Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAT%3C/text%3E%3C/svg%3E)
Hello Team,
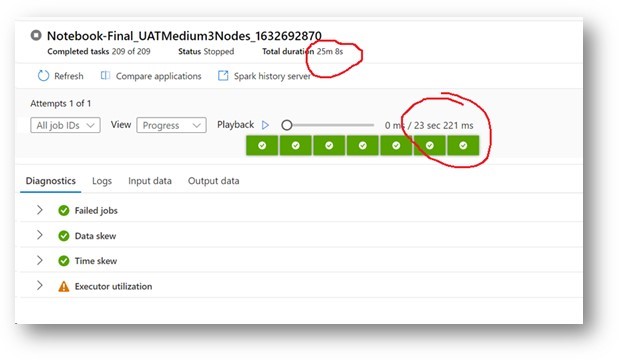
We have a Synapse pipeline which has Notebook as an activity.
Tried pipeline with multiple SKUs and here is our observation, however unable to understand which is the best SKU to select for Production?
Pool Size Time Taken
Large (3-200 Nodes) – Auto Scale enabled =>17 mins~
Large (3 Nodes) – Auto Scale disabled =>30 mins~
Medium (3 Nodes) – Auto Scale disabled =>45 mins~
Questions/Suggestions:
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @Anonymous ,
Thanks for the ask and using Microsoft Q&A platform .
I will start with what is the workload which we are trying to process and is the data which spark is consuming is paritioned or not . For example if you are processing 100GB of csv file on a small cluster ( without partition) adding executor will not help . I wil also go ahead and put the autoscale ON in production . Also I think you will also have to look into the internal details as to how the data is processed . Have you gone through this link .
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/apache-spark-history-server
Please do let me know how it goes .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how