Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,378 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ED%3C/text%3E%3C/svg%3E)
Hi Community
I have SQL Query which i am trying to do in azure Synapse motebook using delta tables which have some joins and multiple where conditions? SQL Query Looks Like this:
I have loaded the file data into dataframes first and from the dataframes i am loading it into delta tables:
df_1.write.mode("overwrite").format("delta").saveAsTable('TABLE1')
df_2.write.mode("overwrite").format("delta").saveAsTable('TABLE2')
After that i am running a QUERY:
**%sql
MERGE INTO campaign_data using Institute_data
ON TABLE1.STUDENTID=TABLE2.COLLEGEID and TABLE1.ATTENDANCE =='' and TABLE2.PERFORMANCE = '' and TABLE1.PLAYSPORTS !=''
WHEN MATCHED THEN UPDATE SET TABLE1.GIVE_MARKS = '1';**
THE actual SQL Query:
**
UPDATE TABLE1 INNER JOIN TABLE2 ON TABLE1.STUDENTID = TABLE2.COLLEGEID
SET TABLE1.GIVE_MARKS = "1"
WHERE (((TABLE1.ATTENDANCE) Is Null) AND ((TABLE2.PERFORMANCE) Is Null) AND
((TABLE1.PLAYSPORTS) Is Not Null));
**
When i am running the Query in synapse notebook , it is throwing error like
MERGE INTO campaign_data using Institute_data
^
SyntaxError: invalid syntax

Hi @Devender ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
As I understand your ask, you are trying to perform MERGE between two delta tables in Synapse sql . However, it is throwing 'Invalid Syntax' error. Kindly let me know if that is not the case.
As can be seen in the query you have provided, you are assigning delta table names as 'TABLE1' and 'TABLE2' . However, in the MERGE statement , you have provided target table name as 'campaign_data' and source table name as 'Institute_data' . Could you please try changing them to 'TABLE1' and 'TABLE2' respectively .
Also in the condition: TABLE1.ATTENDANCE =='' , please remove one of the = symbols.
Please let me know how it goes. Thankyou.
Hi @AnnuKumari-MSFT ,
thanks for your response, i will check and will let you know if any issue is there
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @Devender ,
Just to add what @AnnuKumari-MSFT called out .
The SQL MERGE feature was implement in SPARK 3.0 and above , so please make sure that you check that ( I took my half day ) .
I was checking on Synapse Spark pool .
This is what I tried .
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import expr
from delta.tables import *Create spark session
table1 = [(1,'100','Yes',10),(2,'','Yes',10),(3,'50','',10)]
table2 = [(1,'Good'),(2,''),(3,'bad')]
table1columns= ["STUDENTID","ATTENDANCE","PLAYSPORTS","GIVEMARKS"]
table2columns= ["COLLEGEID","PERFORMANCE"]
df1 = spark.createDataFrame(data = table1, schema = table1columns)
df2 = spark.createDataFrame(data = table2, schema = table2columns)
df1.printSchema()
df1.show(truncate=False)
df2.printSchema()
df2.show(truncate=False)
df1.write.mode("overwrite").format("delta").saveAsTable('campaign_data')
df2.write.mode("overwrite").format("delta").saveAsTable('Institute_data')
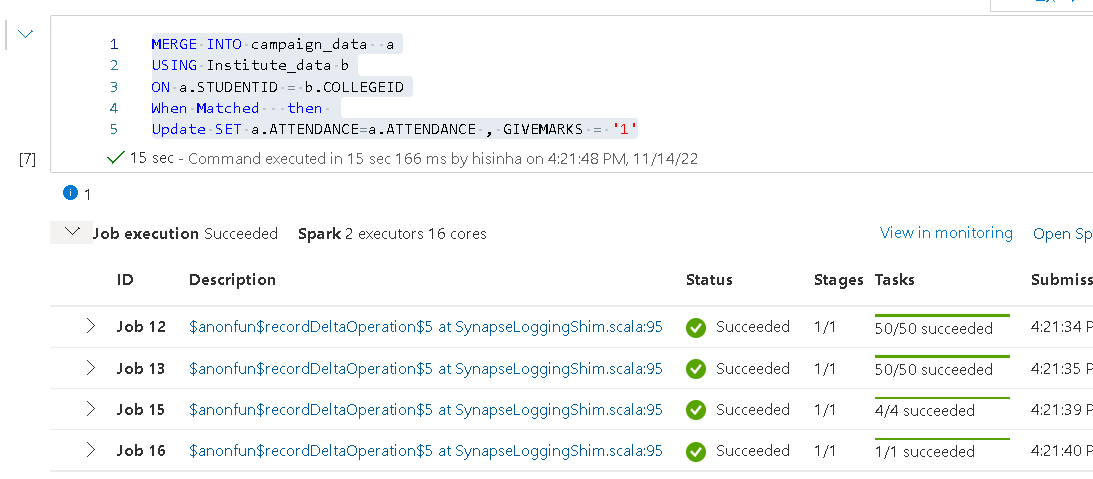
On a different notebook i tried this pysql ( You can add the logic as you mentioned )
MERGE INTO campaign_data a
USING Institute_data b
ON a.STUDENTID = b.COLLEGEID
When Matched then
Update SET a.ATTENDANCE=a.ATTENDANCE , GIVEMARKS = '1'
Please do let me if you have any queries.
Thanks
Himanshu
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Devender ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @Devender ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others .
If you have any question relating to the current thread, please do let us know and we will try out best to help you.
In case if you have any other question on a different issue, we request you to open a new thread .
Thanks
Himanshu