Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,640 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

Hi ,
I have these different folders inside aws S3 bucket

Inside each folder i have parquet files for each month
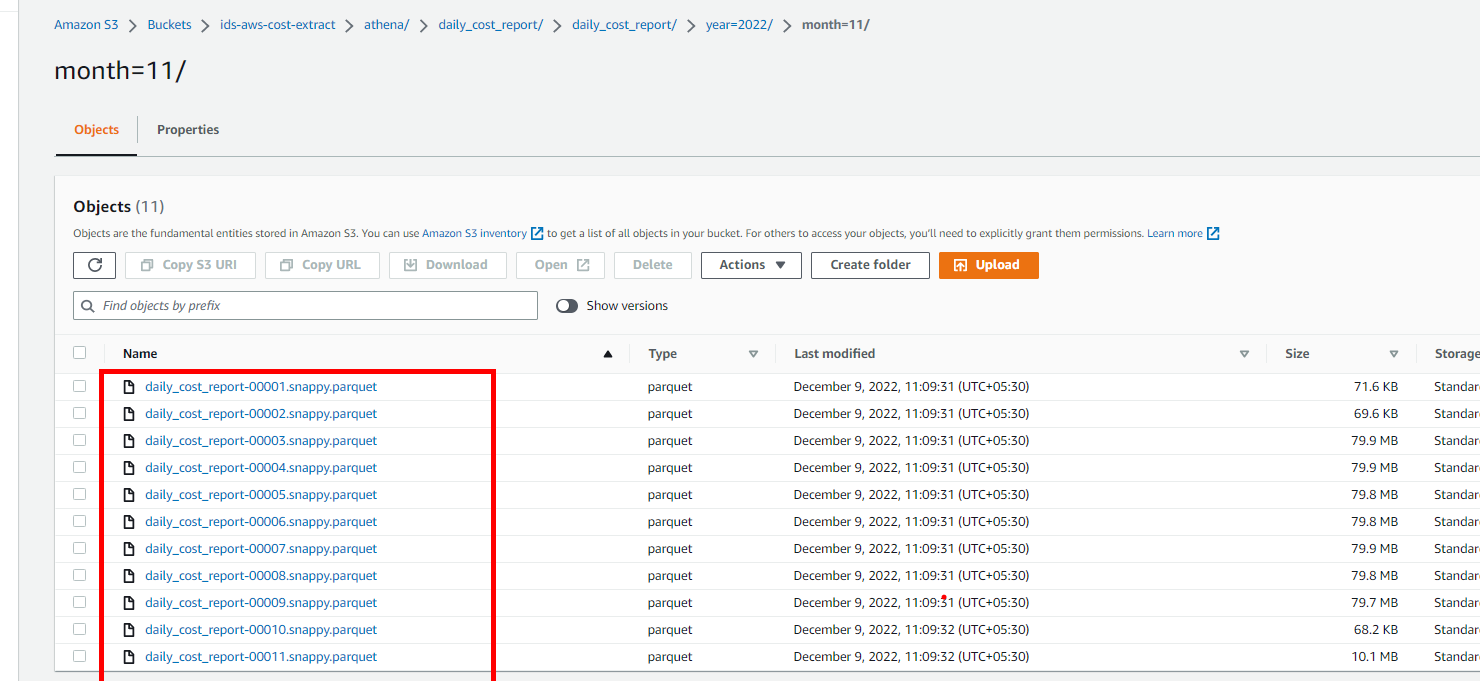
Now i want to pull these parquet files from each folder dynamically using the same source dataset and want to save these parquet file in a datalake in different folders like these -
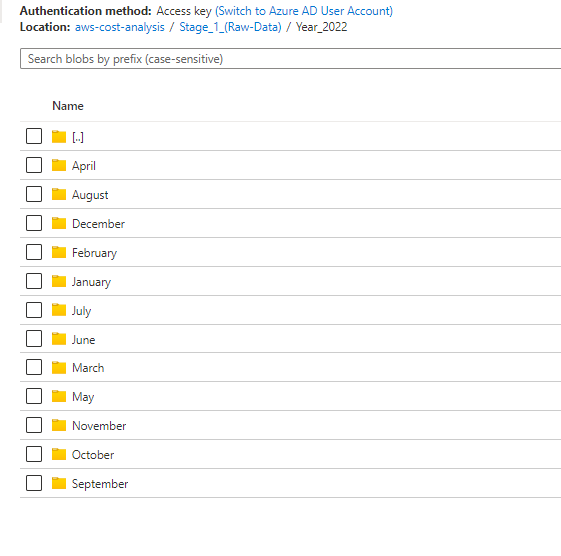
How can i do this using a single source dataset and single sink dataset ?
