Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,696 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECM%3C/text%3E%3C/svg%3E)
New to Synapse.... I am trying to ingest data from an on-prem sql server using a pipeline in Synapse.
I am using the copy data task. My source seems to work fine, I can view data, connection test fine. The source is the issue. I have had some success with csv files. I can run the copy activity with success. On the data hub, I can see my file. I can right click and select preview and see data. When I right click and select, new sql script, select top 10000 rows I get a query editor and some sql. I run the sql and get no records returned.
When I follow the exact same procedure, but use a parquet file type. My pipeline fails. why would it work for csv, but not parquet?
Do I need to load into my synapse workspace and then to the data lake? The fact that I see two directories in my storage is confusing. I see a few files in both places and one in only the workspace. Is there documentation and when to use the data lake and when to use the workspace? and how the two interact?
meant to say... the sink is the issue... don't see where I can edit.

Hi @Computer Mike ,
Thanks for using Microsoft Q&A platform and posting your query.
Could you please share screenshot for better understanding of the issue. What is the error you are getting when trying Parquet format as the Sink data type.
Hi @Computer Mike ,
Following up to see if the suggestion provided was helpful, kindly do click Accept Answer and Up-Vote for the same. In case you have any further query please do let us know.
I figured out why I can not use a parquet file because I don't have the proper drive on the SQL server machine. So I will try to fix that later.
I have created a pipeline and it runs successfully. On the Data hub, under linked services, I can click on my storage, go into my folder and see my csv file. I can right click, preview and see data.
I right clicker and select "select top 100" and I get a script like..
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://x._d0312a15-8bba-4369-9ae2-f82dac15c064_c884101b-fcc6-484b-96d1-6c69608eb1a3.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0'
) AS [result]
this fails, so I added a with clause as the error sugest..
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://x/Raw/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0'
)
WITH
(
UserID int,
UName varchar(64),
UTypId int,
FName varchar(32),
MidInit varchar(4),
LName varchar(32)
) AS [result];
The query seems to run, it returns the column headers, but no records. I did tweak the original url for the data file to hide it.
I am fairly sure my permissions are set up correctly. in the data hub, I right click... manage access and I am the a user with read, write and execute. I am also the owner with read, write and execute.
Hope this additional info helps.
I changed all the varchars in my with clause to something like....FName varchar(32) COLLATE Latin1_General_100_BIN2_UTF8 to get rid of some of the warnings.
this is the error I am getting now.
Error handling external file: 'waitIOCompletion error. HRESULT = 0x80070005(offset = 0, bytes requested = 1048576).'. File/External table name: 'https://x.windows.net/synapseqadatalakegen2fs/Raw/data_d0312
96d1-6c69608eb1a3.csv
I can run the query, "select 1" and get a result.
Hi @Computer Mike ,
It seems that each row in your CSV doesn't have the correct number of fields, so it cannot be parsed. You can resolve this by amending your .CSV file to have equal number of comma separated fields in each of the rows. Please check the file should not be corrupted or data should not be in wrong format. If this is not the case then, I would request you to kindly share the screenshot of the data you are trying to fetch.
I tried to repro your scenario and did not get any error.
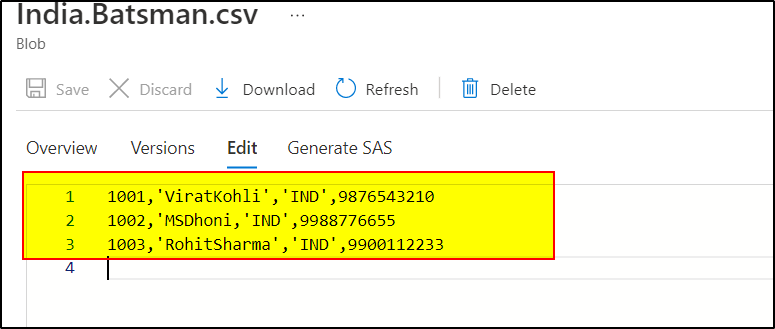
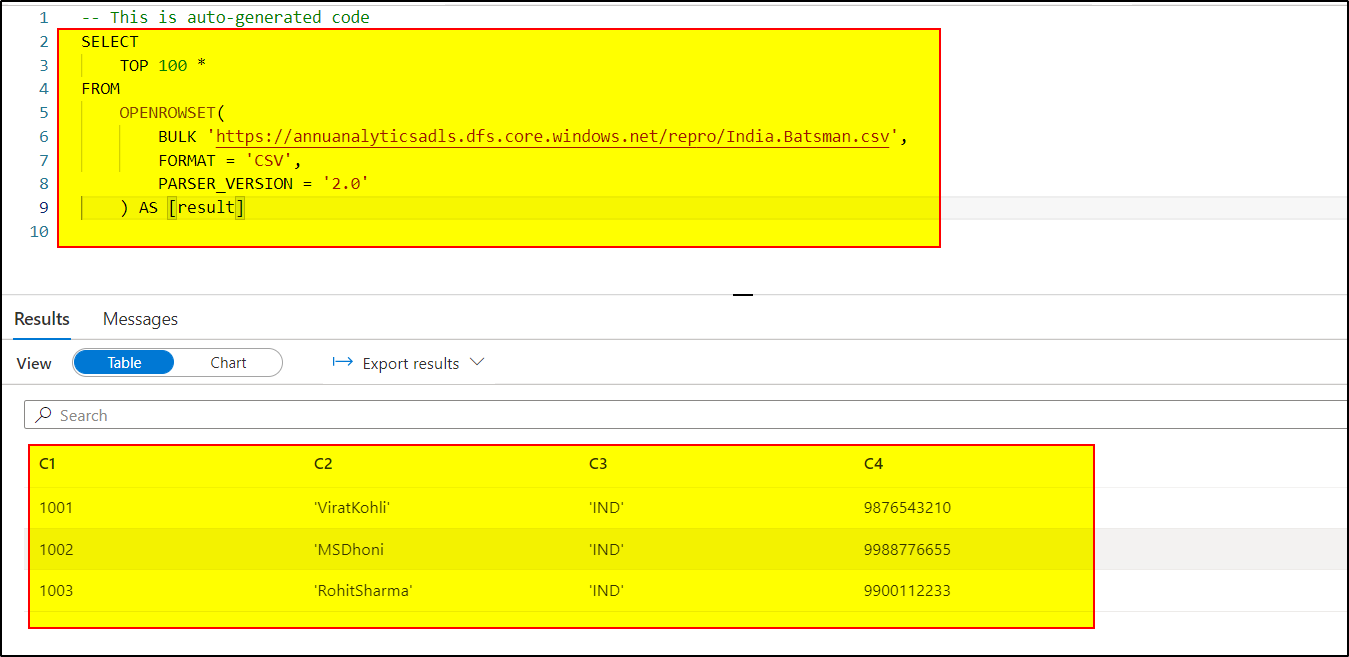
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @Computer Mike ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.