Azure SQL Database
An Azure relational database service.
5,443 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EUM%3C/text%3E%3C/svg%3E)
hi I am looking efficient way to process and load 5 million records towrite to a azure sql server using data bricks.
I want to retain the schema of the table and hence i truncate the table everytime
I am currently using jdbc but it takes lot of time to load and I have to increase the DTU every time which isnt a good practice to do so
i referred to this link but i don't find the required packages in databricks to import
https://stackoverflow.com/questions/55708079/spark-optimise-writing-a-dataframe-to-sql-server/55717234
currenlty I am loading it using the below command
df.write.format("jdbc").option("url", sqlDwUrlSmall).option("forward_spark_azure_storage_credentials","True").option("truncate",true).option("dbTable", schemaName+"."+Tblname).mode("overwrite").save()

Hello @Ullas Mulbagal Sripathi Rao ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
---------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you. ' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @Ullas Mulbagal Sripathi Rao ,
Thanks for using Microsoft Q&A .
I was reviewing the SO link which you have posted and then also looked the code which you shared . I see that the format option is set differently .
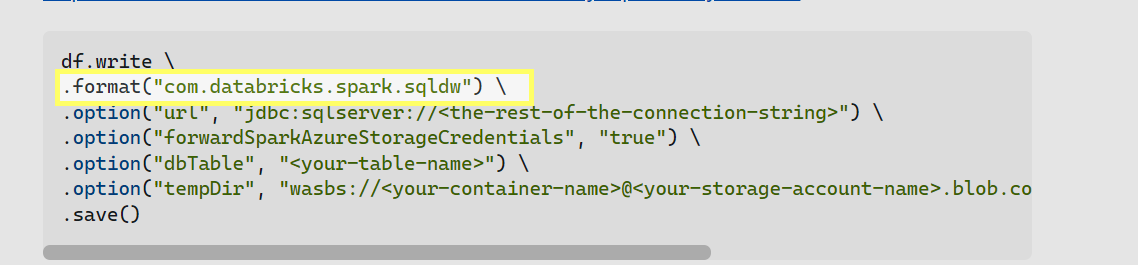
Can you please share

.When i run the below code I do not get any error .
df = spark.read \
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://myDBservername.database.windows.net:1433;database=synapse;user=username;password=password;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;") \
.option("tempDir", "wasbs://container@storageaccount .blob.core.windows.net/input") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", "foo") \
