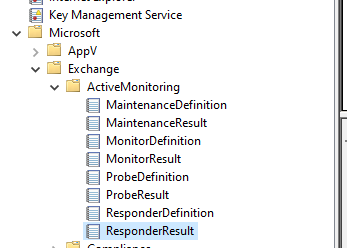
Hello, we have a problem on both DAG members that the MS replication service crashes about 2~3x per hour with event ID 4399:
The Microsoft Exchange Replication service is terminating without collecting a Watson dump. Error The Microsoft Exchange Replication service is using too much memory (2704.921875 MiB) and will be terminated without collecting a Watson dump. This exceeds the maximum expected value of 2176 MiB. To take a dump along with the Watson report, set registry key 'EnableWatsonDumpOnTooMuchMemory' to 1. Default can be overridden by setting registry key MaximumProcessPrivateMemoryMB, MemoryLimitBaseInMB, MemoryLimitPerDBInMB. EffectiveLimit=Min(MaximumProcessPrivateMemoryMB, MemoryLimitBaseInMB + nCopiesMemoryLimitPerDBInMB).*
The "too much memory" is usually in 2180~2800MiB range. We found our issue matches to this E2k13 Technet article (and then soved by next CU..) :
https://social.technet.microsoft.com/Forums/windowsserver/en-US/59a9de69-01e9-436d-95bb-ff1126c0dd6e/ms-exchange-replication-service-terminating-constantly?forum=exchangesvravailabilityandisasterrecovery
Both Technet article and Event descr. itself suggest the same - to add new reg keys MaximumProcessPrivateMemoryMB and MemoryLimitBaseInMB to increase default limit, eg. event desc. also means that MemoryLimitPerDBInMB can be related.
So we tried to set up those MaximumProcessPrivateMemoryMB and MemoryLimitBaseInMB limits first: No change.
Then I tried to calculate what is the default/current MemoryLimitPerDBInMB limit but the mentioned "EffectiveLimit=Min(MaximumProcessPrivateMemoryMB, MemoryLimitBaseInMB + nCopiesMemoryLimitPerDBInMB)" formula is probably wrong and should be "EffectiveLimit=Min(MaximumProcessPrivateMemoryMB, MemoryLimitBaseInMB, nCopiesMemoryLimitPerDBInMB)" in fact (?) otherwise it leads to "minus" value of PerDB parameter .
I think our situation was:
MaximumProcessPrivateMemoryMB 8192 (extra added as suggested in E2k13 KB)
MemoryLimitBaseInMB 4096 (extra added as suggested in E2k13 KB)
MemoryLimitPerDBInMB ? (unknown/not set up yet)
EffectiveLimit 2176 MiB = 2281.701376 MB (as event said)
nCopies 4 (we have 4x DBs)
So the modified formula says: 2281.701376 = Min ( 8192, 4096, 4*MemoryLimitPerDBInMB ) .... what means MemoryLimitPerDBInMB is 570.425344 MB (544 MiB)
So we also added the next (hopefuly increased) DWORD value reg. as MemoryLimitPerDBInMB = 768 (and then restarted service, server for sure)
But none has changed in fact the repl. service still crashes with "This exceeds the maximum expected value of 2176 MiB" error message...
Can anyone help please? Are those REG settings really manage the "Microsoft Exchange Replication" service's parameters in E2k16 like it did in E2k13? Of course maybe we are generally wrong here... Generally the 1st problem is why it requires so much memory and 2nd one is how to fix it...
FYI: We are currently facing to bigger issue than "only the sometimes crashing repl. service". Due to this we cannot perform new DAG DBs copies for larger DBs because process simply cannot seed xxxGBs before the next service's crash which is happening on both send/receive DAG members. Only 2 of 4 smaller DBs have been already transferred within those short 20~30min windows and then they normally work in synchronized DB active/pasive mode in DAG.
Thank you!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKY%3C/text%3E%3C/svg%3E)