Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,198 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECH%3C/text%3E%3C/svg%3E)
I am running a pipeline in Azure Data Factory and while running this pipeline there are multiple Data Flows that need to be executed. The first data flow executes and acquires compute for the Integration Runtime. Although once the next data flow begins running, it attempts to acquire compute once again. This seems to be unexpected behavior as the TTL for the integration runtime is greater than the time it takes for the first data flow to execute and the second to begin. (TTL = 10min, Elapsed DF time < 1s).
All data flows point to this integration runtime, for the purpose that once it is acquired it does not have to be acquired again. Can someone please detail why a data flow that executes after another data flow that use the same integration runtime has to re-acquire the compute cluster, and then what I can do to be sure that it uses the already acquired IR?
Thank you.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hello @CJ Hillbrand ,
We still have not heard back from you. Just wanted to check if the below suggestion was helpful? If it answers your query, please do click Accept Answer and/or Up-Vote, as it might be beneficial to other community members reading this thread. And, if you have any further query do let us know.
Hello @CJ Hillbrand ,
Thanks for the question and using MS Q&A platform.
As per the description, my understanding is that you have an Azure IR with TTL set (the Quick re-use feature unchecked/disabled). And you would want to know why the Azure IR trying to acquire compute resources even though TTL is enabled. Pls correct if my understanding is incorrect.
By default, every data flow activity spins up a new Spark cluster based upon the Azure IR configuration. Cold cluster start-up (nothing but spinning a new a cluster) time takes a few minutes and data processing can't start until it is complete. If your pipelines contain multiple sequential data flows, you can enable a time to live (TTL) value. Specifying a time to live value keeps a cluster alive (Just the cluster is alive but the resources/VMs will be paused) for a certain period of time after its execution completes (nothing but after last dataflow job execution is completed). If a new job starts using the IR during the TTL time, it will reuse the existing cluster and start up (nothing but to restart the paused resources from existing cluster) time will greatly reduced. After the second job completes, the cluster will again stay alive for the TTL time.
You can additionally minimize the startup time of warm clusters (already spined up cluster) by setting the Quick re-use option in the Azure Integration runtime under Data Flow Properties. Setting this to true will tell the service to not teardown the existing cluster after each job and instead re-use the existing cluster, essentially keeping the compute environment you've set in your Azure IR alive for up to the period of time specified in your TTL. This option makes for the shortest start-up time of your data flow activities when executing from a pipeline.
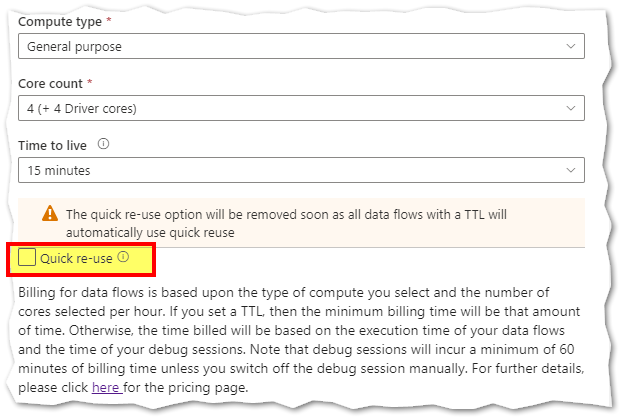
Hope this info helps. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how