Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,696 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHD%3C/text%3E%3C/svg%3E)
I am trying to execute synapse mapping dataflow inside for each loop. Everytime dataflow activity gets executed it is taking minimum 3 minutes to start the cluster. So If loop executes for 5 times it will take extra 12 to 15 minutes. How avoid this cluster startup time for each iteration.

Hi @Anonymous ,
Just checking in to see if the below answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi @Anonymous ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
As per my understanding, you want to reduce the execution time of the pipeline by optimizing spark cluster spin up time. Please correct me if my understanding about your query is wrong.
You can use the Time to live feature available in ADF and Synapse
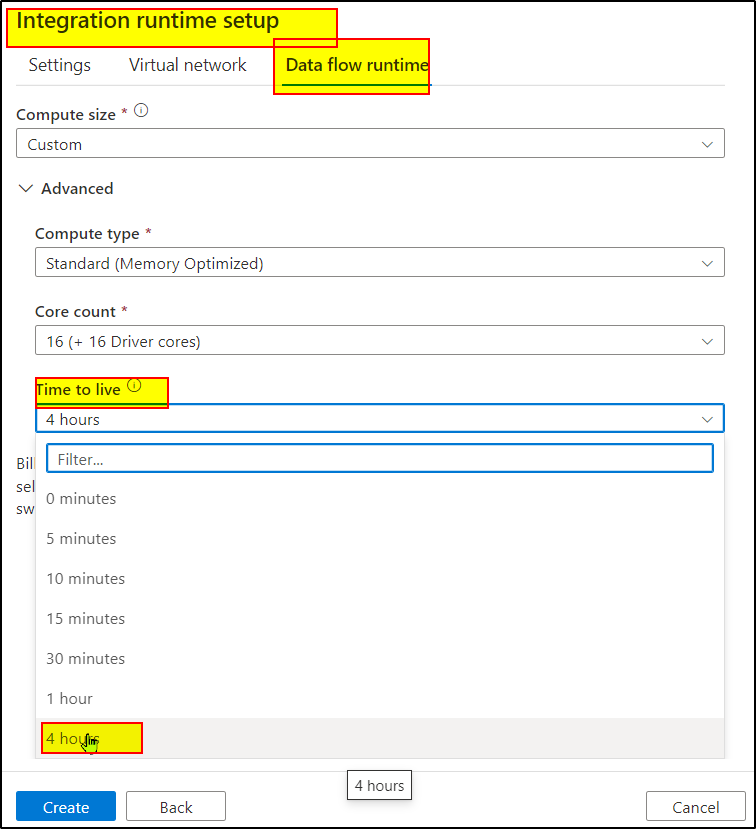
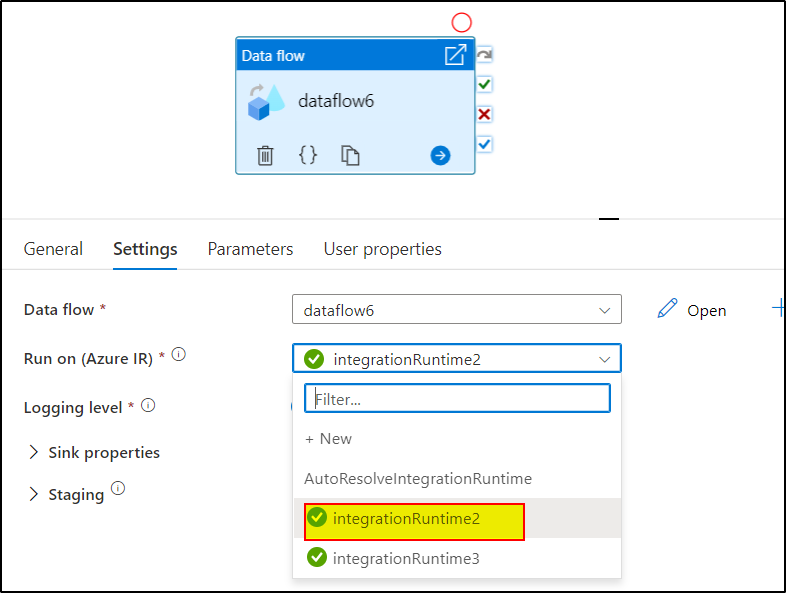
For more information, kindly check the below resources: TTL to reduce Data Flow activity times
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.