.load()
Thanks
Himanshu
hi
Py4JJavaError: An error occurred while calling o481.load.
: com.databricks.spark.sqldw.SqlDWConnectorException: Exception encountered in Azure Synapse Analytics connector code.
a
Caused by: java.lang.IllegalArgumentException: Unexpected version returned: Microsoft SQL Azure (RTM) - 12.0.2000.8
Sep 18 2021 19:01:34
Copyright (C) 2019 Microsoft Corporation
Make sure your JDBC url includes a "database=<DataWareHouseName>" option and that
it points to a valid Azure Synapse SQL Analytics (Azure SQL Data Warehouse) name.
This connector cannot be used for interacting with any other systems (e.g. Azure
SQL Databases).
Hello @Ullas Mulbagal Sripathi Rao ,
In order to investigate further, could you please share the below details:
sure , I will do it in a while. but does the package com.databricks.spark.sqldw support sql server or only the azure synpase ?
as per the error message this is looking for an azure synapse sever. while I am trying to read a sql server db
attached is the full stack error 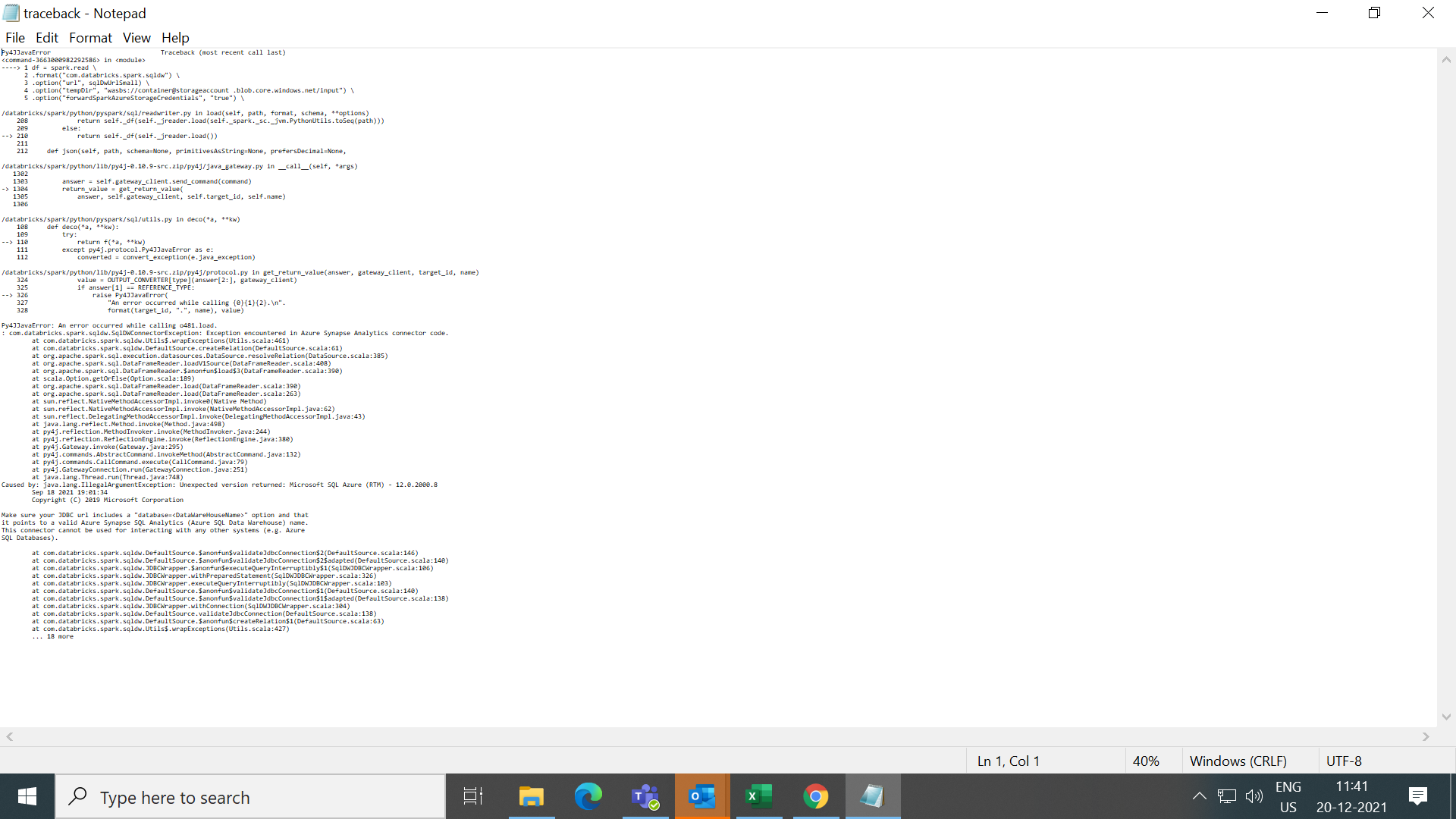
Hello @Ullas Mulbagal Sripathi Rao ,
Thanks for the question and using MS Q&A platform.
Compared to the built-in JDBC connector, this connector provides the ability to bulk insert data into SQL databases. It can outperform row-by-row insertion with 10x to 20x faster performance. The Spark connector for SQL Server and Azure SQL Database also supports Azure Active Directory (Azure AD) authentication, enabling you to connect securely to your Azure SQL databases from Azure Databricks using your Azure AD account. It provides interfaces that are similar to the built-in JDBC connector. It is easy to migrate your existing Spark jobs to use this connector.
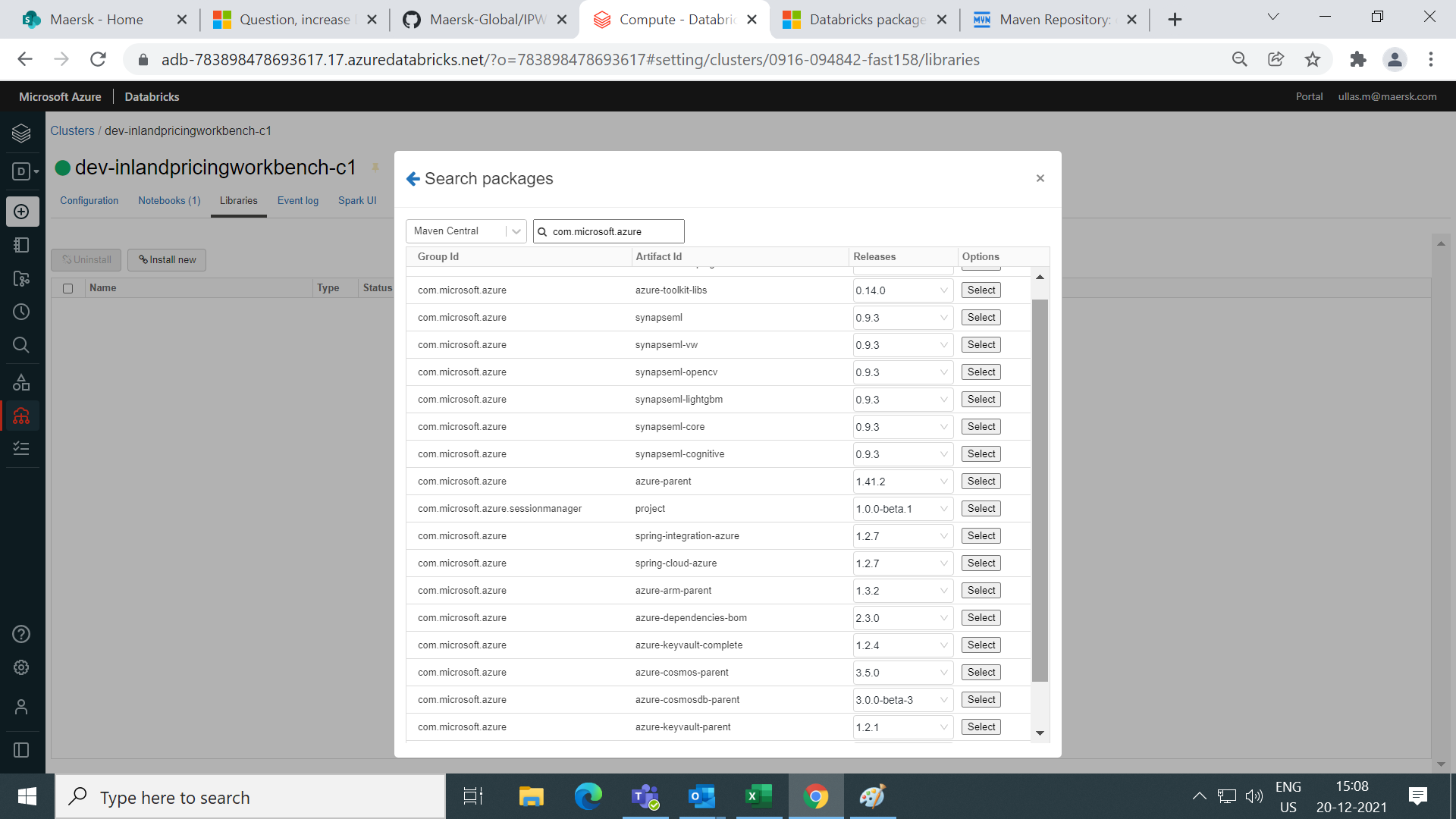
How to find the Azure Spark Connector in Azure Databricks?
