Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,514 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJV%3C/text%3E%3C/svg%3E)
In reference to this question, is it preferred to pass these records to a DataFactory pipeline, and a dataflow activity that ends in a SQL Table sink?
If so, how can I pass the DataFrame from the Databricks activity step to a Dataflow?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERA%3C/text%3E%3C/svg%3E)
Not entirely sure of the question but DataBricks should be able to load to a table so why the need to pass it to DataFactory?
To pass to DF, I'd say put them to a file and pass a reference to the file back to DataFactory - if it were a small dataframe, then stringifying has potential (although not sure how easily DF can reconstruct)
I would love to hear how to load a 5000-row pd.DataFrame object to Azure SQL Server using the jdbc modules in spark: https://learn.microsoft.com/en-us/answers/questions/488391/how-can-i-insert-a-pandas-dataframe-into-azure-sql.html
Convert to a Spark dataframe and then...
this is all in scala? is there a method that exists for the Databricks default, python/pyspark?
Should work in pyspark too. I note it's an older version that I provided in the link... an updated version with some python logic in link below
I also feel like since you can arrange Databricks and Python activities in ADF upstream from a dataflow that it should be a standard use case to operate on the output of those activities in the subsequent pipeline activities. Is that not the case?
Yes, you should be able to pass detail back to Data Factory, can't remember the syntax but should be able to find it on Google

Hi @Jeff vG ,
Thanks for the question and using MS Q&A platform.
If you want to write a pandas dataframe to Azure SQL Server using spark you should convert the pandas dataframe in a spark dataframe (using the spark.createDataframe method) and then there should not be any particular problem in writing it into a Azure SQL Server table.
The following document (SQL databases using JDBC - Azure Databricks - Workspace | Microsoft Learn). It shows how you can read/write to/from SQL databases using JDBC. It, however, uses Spark dataframes. I would argue that doing the same with pandas dataframes is not a core use case of Databricks. If you run pandas, your code will only run on driver. If you really wish to use pandas, you can use sqlalchemy to create connection and then leverage .to_sql() on your pandas dataframe.
Before criticizing pandas, it is important to understand that pandas may not always be the right tool for every task. Pandas lack multiprocessing support, and other libraries are better at handling big data.
For more details, refer to Loading large datasets in Pandas
Hope this helps. Do let us know if you any further queries.
---------------------------------------------------------------------------
Please "Accept the answer" if the information helped you. This will help us and others in the community as well.
Hi @Jeff vG ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Hi,
I am able to use spark.read to read data from this same table, but when I try to INSERT into it, I get syntax errors referencing characters I do not have in my queries. Please advise?
This works to read:
pushdown_query = "(select Id from dbo.MasterList) master"
df = spark.read.jdbc(url=jdbcUrl, table=pushdown_query, properties=connectionProperties)
display(df)
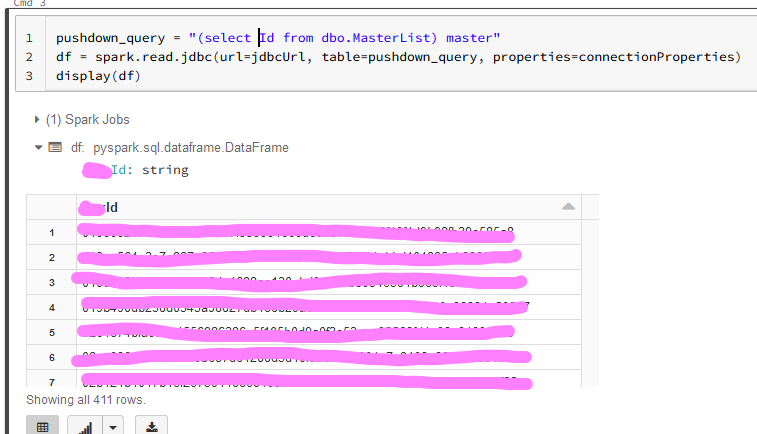
But this produces com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near the keyword 'insert'.
pushdown_insert = "insert into [dbo].[MasterList] ([Id], [ImportFileName], [ImportFileDate]) values ('999B8D61FA2A6959D254B6FF5D0FB512249329097336A35568089933B49ABDDE', 'filename.csv', '2021-07-29')"
d = {'Id': '999B8D61FA2A6959D254B6FF5D0FB512249329097336A35568089933B49ABDDE', 'ImportFileName':'filename.csv', 'ImportFileDate':'2021-07-29'}
df = pd.DataFrame(d, index=[0])
df
sdf = spark.createDataFrame(df)
sdf.write.jdbc(url=jdbcUrl, table=pushdown_insert, properties=connectionProperties)
I have tried many different ways of quoting/bracketing and none of them seem to work. This seems to be an issue with some CTE translation for the Spark SQL Connector?
Alternatively, if I try this route, I get a different error:
sdf.write\
.format("jdbc")\
.mode("append")\
.option("url", jdbcUrl)\
.option("dbtable", "MasterList")\
.option("user", user)\
.option("password", password)\
.save()
---> : com.microsoft.sqlserver.jdbc.SQLServerException: CREATE TABLE permission denied in database 'master'.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYL%3C/text%3E%3C/svg%3E)
Dear Sir/Madam,
I think your hints are very helpful, but I still have some questions in my case. I would appreciate it if you can help me:
I stored 20yrs data in Azure SQL(totally it is 4 tables with different columns). It is much fast to use 'spark.read.jdbc' to read them and join them into a large one(it is necessary to make them become one big table before further processing).
However, it is easy to load the whole with spark, but once I want to proceed with the data month by month, in which divide the data into small partitions manually, pandas should have a better performance.
So is there any method that I can load the specific data from the register SQL table in databricks via pandas? (the result could be pandas data frame directly
So that I can save much time for reading via spark and then transferring spark table to pandas table. I found that transferring spark tables to pandas tables could take a long long time.
Thanks