Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,935 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EN%3C/text%3E%3C/svg%3E)
Getting below error when running spark data frame code in Azure Synapse Analytics.
df = spark.read.parquet('https://nagasristorageacc.blob.core.windows.net/misc-container/dbo_Reservation.parquet')
df.show(10)
Py4JJavaError: An error occurred while calling o228.parquet.
: java.lang.UnsupportedOperationException
at org.apache.hadoop.fs.http.AbstractHttpFileSystem.listStatus(AbstractHttpFileSystem.java:91)
at org.apache.hadoop.fs.http.HttpsFileSystem.listStatus(HttpsFileSystem.java:23)
at org.apache.spark.util.HadoopFSUtils$.listLeafFiles(HadoopFSUtils.scala:225)
at org.apache.spark.util.HadoopFSUtils$.$anonfun$parallelListLeafFilesInternal$1(HadoopFSUtils.scala:95)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFilesInternal(HadoopFSUtils.scala:85)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFiles(HadoopFSUtils.scala:69)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$.bulkListLeafFiles(InMemoryFileIndex.scala:158)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.listLeafFiles(InMemoryFileIndex.scala:131)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.refresh0(InMemoryFileIndex.scala:94)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.<init>(InMemoryFileIndex.scala:66)
at org.apache.spark.sql.execution.datasources.DataSource.createInMemoryFileIndex(DataSource.scala:581)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:417)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:325)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:308)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:308)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:838)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Traceback (most recent call last):
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py", line 458, in parquet
return self._df(self._jreader.parquet(_to_seq(self._spark._sc, paths)))
File "/home/trusted-service-user/cluster-env/env/lib/python3.8/site-packages/py4j/java_gateway.py", line 1304, in call
return_value = get_return_value(
File "/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 111, in deco
return f(*a, **kw)
