' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMH%3C/text%3E%3C/svg%3E)
14,502 questions

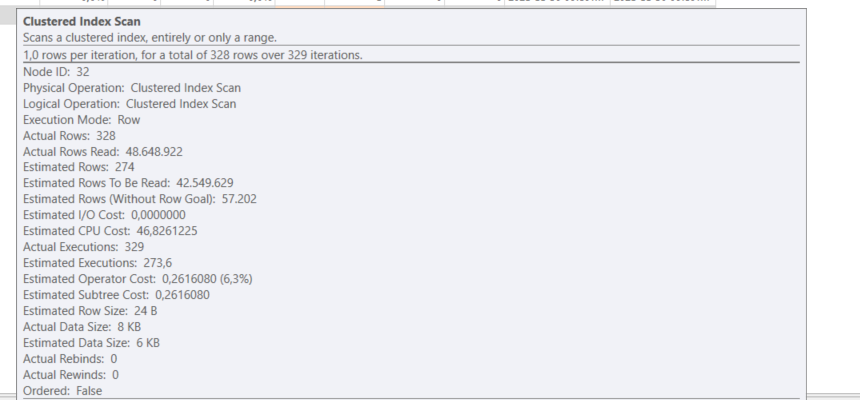
So it was as I suspected. The row goal raised its ugly head again. Don't get me wrong. There are situations where row goals make perfect sense. But the idea here is that the CI scan will quickly find a matching row, and therefore it does not have to run to the end, and therefore be cheaper than the index seek + key lookup. But if there is no matching row, guess what. It runs to the end and becomes very expensive. And why wouldn't run to the end? After, there is a reason you use [NOT] EXISTS.
Paul White has a series of blog posts about row goals, and I seem to recall that he described this use of row goals as an anti-pattern.
It is also interesting to observe that in the plan with the hint, the key lookup is now grossly over estimated in number of rows.

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)