Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPJ%3C/text%3E%3C/svg%3E)
Hi All,
I have multiple pipelines that uses DataFlow and thus all these DataFlows create their own cluster when the pipeline executes.
Is it possible that i create a dedicated cluster and use that in all my DataFlows instead of DataFlows creating their personal clusters?
If the above scenario is not possible then which offering can be used to run multiple python code on a dedicated cluster apart from DataBricks and Azure Batch as we don't have permissions to use these two offerings in our project.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hi @Priya Jha ,
Thanks for using Microsoft Q&A forum and posting your query.
By default, every data flow activity spins up a new Spark cluster based upon the Azure Integration Runtime (IR) configuration. Cold cluster start-up time takes a few minutes. If your pipelines contain multiple sequential data flows, you can enable a time-to-live (TTL) value, which keeps a cluster alive for a certain period of time after its execution completes. If a new job starts using the IR during the TTL duration, it will reuse the existing cluster and start up time will be greatly reduced.
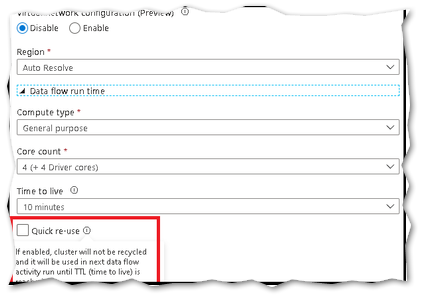
After the second job completes, the cluster will again stay alive for the TTL time.
You can additionally minimize the startup time of warm clusters by setting the "Quick re-use" option in the Azure Integration runtime under Data Flow Properties. Setting this to true will tell the service to not teardown the existing cluster after each job and instead re-use the existing cluster, essentially keeping the compute environment you've set in your Azure IR alive for up to the period of time specified in your TTL. This option makes for the shortest start-up time of your data flow activities when executing from a pipeline.
However, if most of your data flows/pipelines execute in parallel, it is not recommended that you enable TTL for the IR that you use for those activities. Only one job can run on a single cluster at a time. If there is an available cluster, but two data flows start, only one will use the live cluster. The second job will spin up its own isolated cluster.
Is it possible that i create a dedicated cluster and use that in all my DataFlows instead of DataFlows creating their personal clusters?
- No, it is not possible. This is possible in Azure Databricks but not in ADF as the clusters are managed by ADF.
If the above scenario is not possible then which offering can be used to run multiple python code on a dedicated cluster apart from DataBricks and Azure Batch as we don't have permissions to use these two offerings in our project.
- Other than Databricks and Azure Batch, you may try exploring Azure Synapse Analytics Notebooks to execute your Python code. Synapse notebooks (Nothing but Apache Spark Notebooks) support four Apache Spark languages:
a) PySpark (Python)
b) Spark (Scala)
c) Spark SQL
d) .NET Spark (C#)
To explore more about Synapse notebooks, please refer here - Create, develop, and maintain Synapse notebooks in Azure Synapse Analytics
Hope this info helps.
----------
 and upvote
and upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Priya Jha ,
Just checking in to see if the any of the above answers helped. If it answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hello @Priya Jha ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.

ADF mapping data flows utilize "serverless" compute via Azure Integration Runtime. When you execute your data flow activity and for debugging purposes, ADF automatically utilizes and ephemeral Spark compute for you so you don't have to manage the clusters. If you want to do that yourself, you can go into the Azure portal and stand-up your own Azure Databricks account and manage the clusters there. You will have to write the code yourself manually using Notebooks and then execute that code from an ADF pipeline.
If you'd like ADF to maintain the clusters for you rather than stand-up and tear-down on every data flow execution, set an appropriate time-to-live (TTL) and use "quick re-use". This will keep the clusters alive for the period of time that you specify and those clusters will be only available to your factories.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMD%3C/text%3E%3C/svg%3E)
@MarkKromer-MSFT , @KranthiPakala-MSFT Is this something that's going to change in the near future ?
We are thinking of switching our complete SSIS solution for a DW that we use at different customers to ADF with Mapping Data Flows.
But I have some concerns about the processing and cost. So lets say we have 100 SSIS packages, with SSIS we can start many packages in parallel by using foreach activities (staging dimensions and facts can run in parallel for example). The SSIS processing is handled by
Now using Mapping Data Flows this would mean that with parallel processing, a new cluster would spin up foreach staging dimension that is executed in the parallel activity, lets say we have set it to execute 8 data flows in parallel.
As I see it, only sequential executions of data flows can reuse the same cluster with TTL. Is there a possibility to have something similar as the SSIS processing, where you have one cluster doing all the work, saying execute 8 data flows at the time, or even if needed select the number of clusters to use (like the nodes in SSIS-IR)?
We use the power of parallelism to speed things up, this is possible with SSIS-IR at low cost, but with ADF Data Flow this is a bit harder to manage and more costly.
So are there any solutions or workarounds for this problem or any future changes that would resolve this ?
This can be done by the use of databricks, but this is not so accessible for customers who would like to do their own development with a nice GUI and easy to maintain environment.