File "/home/trusted-service-user/cluster-env/env/lib/python3.8/site-packages/py4j/protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling o228.parquet.
: java.lang.UnsupportedOperationException
at org.apache.hadoop.fs.http.AbstractHttpFileSystem.listStatus(AbstractHttpFileSystem.java:91)
at org.apache.hadoop.fs.http.HttpsFileSystem.listStatus(HttpsFileSystem.java:23)
at org.apache.spark.util.HadoopFSUtils$.listLeafFiles(HadoopFSUtils.scala:225)
at org.apache.spark.util.HadoopFSUtils$.$anonfun$parallelListLeafFilesInternal$1(HadoopFSUtils.scala:95)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFilesInternal(HadoopFSUtils.scala:85)
at org.apache.spark.util.HadoopFSUtils$.parallelListLeafFiles(HadoopFSUtils.scala:69)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex$.bulkListLeafFiles(InMemoryFileIndex.scala:158)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.listLeafFiles(InMemoryFileIndex.scala:131)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.refresh0(InMemoryFileIndex.scala:94)
at org.apache.spark.sql.execution.datasources.InMemoryFileIndex.<init>(InMemoryFileIndex.scala:66)
at org.apache.spark.sql.execution.datasources.DataSource.createInMemoryFileIndex(DataSource.scala:581)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:417)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:325)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:308)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:308)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:838)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)

Hello @Naga ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hello @Naga ,
Thanks for the question and using MS Q&A platform.
This is an excepted behaviour, due to incorrect usage of the Azure Storage URL.
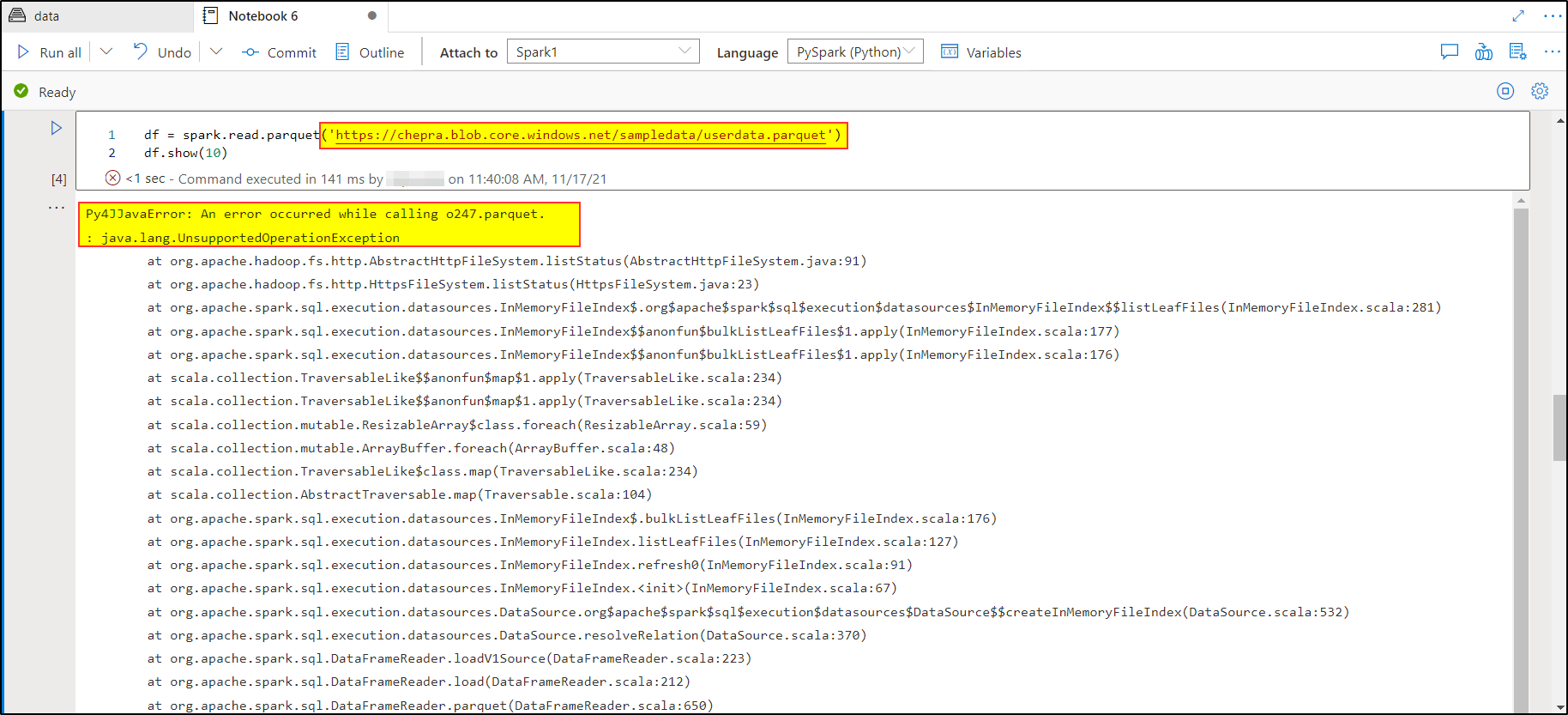
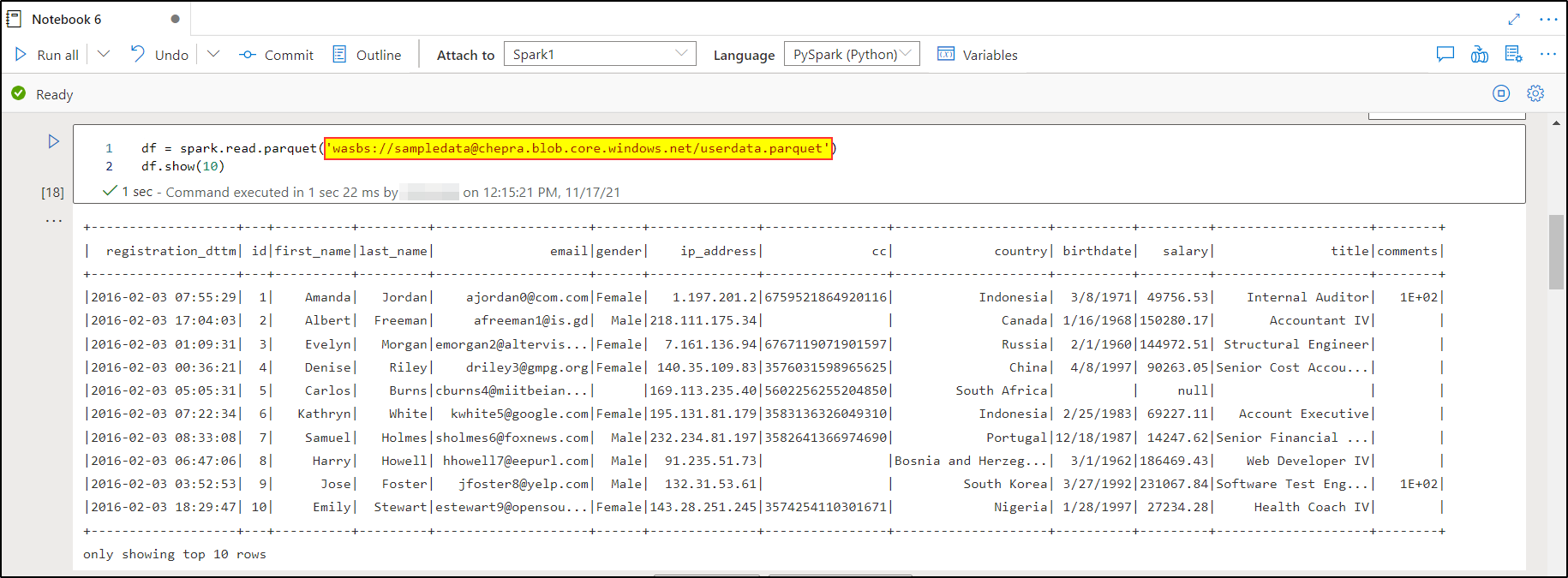
Azure Storage Blob URL:
df = spark.read.parquet('wasbs://<ContainerName>@<StorageName>.blob.core.windows.net/<FileName.parquet>')
df.show(10)
Azure Data Lake Gen2 URL:
df = spark.read.parquet('abfss://<FileSystemName>@<StorageName>.dfs.core.windows.net/sample/<FileName.parquet>')
df.show(10)

Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Naga ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.