Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EB%3C/text%3E%3C/svg%3E)
For some reason spark is not reading the data correctly from xlsx file in the column with a formula. I am reading it from a blob storage.
Consider this simple data set

The column "color" has formulas for all the cells like
=VLOOKUP(A4,C3:D5,2,0)
In cases where the formula could not return a value it is read differently by excel and spark:
excel - #N/A
spark - =VLOOKUP(A4,C3:D5,2,0)
Here is my code:
df= spark.read\
.format("com.crealytics.spark.excel")\
.option("header", "true")\
.load(input_path + input_folder_general + "test1.xlsx")
display(df)
And here is how the above dataset is read:
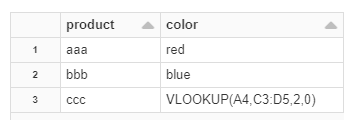
How to get #N/A instead of a formula?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @braxx ,
Thanks for the ask and using Microsoft Q&A platform .
Have you tried the options "setErrorCellsToFallbackValues" to check if will help ? I think its will not give you "N/A" as asked but may toggle beyween 0 and 1 . You can read about this more here https://github.com/crealytics/spark-excel#create-a-dataframe-from-an-excel-file
spark.read
.format("com.crealytics.spark.excel") // Or .format("excel") for V2 implementation
.option("dataAddress", "'My Sheet'!B3:C35") // Optional, default: "A1"
.option("header", "true") // Required
.option("treatEmptyValuesAsNulls", "false") // Optional, default: true
.option("setErrorCellsToFallbackValues", "true") // Optional, default: false, where errors will be converted to null. If true, any ERROR cell values (e.g. #N/A) will be converted to the zero values of the column's data type.
.option("usePlainNumberFormat", "false") // Optional, default: false, If true, format the cells without rounding and scientific notations
.option("inferSchema", "false") // Optional, default: false
.option("addColorColumns", "true") // Optional, default: false
.option("timestampFormat", "MM-dd-yyyy HH:mm:ss") // Optional, default: yyyy-mm-dd hh:mm:ss[.fffffffff]
.option("maxRowsInMemory", 20) // Optional, default None. If set, uses a streaming reader which can help with big files (will fail if used with xls format files)
.option("excerptSize", 10) // Optional, default: 10. If set and if schema inferred, number of rows to infer schema from
.option("workbookPassword", "pass") // Optional, default None. Requires unlimited strength JCE for older JVMs
.schema(myCustomSchema) // Optional, default: Either inferred schema, or all columns are Strings
.load("Worktime.xlsx")
My apoloziges I was not able to test it as I am struggling to install the library on the cluster .
Please do let me know how it goes .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
thanks,
Unfortunatelly setting option "setErrorCellsToFallbackValues" does not change anything. Tried with both TRUE and FALSE and still could found the formula in the output
Hello @braxx ,
Thanks for the patience , unfortunately we are not getting the kind of response from the team here . if you have a support plan you may file a support ticket, else could you please send an email to azcommunity@microsoft.com with the below details, so that we can create a one-time-free support ticket for you to work closely on this matter.
Subscription ID:
Subject : Attn Himanshu
Please let me know once you have done the same.
Thanks
Himanshu
Hello @braxx ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if have already reached out to the Microsoft Support , please do share the SR# , otherwise request you to please do the needful as requested in the last response .
Thanks
Himanshu
Hello @braxx ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if have already reached out to the Microsoft Support , please do share the SR# , otherwise request you to please do the needful as requested in the last response .
Thanks
Himanshu
Hello,
Appologise for a late answer. I have sent an email with a request to open the ticket
Thank you
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMI%3C/text%3E%3C/svg%3E)
I wanted to know how can i use .format("excel"). Currently I am able to use .format("com.crealytics.spark.excel") but not the other one. Can anyone tell why is this so ?