Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,936 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKP%3C/text%3E%3C/svg%3E)
Is there any way to validate the parquet file data (row by row) from blob storage with source table?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @kuljeet panag ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @kuljeet panag ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @kuljeet panag ,
Thanks for the ask and using Microsoft Q&A platform .
I think one way to go is to use the Mapping data flow . In mapping data flow you can create two sources and then use a JOIN transformation with NOT EXIST option .
if you review the thread : https://learn.microsoft.com/en-us/answers/questions/578219/data-flow-34delete-if34-setting-in-alter-row.html?childToView=580571#answer-580571 , it does use the join and it should give you some idea .
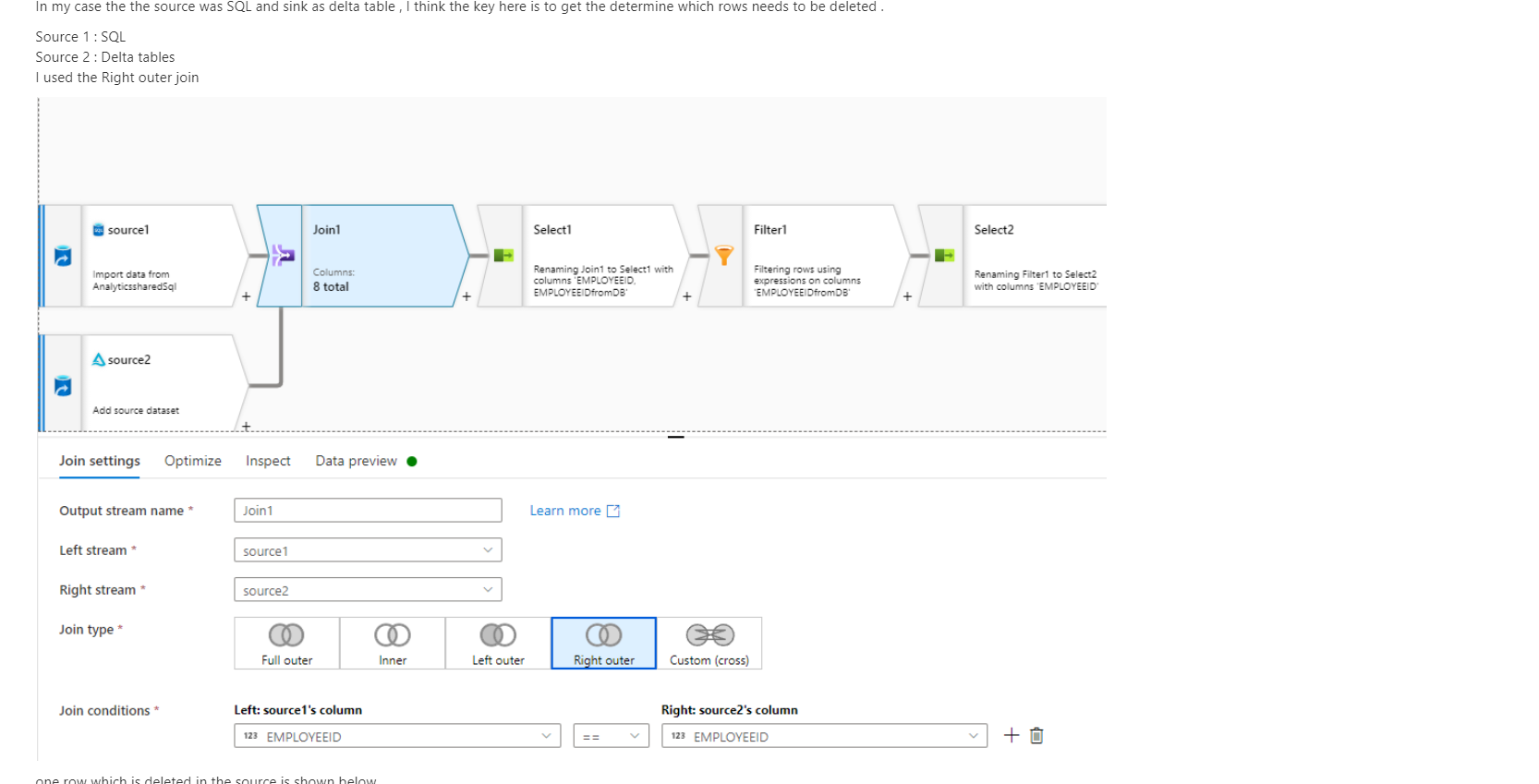
Please do let me know how it goes .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how