Go to libraries => Install New => Select Maven => Maven Search => spark-mssql-connector_2.12
For more details, refer to SQL Databases using the Apache Spark connector.
For instructions on using the Spark connector, see Apache Spark connector: SQL Server & Azure SQL.
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Ullas Mulbagal Sripathi Rao ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
i am analysing the issue yet. I will revert with feedback soon
i am not able to import the com.microsoft.sqlserver package from databricks. please advise
Hello @Ullas Mulbagal Sripathi Rao ,
If you are using JDBC connector you no need to import any packages.
Reference: SQL databases using JDBC
If you are using Apache Spark Connector you need to import the below packages as per the Databricks Runtime which you are using:
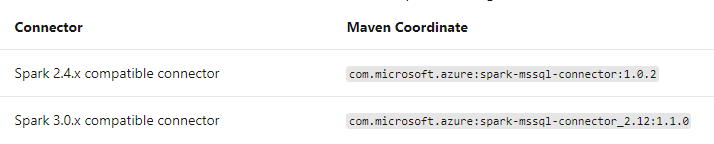
Reference: SQL Databases using the Apache Spark connector
In order to investigate further, could you please share the below details:
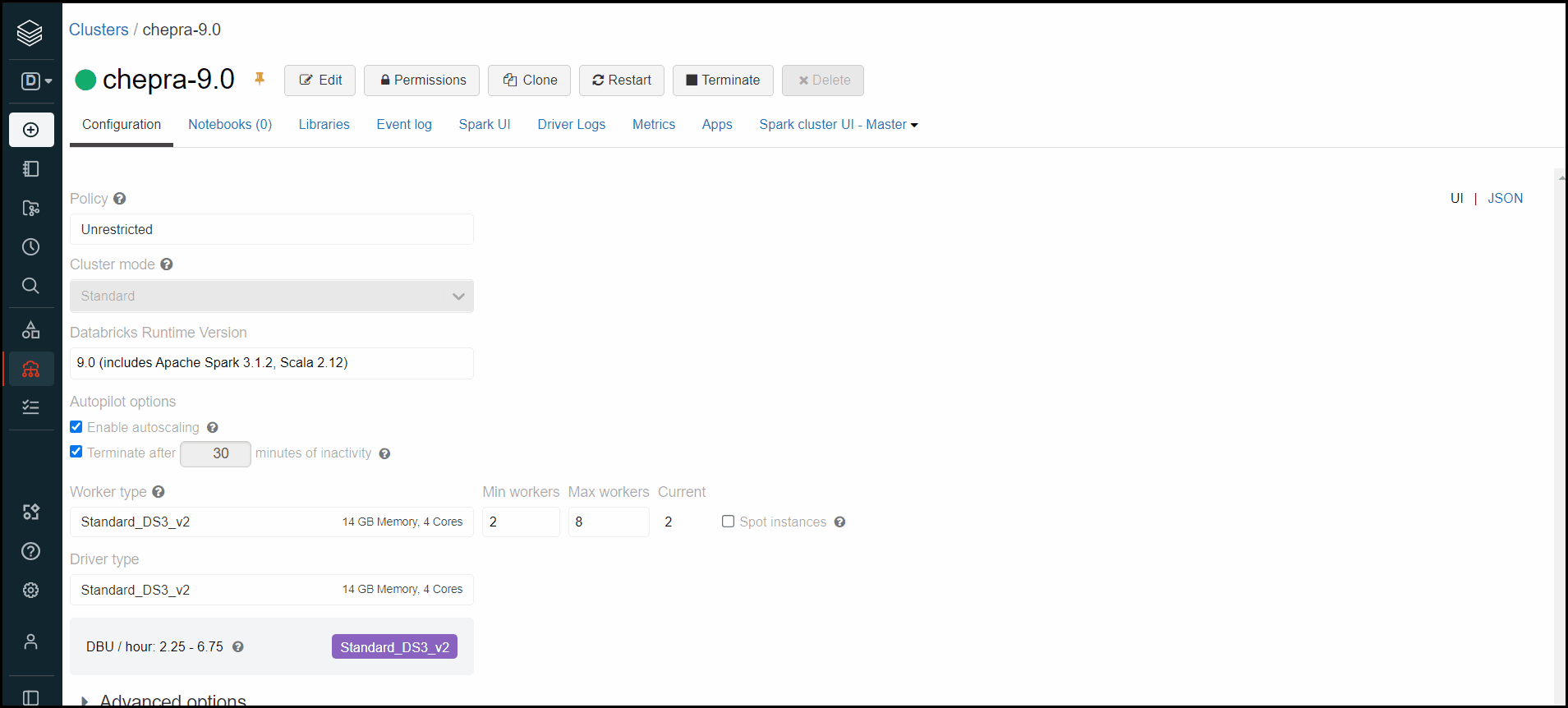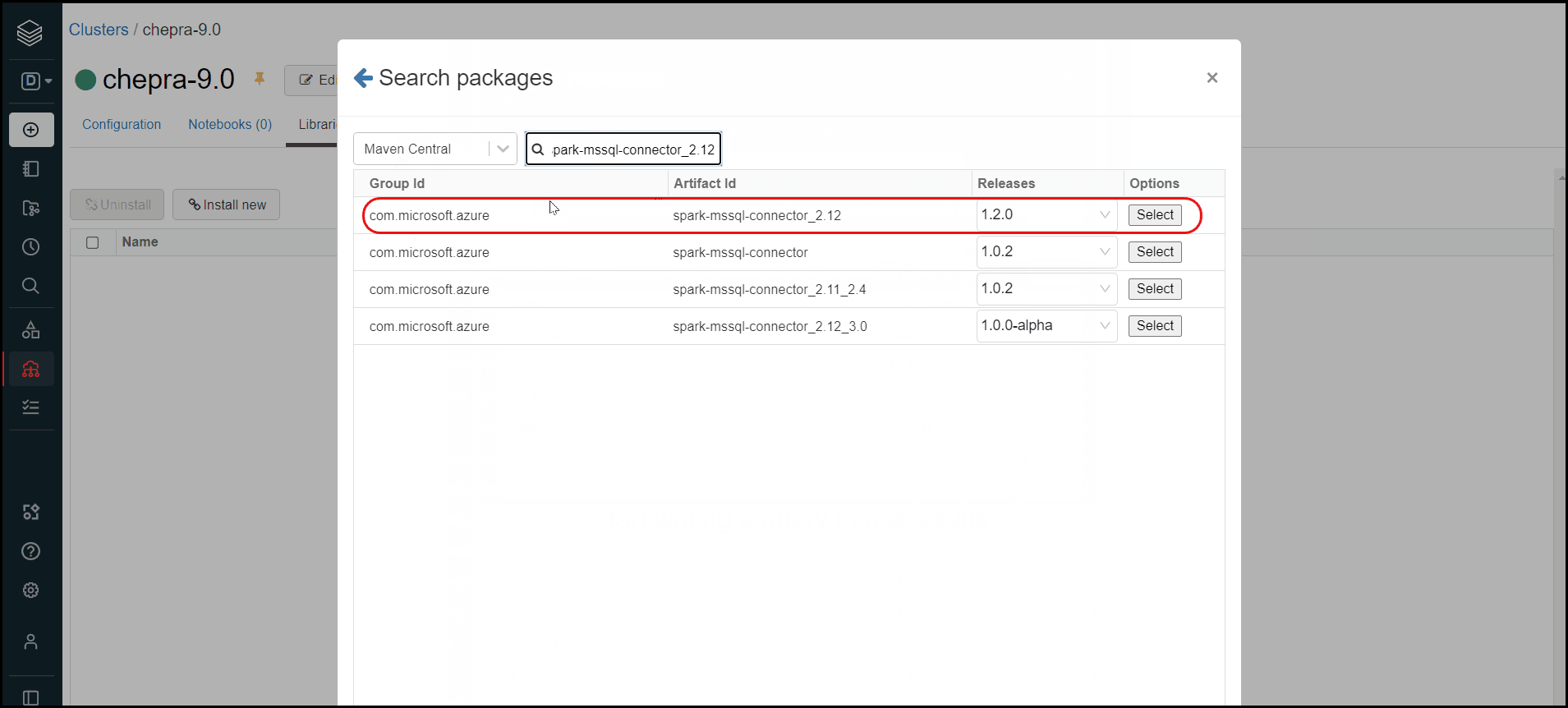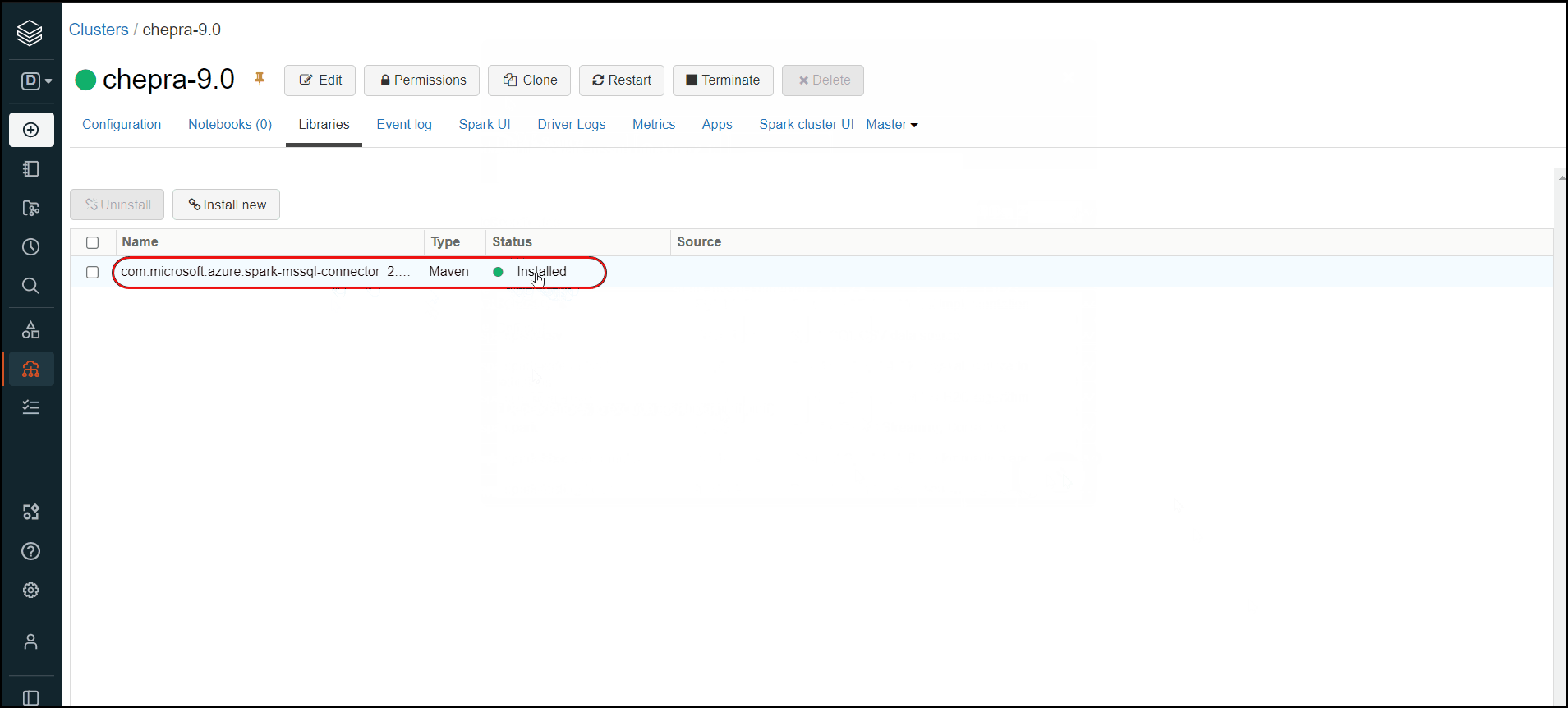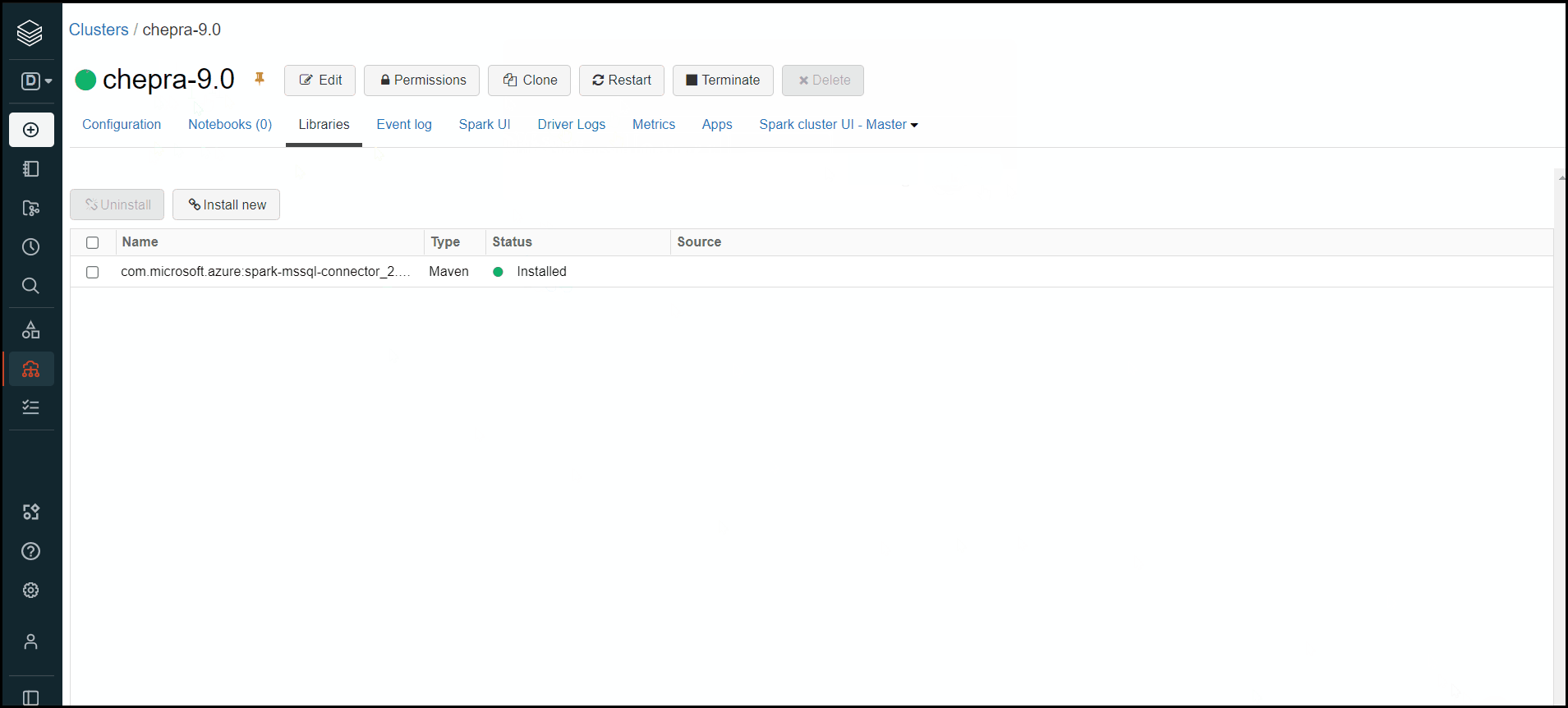
seems like the pacakges are not avaialbe to use the code . i get the below error.
