Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,696 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAF%3C/text%3E%3C/svg%3E)
I'm trying to query dedicated pool tables using the Synapse Spark notebooks. I'm referring to the document here:
It seems to me that I can only pass the table name into the method, for example, if I need to join 2 tables, I need to read both tables into 2 data frame and join them using Spark.
val df_1 = spark.read.synapsesql("<DBName>.<Schema>.<TableName_1>")
val df_2 = spark.read.synapsesql("<DBName>.<Schema>.<TableName_2>")
then do the join in Spark.
I'm wondering if it's possible to pass the SQL join statement into the spark.read.synapsesql? Like this
val df = spark.read.synapsesql("SQL that join TableName_1 and TableName_2")
I have tried to put a simple SQL selection like 'select * from <DBName>.<Schema>.<TableName_1>' and it complains for 'SyntaxError: invalid syntax'.
Any advice is greatly appreciated!

Hello @alex feng ,
Thanks for the question and using MS Q&A platform.
You cannot pass SQL join statement into the
spark.read.synapsesql.
You can try the below to join two data frames as shown below.
For the demo purpose, I had created two tables in the Azure Synapse Dedicated pool named chepra and the tables employee which contains (EMP_ID and EMP_NAME) and employeedetails which contains (EMP_ID, EMP_EMAIL and EMP_CONTACT) as shown below.
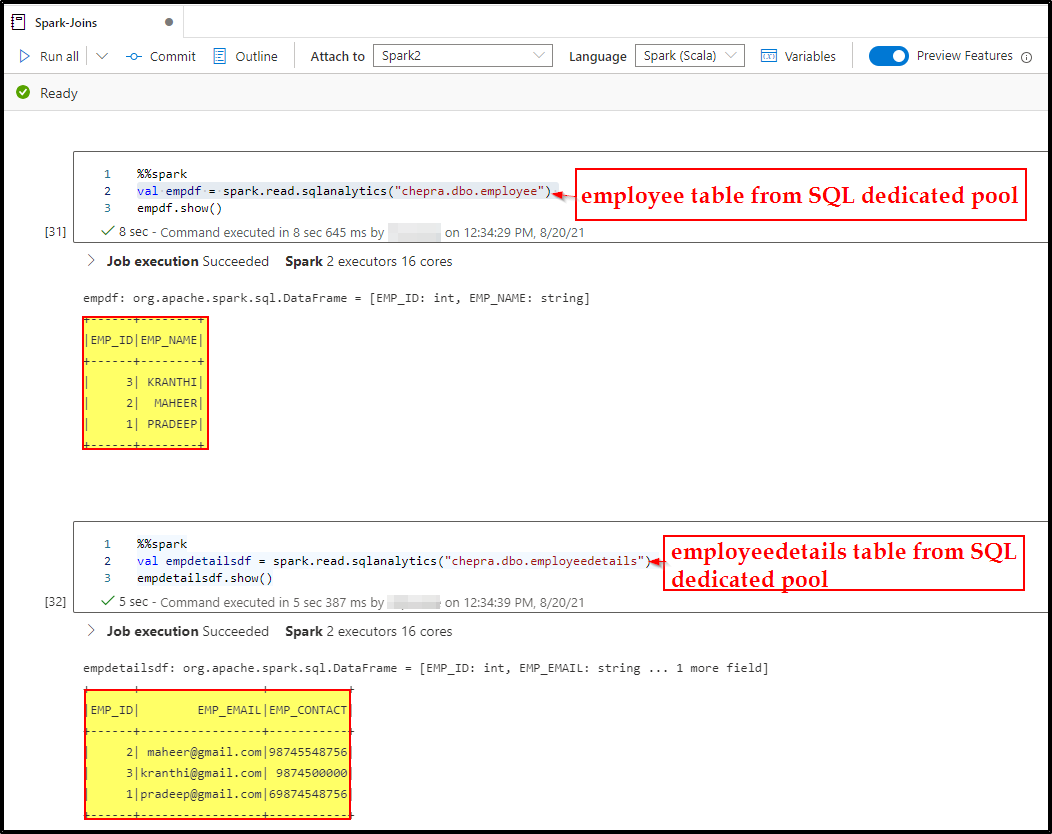
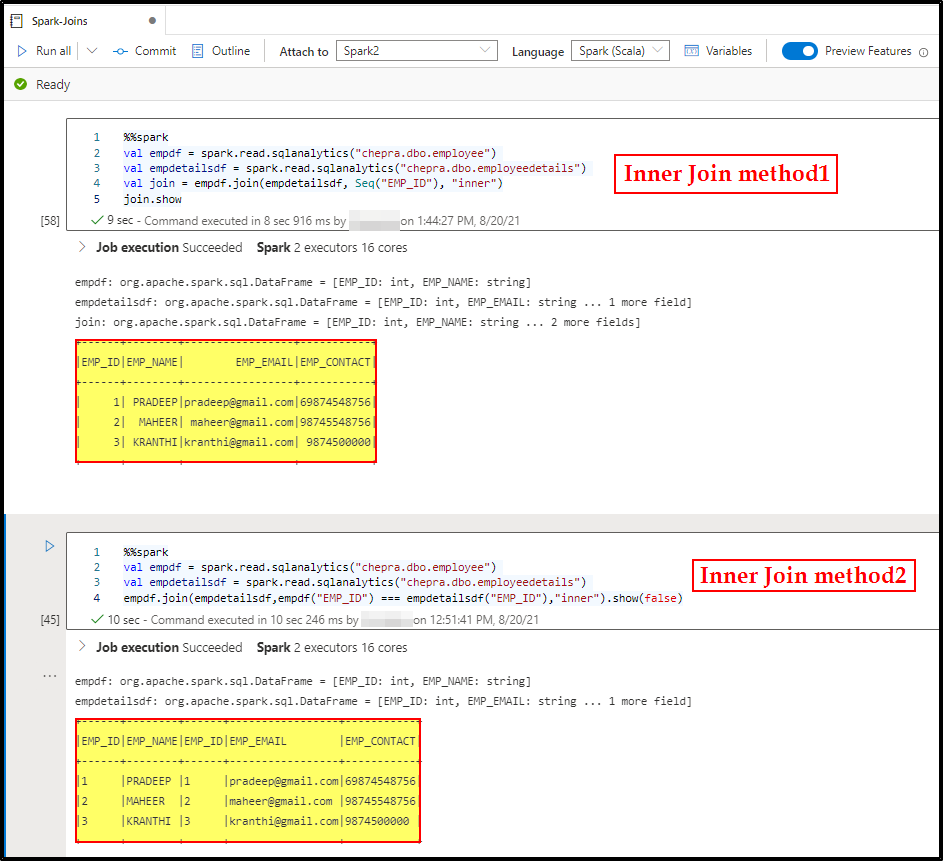
You can use any one of the below methods to join two data frames:
Method1:
%%spark
val empdf = spark.read.sqlanalytics("chepra.dbo.employee")
val empdetailsdf = spark.read.sqlanalytics("chepra.dbo.employeedetails")
val join = empdf.join(empdetailsdf, Seq("EMP_ID"), "inner")
join.show
Method2:
%%spark
val empdf = spark.read.sqlanalytics("chepra.dbo.employee")
val empdetailsdf = spark.read.sqlanalytics("chepra.dbo.employeedetails")
empdf.join(empdetailsdf,empdf("EMP_ID") === empdetailsdf("EMP_ID"),"inner").show(false)
For more details, refer to the below links:
Spark SQL Join Types with examples
Hope this helps. Do let us know if you any further queries.
---------------------------------------------------------------------------
Please "Accept the answer" if the information helped you. This will help us and others in the community as well.