Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESA%3C/text%3E%3C/svg%3E)
Hi All,
I have seen a architecture which suggests Synapse Analytics for data ingestion and afterwards data is stored in ADLS Gen2 and again data pushed in to Synapse as well as Azure SQL database . Synapse used again third time and finally data being pushed in to reporting solution.
My questions are why and what purpose Synapse being used here given the fact it is expensive service , why not data being directly ingested in to ADLS?
and I am failing to truly understand the underlying purpose of second and third time usage of Synapse. To be honest, the design has left me quite confused and perplexed. Appreciate if someone could please provide detail answers so that I can get the clarity.

Hello @Samy Abdul ,
Thanks for the question and using MS Q&A platform.
This example workload shows several ways that SMBs can modernize legacy data stores and explore big data tools and capabilities, without overextending current budgets and skillsets. These end-to-end Azure data warehousing solutions integrate easily with Azure and Microsoft services and tools like Azure Machine Learning, Microsoft Power Platform, and Microsoft Dynamics.

Load and Ingest: Azure Synapse Analytics pipelines ingest the legacy data warehouses into Azure.
Store: The data can also enter the centralized Data Lake for further analysis, storage, and reporting.
Process/Manipulate: Serverless analysis tools are available in the Azure Synapse Analytics workspace. These tools use serverless SQL pool or Apache Spark compute capabilities to process the data in Data Lake Storage. Serverless pools are available on demand, and don't require any provisioned resources.
Collaborate/Consume: Power BI can query a semantic model stored in Analysis Services, or it can query Azure Synapse directly.
Consume/Serve: Business analysts use Power BI reports and dashboards to analyze data and derive business insights.
Why Synapse Analytics used three time in the architecture?
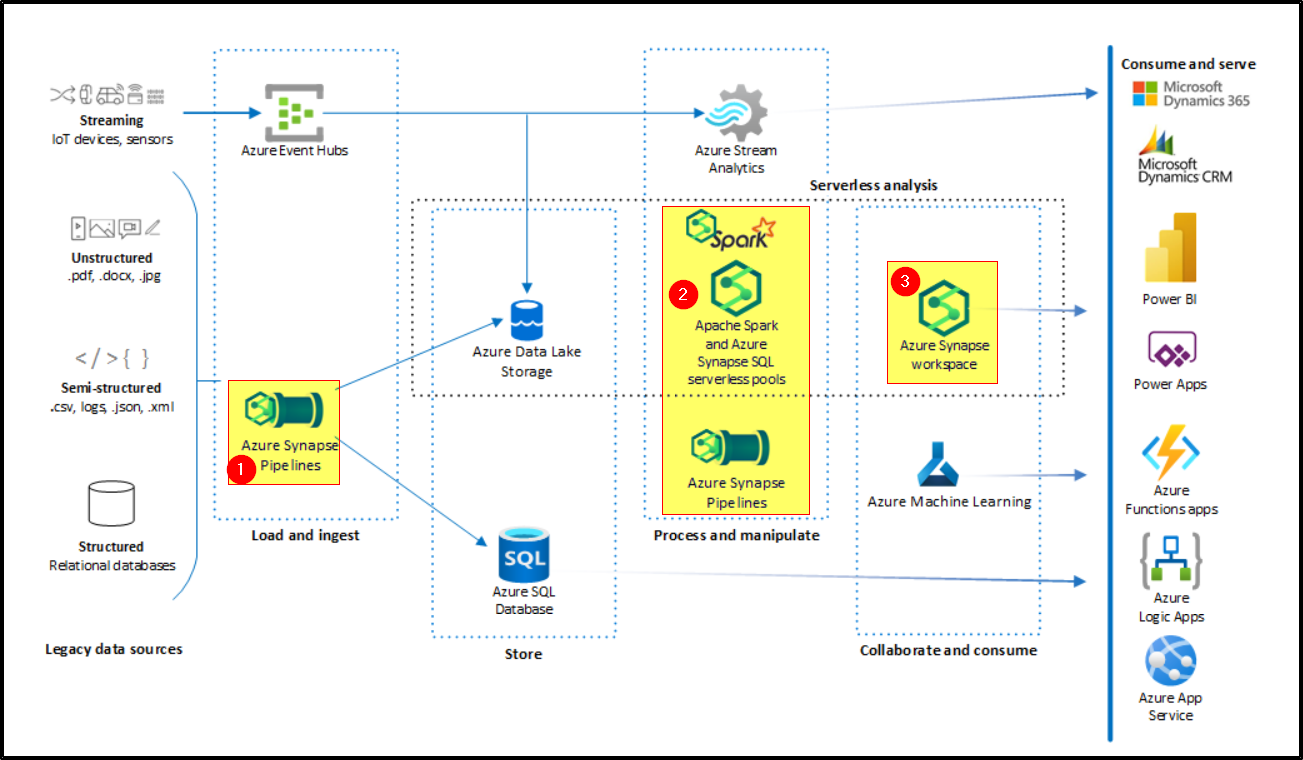
First time: Used for Load and ingest data.
Azure Synapse contains the same Data Integration engine and experiences as Azure Data Factory, allowing you to create rich at-scale ETL pipelines without leaving Azure Synapse Analytics.
Example: Copying data from on-premise to Azure Data Lake gen2. The date contains two csv files one csv contains employee details and other contains department details.
Second Time: Used for processing and manipulate the data.
