Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,484 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EM%3C/text%3E%3C/svg%3E)
from azureml.opendatasets import NycTlcGreen
data = NycTlcGreen()
df = data.to_spark_dataframe()
display(df.limit(10))
run for over 40 min without ever ending : Conf : (8 vcpu /64 GO 3nodes).
Any help would be appreciated. Nothing in the Queue, no previous job, spark pool basic config.
Many thanks for any hint.

Hello @Morpheuss ,
Welcome to the Microsoft Q&A platform.
We haven't experienced the above behaviour using Synapse Apache Spark pools till date.
This issue looks strange. For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
As per the test from my end on Synapse Apache Spark Pool: Medium (8 vCores/64 GB).
On a new cluster it took nearly 3mins 20 secs.
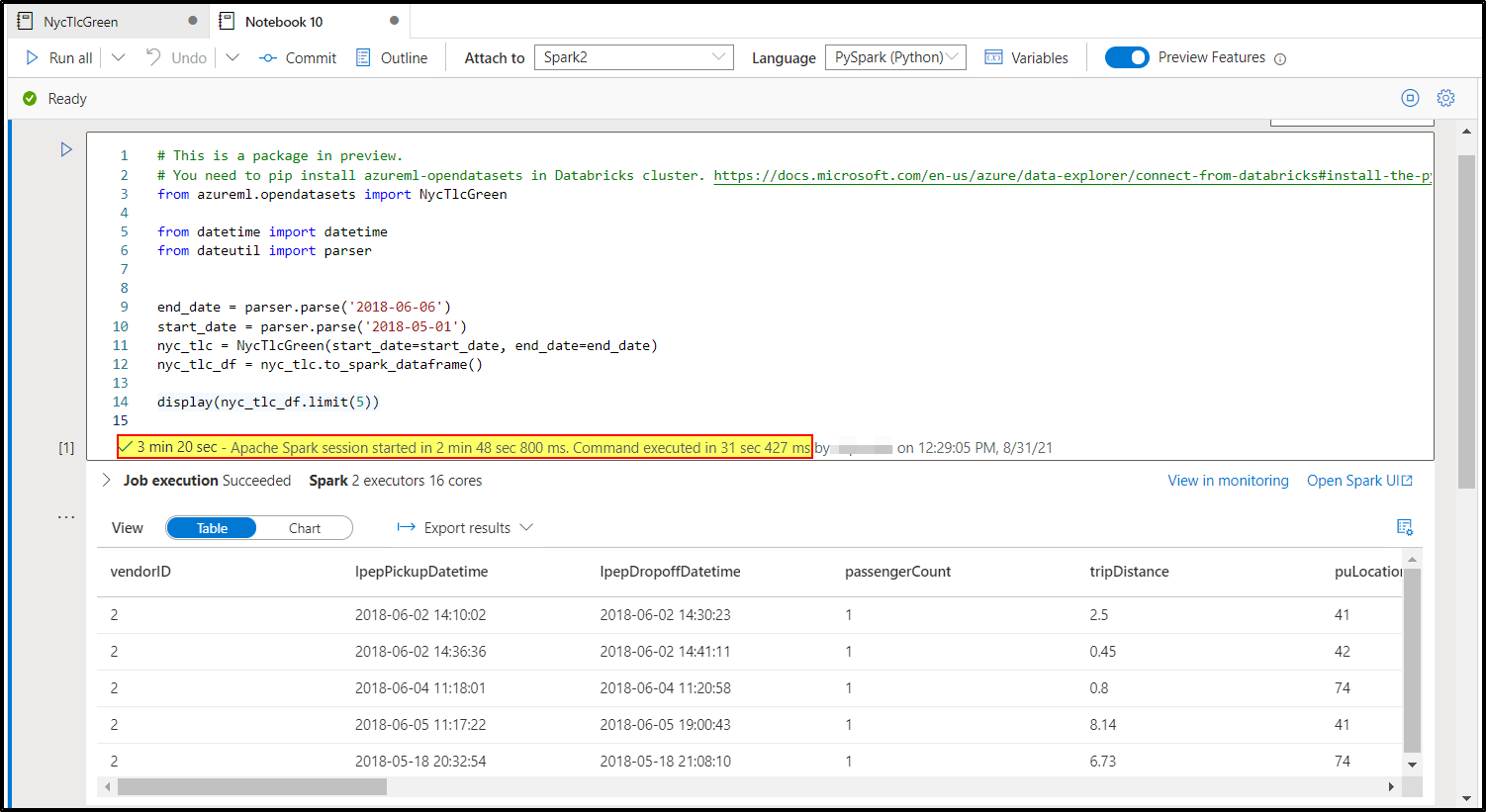
On a running cluster which took just 15 secs.
