
4,707 questions

Composing a good performance test is a big challenge. There are so many ways you can go wrong. Not the least you may be so focused on the test, that you loose the connection to your actual workload, so that you test something which is not relevant. I know; I've been there myself many times.
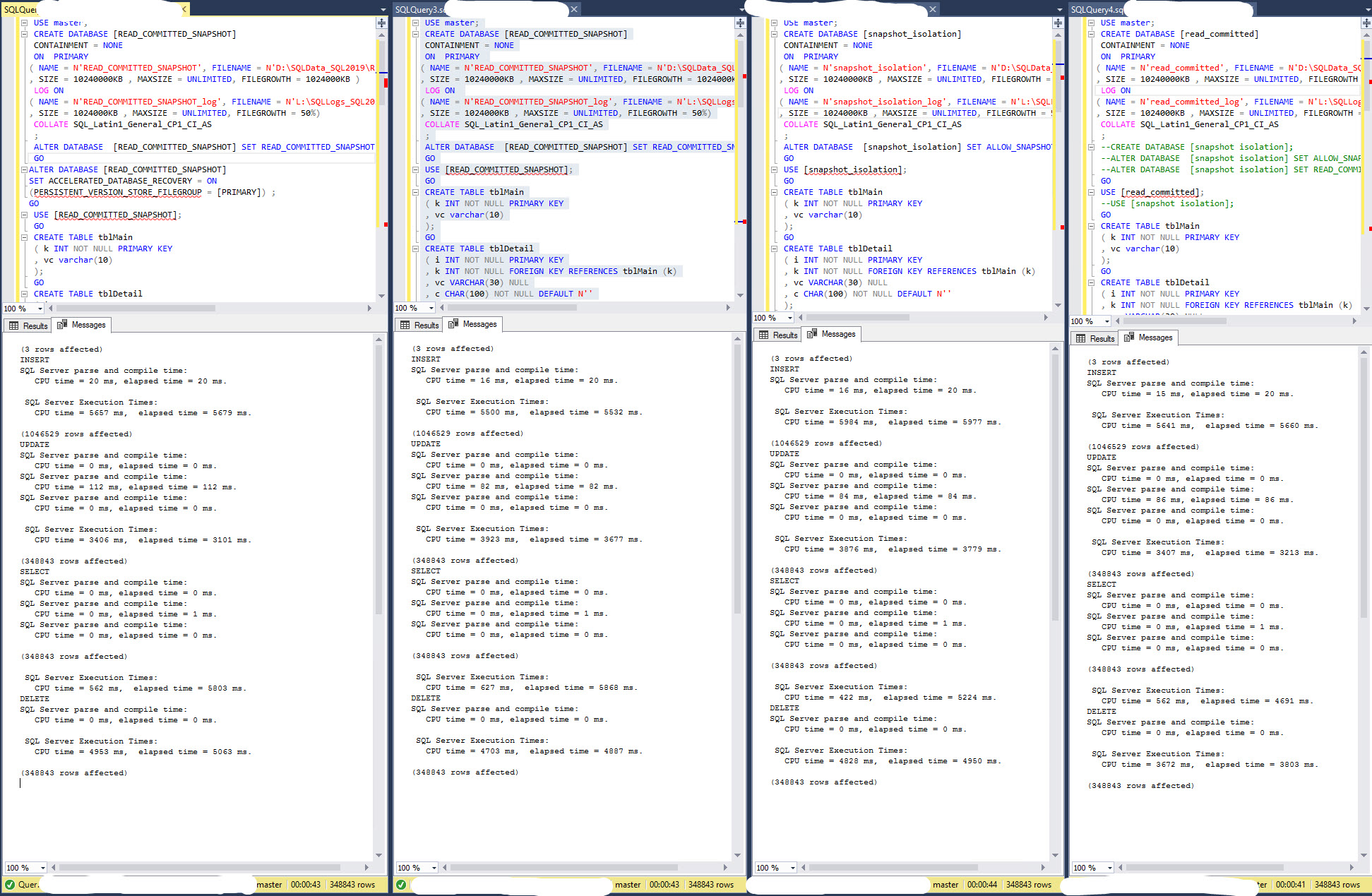
I played with your script, and I was largely able to repeat your findings, although I did see a decent difference for the UPDATE operation as well.
I tried some variations, and most of them did not change much, but one did: I switched the order of the UPDATE and the DELETE operation. After this, the UPDATE operation in the Snapshot database runs 3-4 times. longer than in the ReadCommitted database. But not because things are now slower in the Snapshot databsae, but there is a drastic speedup in the ReadCommitted database!
I have some data from tests where my main focus was to try different chunking solutions. That is, break up big operations in chunks to gain speed, and hold down the transaction log. I have main run these tests in plain read committed, but I also have a set of data with the database with READ_COMMITTED_SNAPSHOT. I looked at that data and compared the results for the same operation with plain RC and RCSI, and there is quite a bit of variation. But generally, UPDATE and DELETE operations suffers quite a bit from the snapshot handling, while the INSERT operations not so much, at most 25%. As compared to over 300% for the most affected UPDATE operation and 140% for the most affected DELETE operation. (In my tests, I restored the source database for every test run, so the starting point is always the same.)
All my tests were on a laptop - not really production-grade hardware!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EVM%3C/text%3E%3C/svg%3E)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)