You can use Synapse SQL or Apache Spark.
Example: By using the mapping data flow joined the both the csv files based on the primary key and then saved into the Azure Data Lake Gen2.
Third Time: Link your Azure Synapse workspace to your new Power BI workspace and creating dataset and building report.
Created a Power BI workspace, link your Azure Synapse workspace, and then create a Power BI data set that utilizes data in your Azure Synapse workspace.
Example: I had created a power BI dataset utilizing the manipulated data which stored in the ADLS gen2 and then created a Power BI reports and dashboards to analyze data and derive business insights.
The solution described in this article combines a range of Azure services that will ingest, store, process, enrich, and serve data and insights from different sources (structured, semi-structured, unstructured, and streaming).
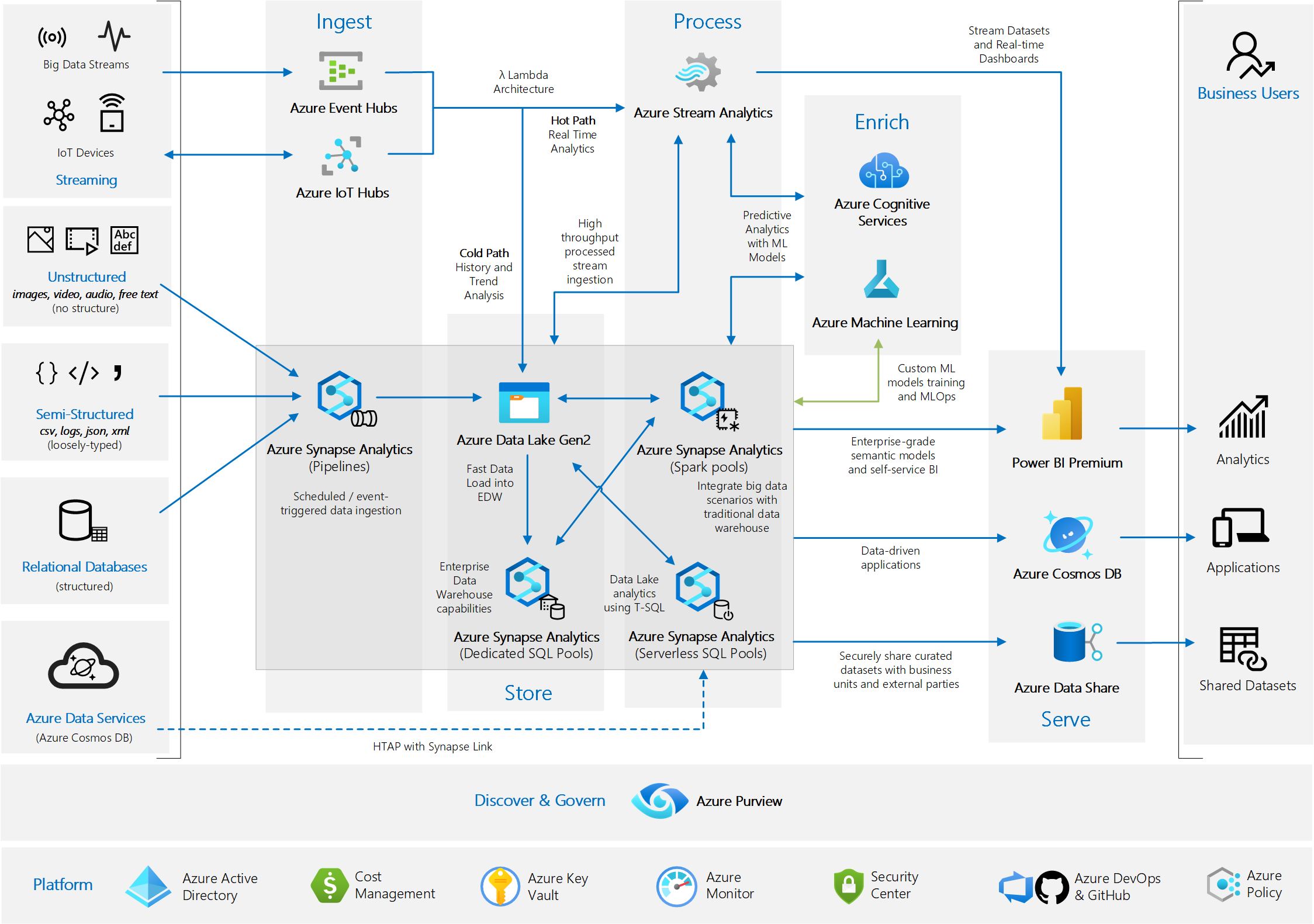
For more details, refer to Analytics end-to-end with Azure Synapse.
Hope this helps. Do let us know if you any further queries.
---------------------------------------------------------------------------
Please "Accept the answer" if the information helped you. This will help us and others in the community as well.
Thanks a lot for the detailed answer. Synapse is bit costly service to use, wouldn't it affect the costing if Synapse is used for all 3 purposes as you have mentioned. Appreciate if you could please clarify on that part. Thanks
Hello @Samy Abdul ,
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale.
Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, manage and serve data for immediate BI and machine learning needs.
[Load and Ingest]- Azure Synapse contains the same Data Integration engine and experiences as ADF, allowing you to create rich at-scale ETL pipelines without leaving Azure Synapse Analytics. [Pricing is same as ADF].
[Process & manipulate] -
Hope this helps.