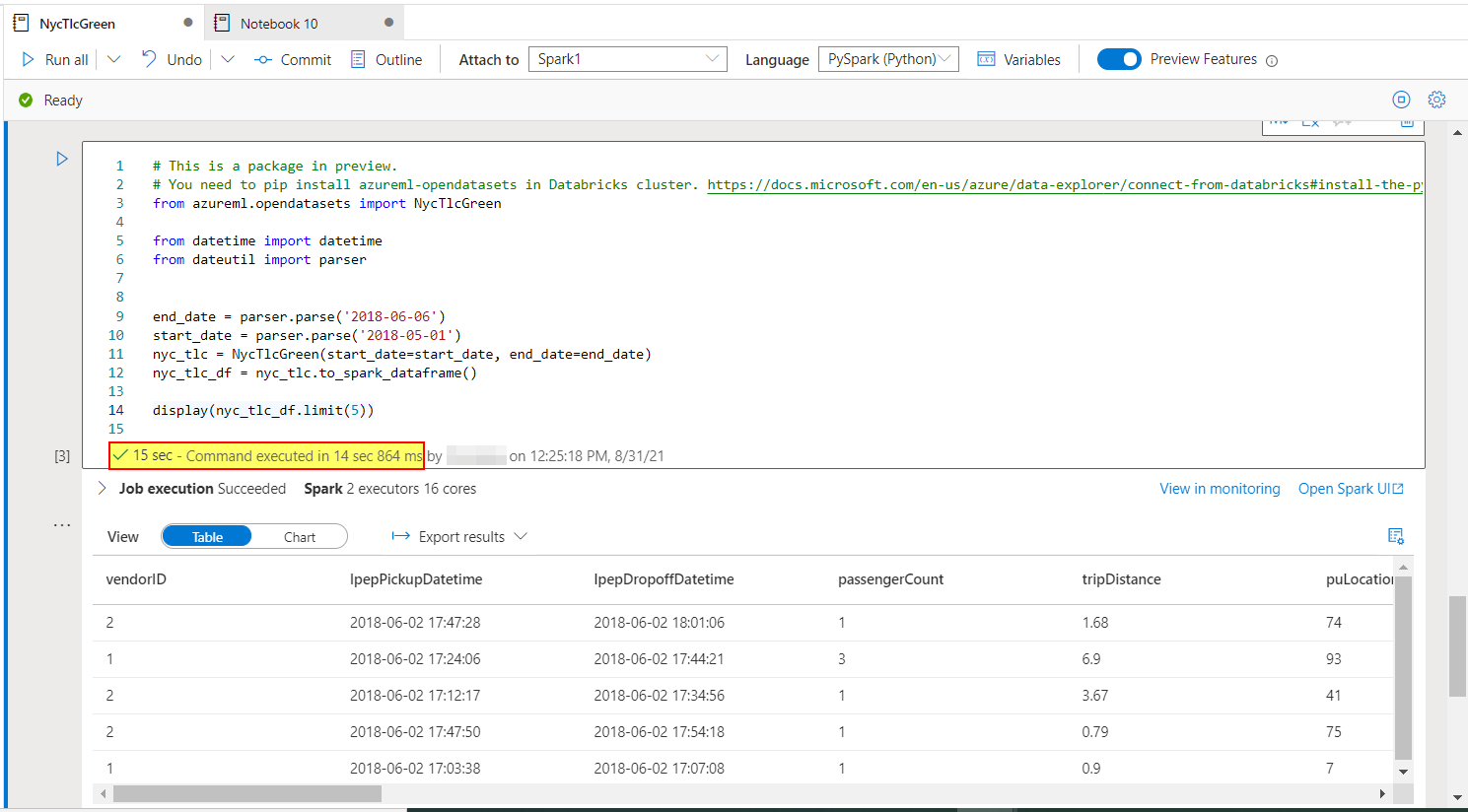
Hope this helps. Do let us know if you any further queries.
---------------------------------------------------------------------------
Please "Accept the answer" if the information helped you. This will help us and others in the community as well.
Hello @Morpheuss ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Hello @Morpheuss ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.