kindly suggest on how to import the packages to databricks.
i am not very much sure of how to use maven packages via databricks
code:
df.write.format("com.microsoft.sqlserver.jdbc.spark").mode("overwrite").option("url", sqlDwUrlSmall).option("dbtable", sqlDwhTbl).option("user", dwUser).option("password", dwPass).save()
error
ClassNotFoundException: Failed to find data source: com.microsoft.sqlserver.jdbc.spark. Please find packages at http://spark.apache.org/third-party-projects.html
Caused by: ClassNotFoundException: com.microsoft.sqlserver.jdbc.spark.DefaultSource
hi, I am currently using the JDBC connector but it is too slow . for 3 M records it takes more than an hour to load from db. I think apache spark connector perfrms faster . but it needs a maven connection. I havent tried to download the package from Maven to databricks
. kindly provide with few documentations which help me to connect to maven from databricks
Hello @Ullas Mulbagal Sripathi Rao ,
Could you please try the below steps and see if you are able to install the package:
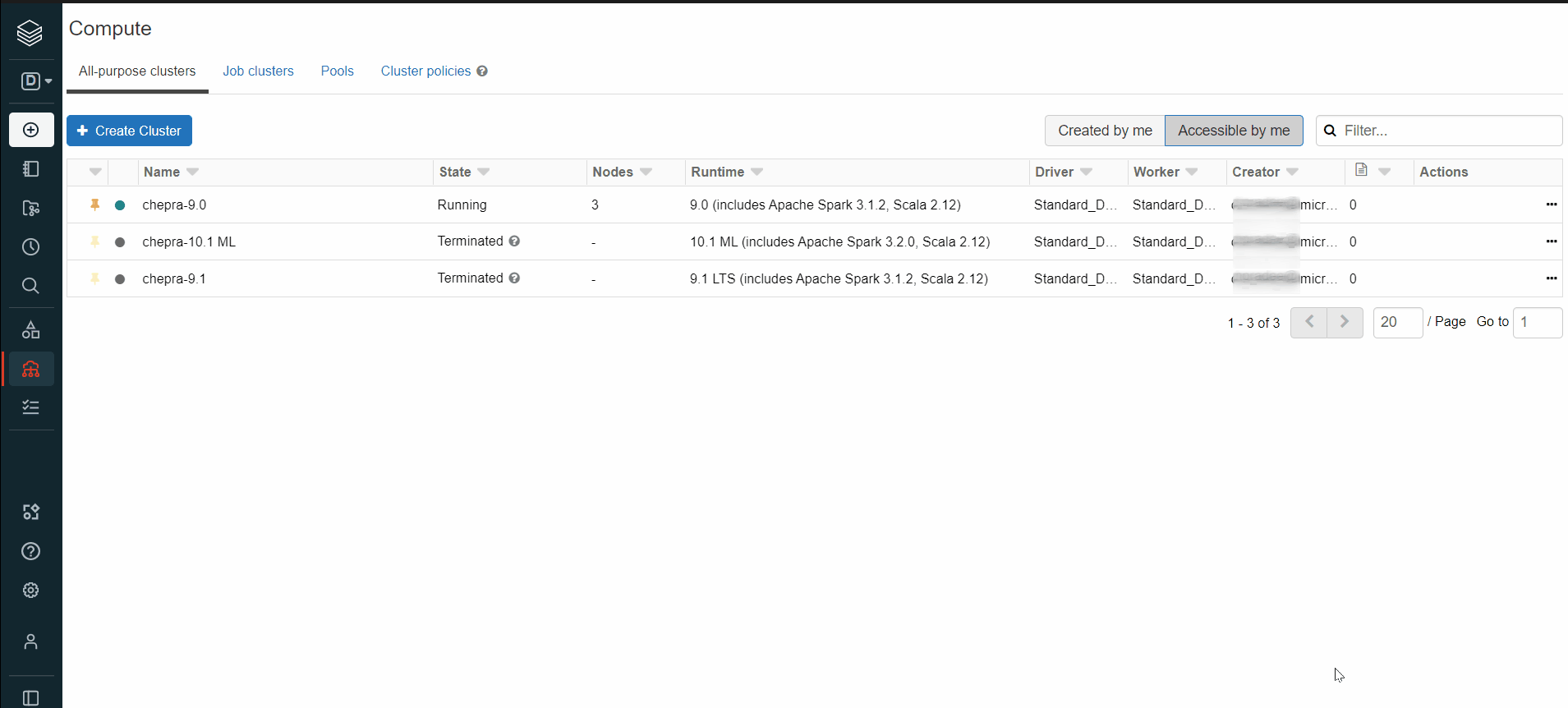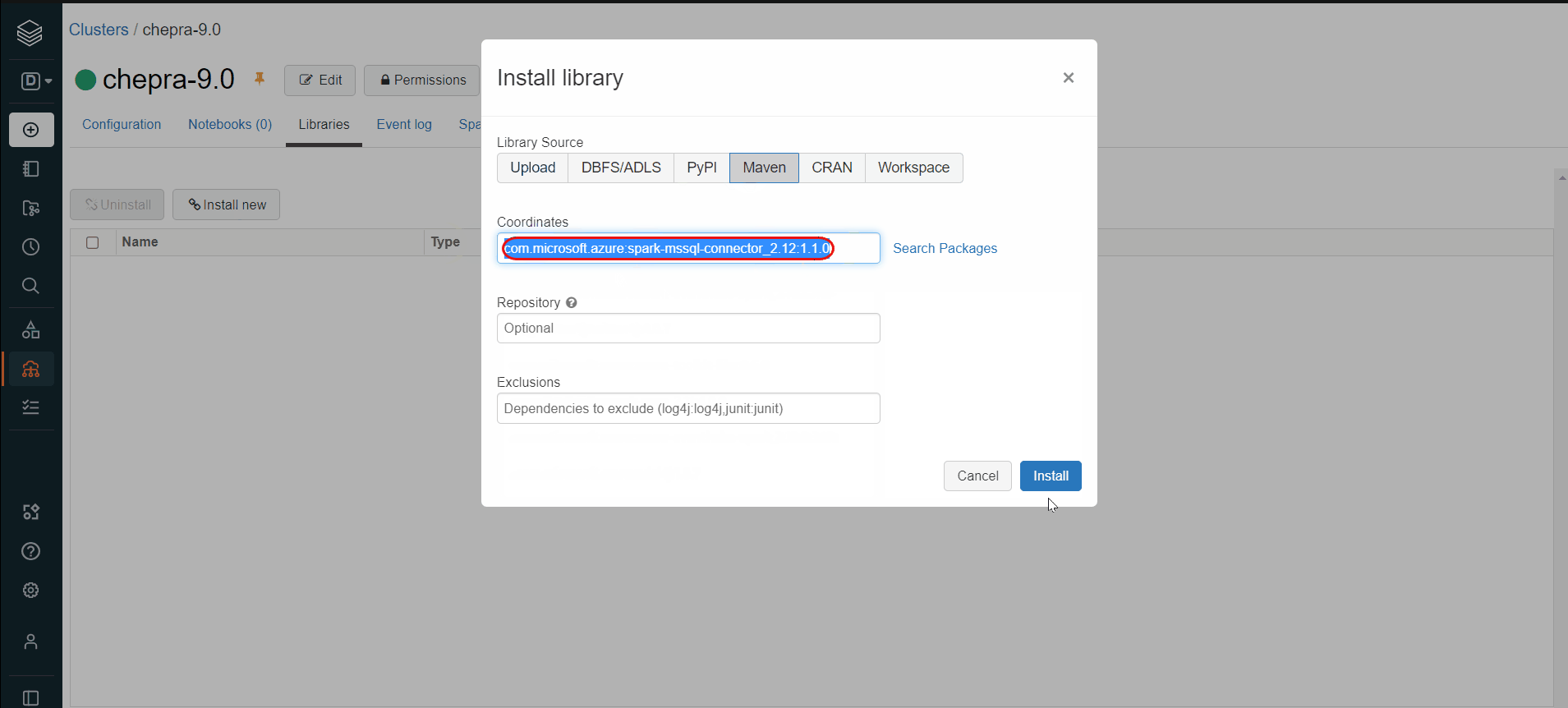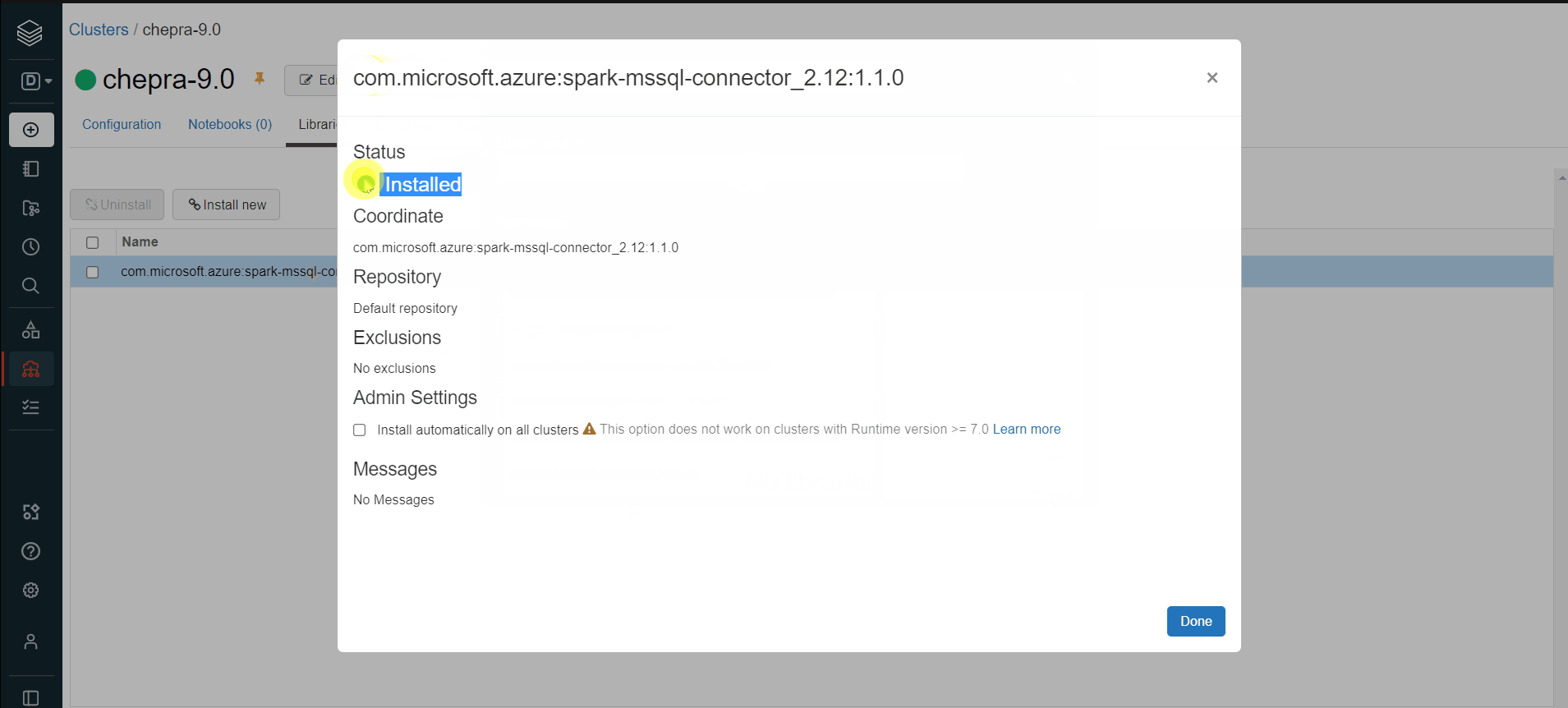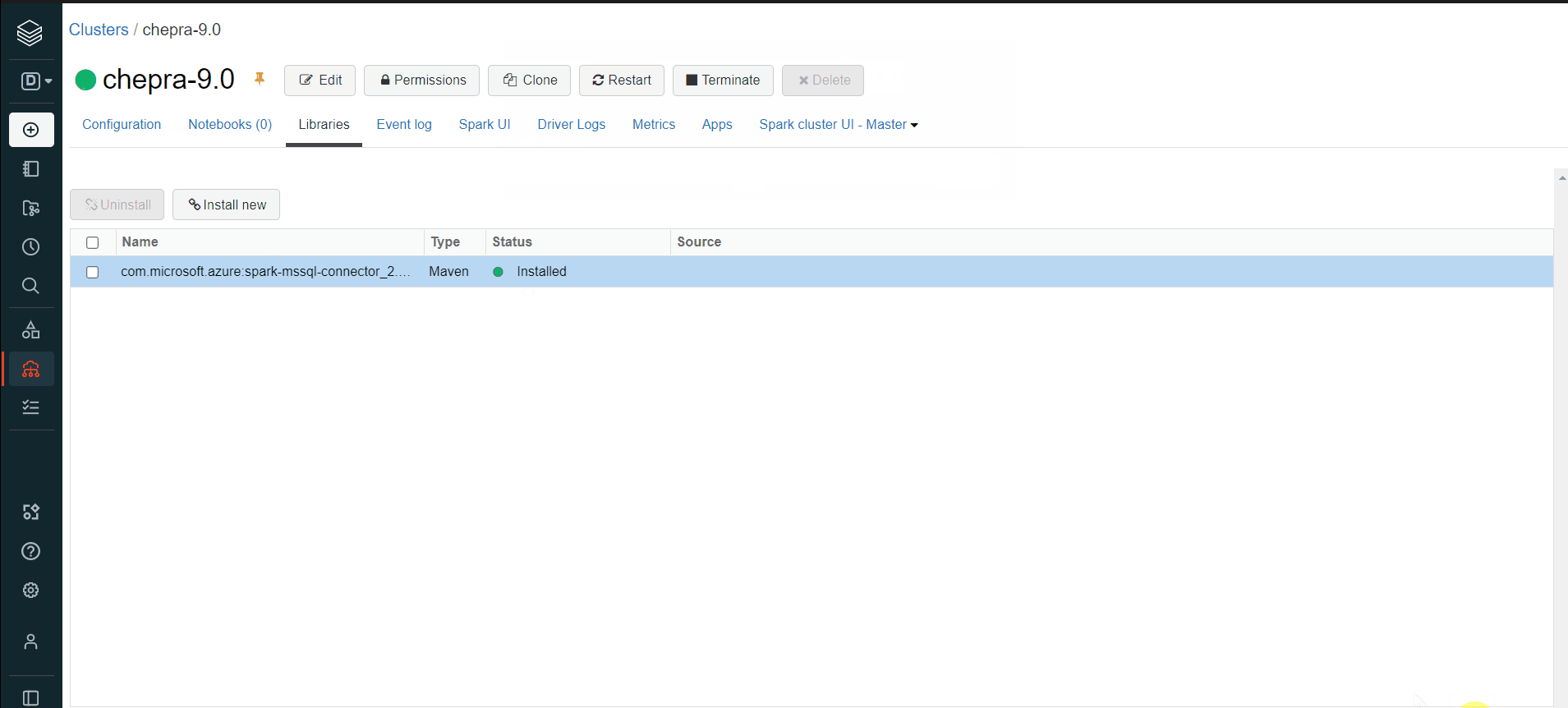
Hope this will help. Please let us know if any further queries.
thanks, but I dont seem to find that package listed when I follow the steps.
unfortunately, I