Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,617 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYC%3C/text%3E%3C/svg%3E)
I am getting the data from google big query using self hosted IR and save it into azure MySQL database using Azure Manged IR with VNET integration. Currently the transfer rate is slow. It took about an hour to transfer 1G of data.
I have read the official website about tuning the performance by adjusting the DIU and parallel copies. I have try to increase these parameters and the throughput does not really change much.
I have checked on azure MySQL database, the memory consumption is about 50% for 2vcore. I did try to increase to 4vcore and the memory consumption is reduced to about 25%. So I presume that it should not be the bottleneck for the process.
How should I identify the bottleneck of the process and improve the throughput? 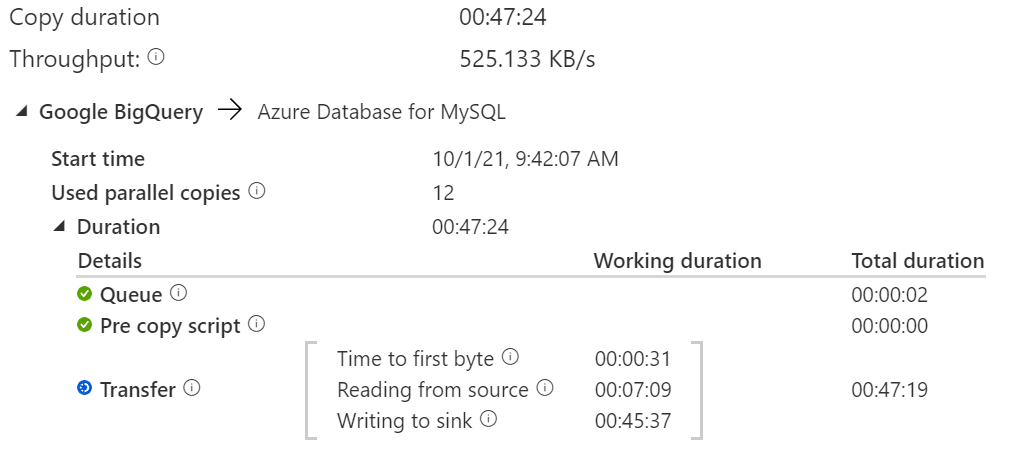
Any advice would be greatly appreciated!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESA%3C/text%3E%3C/svg%3E)
Have you gone through below performance tuning doc? Please have a look.
Yea, I saw the document and have tried some tuning suggested. But overall the performance is not improved drastically. Logically, how long will it take for a transfer of 1GB data from GB to azure MySQL?
This heavily depends on network bandwidth and generally higher the Bandwidth the more quickly data gets
copied. Few pointers for your reference if that helps:
Azure provides a set of enterprise-grade data storage and data warehouse solutions, and Copy Activity
offers a highly optimized data loading experience that is easy to configure and set up. With just a single
copy activity, you can achieve:
Loading data into Azure Synapse Analytics at 1.2 GBps. For a walkthrough with a use case, see Load 1 TB into
Azure Synapse Analytics under 15 minutes with Azure Data Factory.
Loading data into Azure Blob storage at 1.0 GBps
Loading data into Azure Data Lake Store at 1.0 GBps Thanks
Thanks for the pointer.
It seems like transferring 1GB of data should not taking 1hour long.
Is there any tips you can share with me on how to identify which part is the bottleneck?

Hi @Yang Chowmun ,
Thank you for posting query on Microsoft Q&A Platform.
Data movement throughput can be depends on many factors. Such as,
Below are few recommendations which you can try to increase data movement throughput.
In case of Self-hosted IR, recommendation is to use a dedicated machine to host IR. The machine should be separate from the server hosting the data store. Start with default values for parallel copy setting and using a single node for the self-hosted IR.
Please check below documentation, where many recommendation's listed for copy activity performance increase.
https://learn.microsoft.com/en-us/azure/data-factory/copy-activity-performance
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
I have found the root cause. The bottleneck is the IOPS for MySQL. For azure database for MySQL, the IOPS is proportional to the storage. I have started with 5Gb which result in only max of 100IOPS and the transfer speed is pretty slow for 100IOPS.
Hi @Yang Chowmun ,
Awesome. Happy to know that you found cause. Thank you for sharing.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPS%3C/text%3E%3C/svg%3E)
azure data factory