Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,399 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKW%3C/text%3E%3C/svg%3E)
Hello. We are using Azure Japanese speech to text.
We want to evaluate its performance.
What parameters affect the result, noises or microphones or intonations or etc....?

@Kohei Watanabe Azure speech to text provides two options with respect to the models that are used behind the service.
With the baseline model you can use the API directly without any customization where the model is trained by Microsoft against fairly decent background conditions. If your scenario involves recognition of speech in a day to day scenario or recordings this model should work for you right away with the API.
The custom model can be used in a scenario where the baseline model accuracy is not to your standards. For example, you have custom words in your speech like acronyms, phrases used in an organization, speech from factory floor with lot of background noises etc. This custom model is trained with your audio files on top of the baseline model so all the capabilities of baseline model are built in your resultant endpoint.
To summarize, the result from the service depends on your scenario and all the factors do effect them but if your scenario isn't for a custom background then you can use the baseline model rightaway and evaluate the performance. Please check the FAQ document that could help you with more details.
Thank you for your response!
I would like to use the custom model trained by both text and audio( or pronouciation),
but now just text is supported in Japanese.
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
Do you have a plan to support the Japanese custom model to train by both text and audio?
I would like to know the roadmap of Azure Speech-to-Text.
@Kohei Watanabe You should be able to use Japanese for custom voice(TTS) and custom speech(STT) from the speech studio.
I am not sure if there is a limitation mentioned about this on the language support page.
You can view the announcements of Azure speech from the Azure updates page here.
Thank you! I confirmed that the model can be trained by both text and audio in Japanese!
So this document seems to be wrong...
https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
Thanks @Kohei Watanabe . The PR will be reviewed by the content author before being approved. Thanks for the feedback.
If my answer helped. Please feel free to accept the same as answer.
If an answer is helpful, please click on  or upvote
or upvote  which might help other community members reading this thread.
which might help other community members reading this thread.
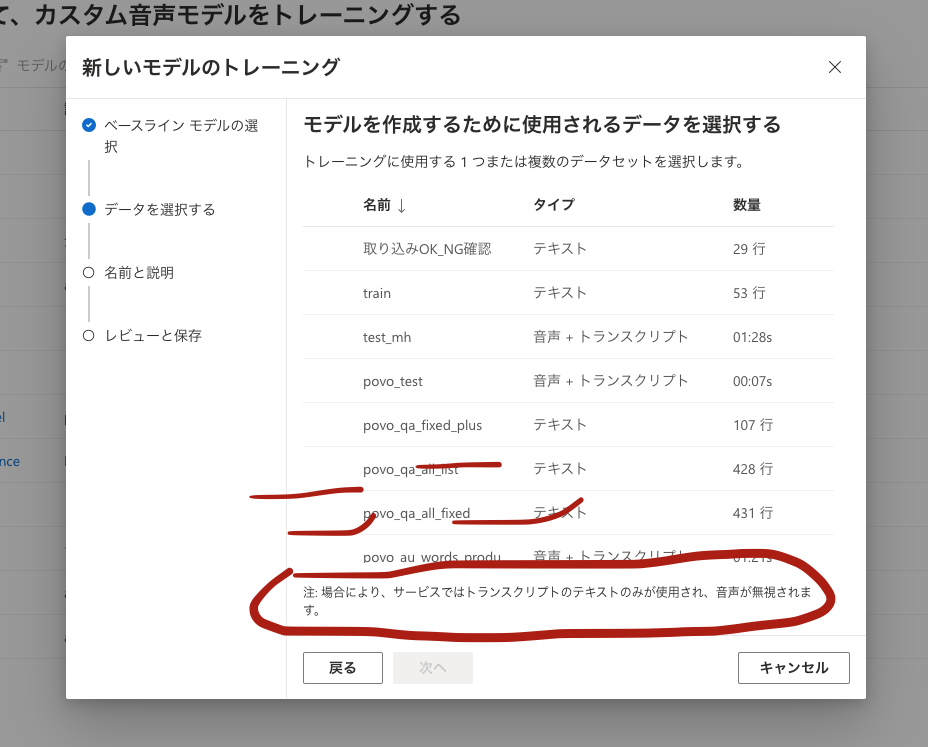
mmm, the model could be trained by both audio and text but just text seems to be used...
This UI is really confusing....