Now from 1st date of month to the end date of month there would be folder for the current month only but from the 1st date of next month there will be another folder for the next month with some files in it . Sp, from 1st to end of the month i need to pull the files from the current month folder but from 1st to 8th of next month i have to pull the files from the current month folder as well as for the previous month folder as well. After 8th of the next month only the files from the current month folder will be pulled because the previous month folder will not get update for any file after 8th of the current month. This is another big concern to achieve this
Lets's take an example to understand the above situation -
Suppose year is 2023 and month is Jan then from 1st Jan to 31st jan only Jan folder will be in S3 bucket having parquet files so from 1st jan to 31st jan pipeline has to pull those parquet files daily.
Now from 1st Feb there will be another folder of Feb along with the previous folder Jan and now both the folders will keep on getting new files daily till 8th of Feb . After 8th Feb Jan folder will be locked and it will not get any more files but Feb folder will keep on getting new files till 8th Mar.
So the pipeline has to pull files fro Jan folder daily from 1st jan to 31st Jan but from 1st Feb to 8th feb it has to pull files from both Jan and feb folder . After 8th feb it will pull files from only feb folder till 28th feb but from 1st march it will again start pulling files from feb and march both the folders till 8th march.
I want to achieve above two logic using a single source dataset and sink dataset .
can anyone suggest the workflow to achieve this ?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Amar Agnihotri ,
Thanks for the question and using MS Q&A platform.
Thank you for the detailed example. That really helped alot!
I think I get it. If current day of the month is > 8, then only pull current month's folder. Otherwise, pull past month's folder AND current month's folder.
Since the source folders all differ in only the month number, this can be done in a single parameterized source dataset. It needs 2 copy activities though.
Changing the folder names from month numbers to month words is a little tricker, but having the 2 separate copy activities makes this MUCH easier.
Actually, I had another thought, we can use only 1 copy activity if we put it in a loop. Anyway, the logical bit to determine the month number(s).
To determine how many months
@if( less( 8 , dayOfMonth(utcnow())), 'onlyThisMonth' , 'thisAndPastMonth')
To get current month number
formatDateTime(utcnow(),'%M')
To get past month number
formatDateTime(GetPastTime(1,'month'),'%M')
To get current month name
formatDateTime(utcnow(),'MMMM')
To get the past month name
formatDateTime(GetPastTime(1,'month'),'MMMM')
Now with those alone, you could set up an if conditional activity, and separate copy activities as appropriate.
I mentioned another way, getting fancy. This would involve creating an array variable, and filling it with objects packaging the month number and month name together in a json object. Then in a forEach loop you could just do @item().number and @item().name and fill in the folder names in the copy activity, concatenating in the dataset.
So for this lets try like:
{"number":"1", "name":"January"}
{"number":"12", "name":"December"}
The expression to make this, coupled with the logic for deciding how many months will get big and messy. The record maker is like
@array(json(concat('{"name":"','November','","number":','11','}')))
The code:
@if( less( 8 , dayOfMonth(utcnow())),
array(json(concat('{"number":"',formatDateTime(utcnow(),'%M'),'","name":"',formatDateTime(utcnow(),'MMMM'),'"}'))),
union(
array(json(concat('{"number":"',formatDateTime(utcnow(),'%M'),'","name":"',formatDateTime(utcnow(),'MMMM'),'"}'))),
array(json(concat('{"number":"',formatDateTime(GetPastTime(1,'month'),'%M'),'","name":"',formatDateTime(GetPastTime(1,'month'),'MMMM'),'"}')))
)
)
Please do let me if you have any queries.
Thanks
Martin
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
hi @MartinJaffer-MSFT ,
Thanks for the reply and the solution. I am accepting this as a solution because right now i am struggling in the previous steps to get the files from the nested folders and save them with customised file name. I am going to ask another question for that and i will tag you in that question. after that i will jump back to implement this logic.
Thanks a lot