Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,196 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hi Team,
Currently we have setup Pipeline (Attached below) Including copy activity and 2 of data flows for a capture Incremental data from remote source database and loaded(Append to incremental ) data to Azure SQL Server DB, According to our required task working properly, However we have a problem as a for a Dataflows take a much more times such as a 1st dataflow - 10 min and 2nd dataflow 10 min but copy activity tale a below 8 seconds time, Could you pelase check this and advise on this to reduce dataflow run time?
Ex -
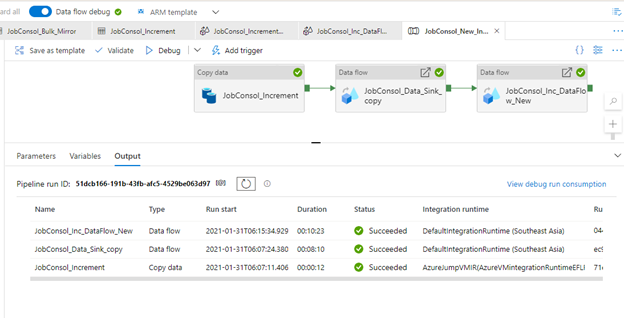
1.copy Activity
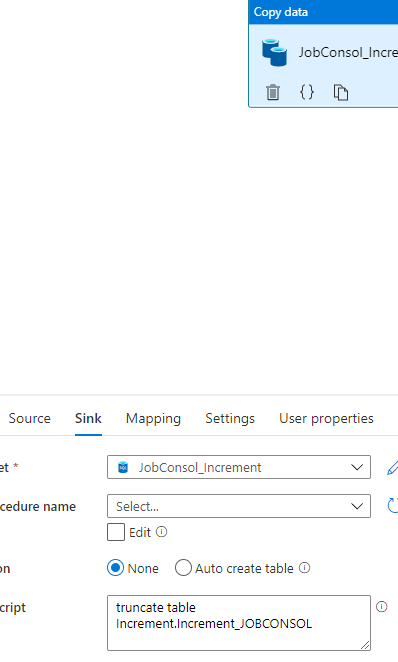
2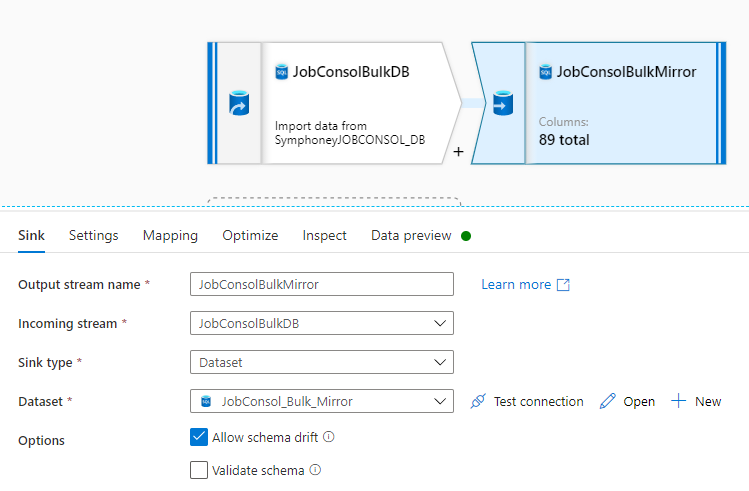 . Dataflow 1-
. Dataflow 1-
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hi @Mahesh Madhusanka ,
We have not received a response from you. Please suggest if below suggested approach is helpful. Otherwise, let us know and we will continue to engage with you on the query.
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members.
Hi @Mahesh Madhusanka ,
We still have not heard back from you. Following up to check if below suggested approach is helpful. Otherwise, let us know and we will continue to engage with you on the query.
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members.

Hi @Mahesh Madhusanka ,
Thank you for asking this question.
Hope this helps! Thanks! :)