Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERR%3C/text%3E%3C/svg%3E)
Hi Team,
Could you help me out with below Scenario of ADF?
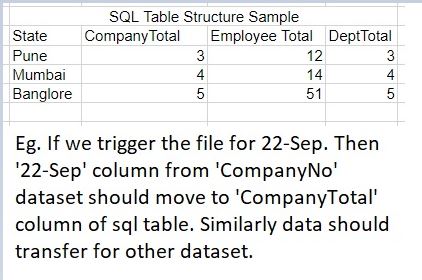
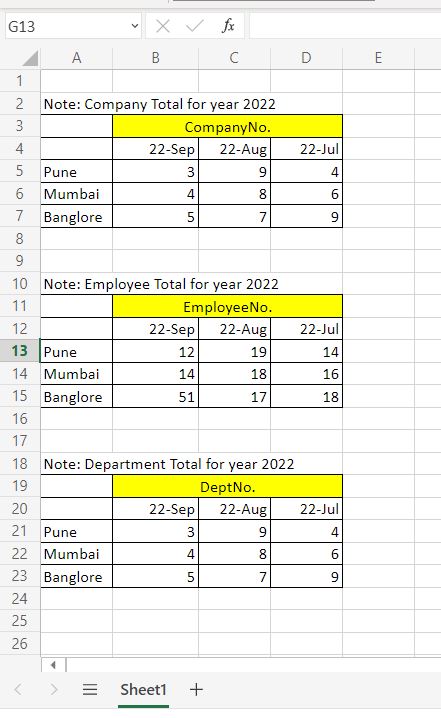
I have a single Excel file with just one tab, as displayed below with approx. same format and that tab contains three datasets. We want to move this data to a SQL table using ADF/data flow. With the following conditions, if we trigger the data by considering any Month that is present on the sheet. Then only that column should transfer to the SQL table.
For example, while triggering, if we pass the 22-Sep (Column Present in datasets), then only the 22-Sep column should be moved from the entire dataset to the given columns of SQL table as shown in attached image.
let me know if you required any further inputs.

Hi @Anonymous ,
Just checking in to see if the below answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi @Anonymous ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
As I understand your query, you want to fetch the data from three datasets within same excel sheet based on the input dates. Please let me know if my understanding about the ask is incorrect.
To achieve the requirement, we need to use two dataflows where we need to use .csv files as intermediate storage . You can follow the below steps in mapping dataflow:
1. Add source transformation and point the dataset to the excel sheet having schema imported and preview the data.
2. Add filter transformation to filter out the rows having 'Note' values as it is not required as well as the dataset name i.e companyno, empno,deptno. Use this expression: not(like(Column_1,'Note%')) || not(isNull(toDate(Column_2)))
3. Add surrogate key transformation to create an identity column Id which will assign an incremental unique value to corresponding rows.
4. Add conditional split transformation to bifurcate the data into multiple groups based on the below conditions: Id>=1 && Id<= 4 , Id>=5 && Id<= 9 and default that will have Id>=10
5. Add select transformation and deselect Id column from all three streams.
6. Add sink transformation to each of the streams and select inline dataset so that it doesn't create too many physical datasets. Provide folderpath , filename in outputtosinglefile option and set single partition.
In second dataflow,
_c0 column. Provide columnnames in unpivot key tab and unpivoted column tab. inputdate with string datatype. Add an alter row transformation and select 'Update if' condition having this expression: dates==$inputdate _c0 --> state, datacol--> companytotal . Similarly, for second branch, map _c0 --> state, datacol--> employee and for third branch, _c0 --> state, datacol--> depttotal 
Now, create an ADF pipeline and call both the dataflows.
Inputdate having string datatype. In dataflow2, parameter tab, provide value for the dataflow parameter from the pipeline parameter as @pipeline().parameters.Inputdate and check the expression checkbox. 
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Thank you for your answer. I am grateful for your support and explanation in very simple words. I have accepted the answer. Consider my rating as 5 stars. Sorry for replying late.
Thanks a lot.
Regards,
Rohit S.