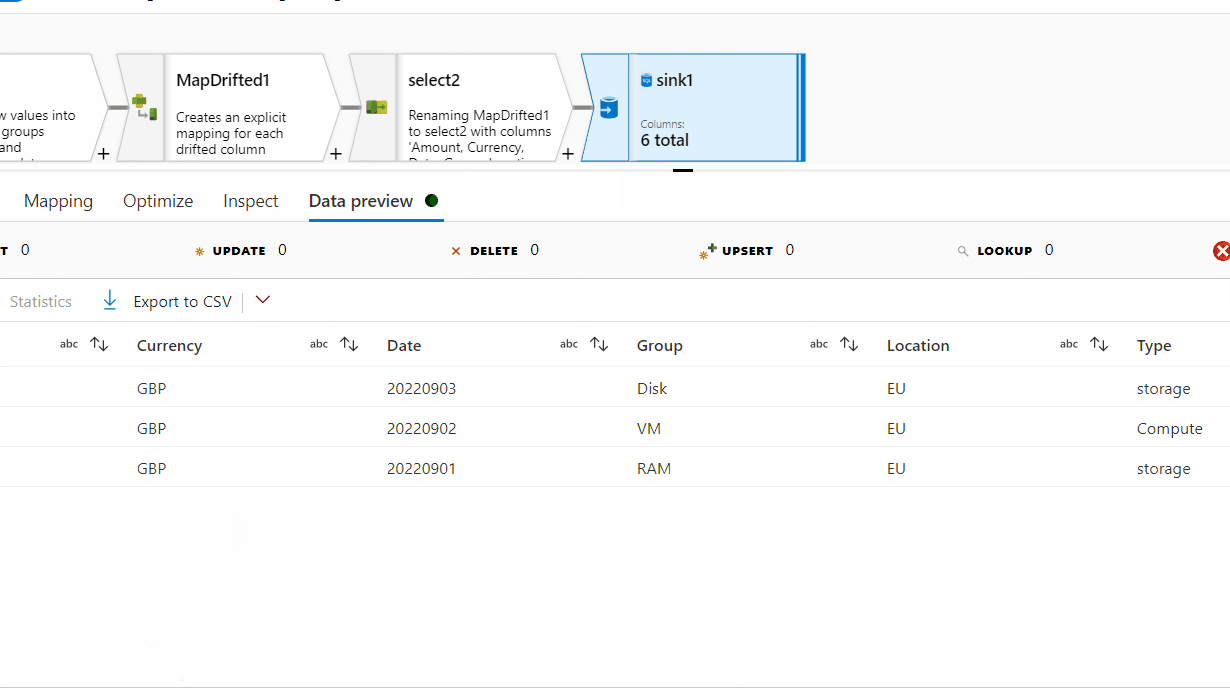
10. Add Pivot transformation to group by using dummy column . In pivot key tab, select name column and in pivoted columns provide this expression : first(rows)

11. In mapping tab of pivot transformation, click on 'Map drifted' , it would add another transformation and import the current schema after pivot
12. Add select transformation and deselect the dummy column which is not needed
13. Add Sink transformation to load the data into SQL table.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button and take satisfaction survey whenever the information provided helps you.
button and take satisfaction survey whenever the information provided helps you.
Thank you for your help. It worked.