Developer technologies | Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EWS%3C/text%3E%3C/svg%3E)
1 . ) How to count consecutive values across rows? Start from zero and count cumulatively each time the value repeats. Restart from zero each time the value changes.
Example:
SomeValue ConsecutiveCount
1 0
1 1
1 2
0 0
1 0
1 1
Attached script creates a db with two tables that shows an attempt to accomplish the above.
2 . ) Query in attached script is obviously incorrect with respect to accomplishing the task stated above. That said, the results returned by the query appear to be inconsistent and unmatchable to any pattern demonstated in the data. For example the following row returned by the query against TableB shows a value of 2 in the SameConsecutiveResponseCount column:
2018-03-14 00:00:00.000 67115991 1 0 2
For the query as written in the attached script, how is the value 2 calculated? What does the value 2 represent?
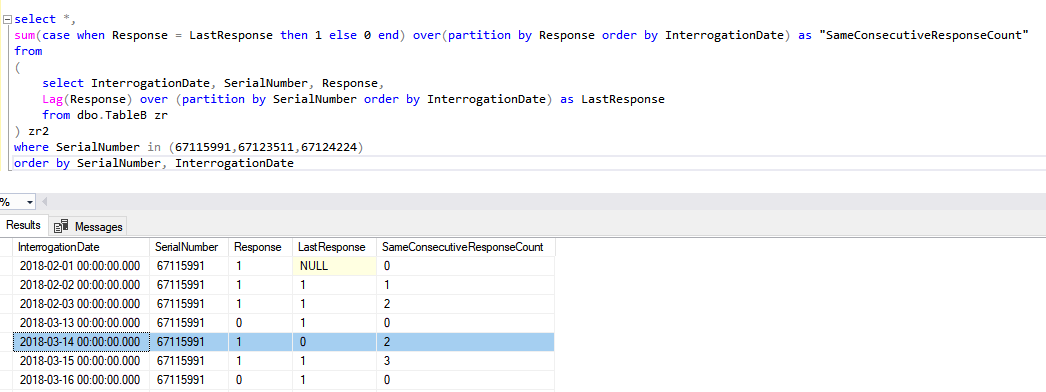
3 . ) The same query as the attached run against the same data on our production server yields different results. I had to truncate some data to keep the example small, however as shown in the screen cap below the SameConsecutiveResponseCount starts at 3 and increments by 3 for each row. The first three rows on the prod server are exactly the same as what is provided in the example. At a minimum I would expect those rows to return identical results. Why does this occur?

169098-consecutive-values-problem.txt
select @@version
Microsoft SQL Server 2019 (RTM-GDR) (KB4583458) - 15.0.2080.9 (X64) Nov 6 2020 16:50:01 Copyright (C) 2019 Microsoft Corporation Developer Edition (64-bit) on Windows 10 Pro 10.0 <X64> (Build 18363: )
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ELM%3C/text%3E%3C/svg%3E)
Hi @Wheat, Samuel G (Contractor)
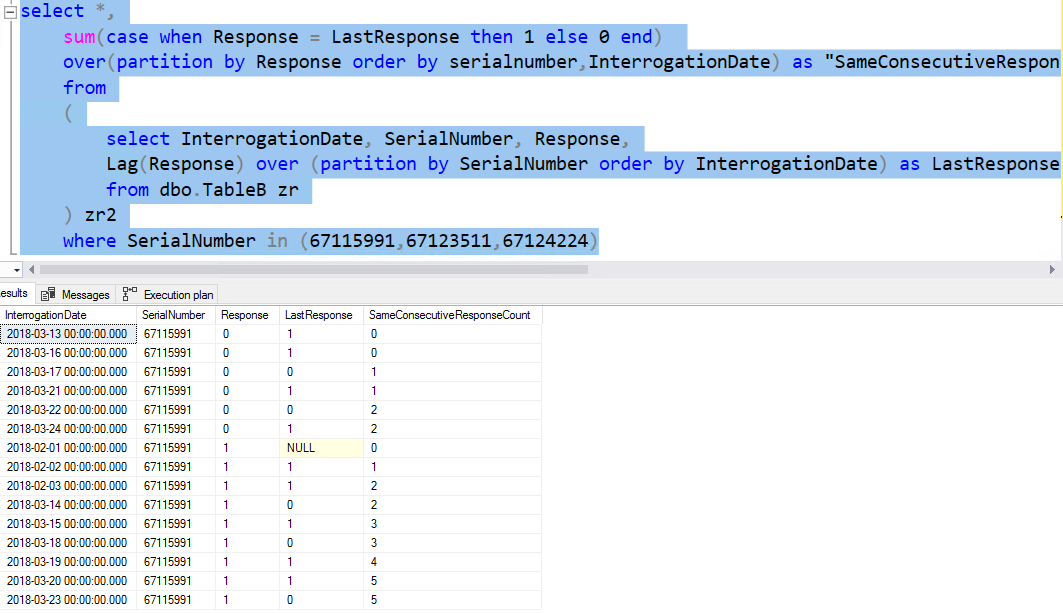
For questions 2.) Because you SUM with partition by Response,which means: " first SUM partition :Response=0" , "second SUM partition :Response=1"
sum(case when Response = LastResponse then 1 else 0 end) over(partition by Response order by InterrogationDate)
Change order by clause to this:order by SerialNumber, Response,InterrogationDate and you will find the reason.
first SUM partition :Response=0" , "second SUM partition :Response=1"
I don't understand what you mean by this. I understand the window function to sum once - the value being summed depends on the comparison of Response/LastResponse.
From the link above:
Divides the query result set into partitions. The window function is applied to each partition separately and computation restarts for each partition.
See also this example:
USE AdventureWorks2012;
GO
SELECT SalesOrderID, ProductID, OrderQty
,SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS Total
,CAST(1. * OrderQty / SUM(OrderQty) OVER(PARTITION BY SalesOrderID)
*100 AS DECIMAL(5,2))AS "Percent by ProductID"
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN(43659,43664);
GO
Here is the result set. Notice that the aggregates are calculated by SalesOrderID and the Percent by ProductID is calculated for each line of each SalesOrderID.
In my case I want to calculate an aggregate by Response ordered by SerialNumber,LastResponse. When Response changes I want to restart the aggragate. Note the phrase computation restarts for each partition. in the documentation cited above. This is the part I don't understand. Why is computation not restarting for each partition?
Why is computation not restarting for each partition?
In fact, your query does restart the computation per partition.
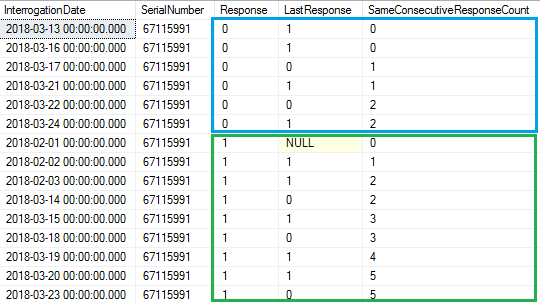
Because there are only 2 partitions :partition 1:Response=0 (Inside the blue rectangle )and partition 2:Response=1 (Inside the green rectangle )
They are sorted incorrectly in the rectangles. The desired sort is by serialnumber, interrogation date. When sorted by those columns the desired functionality is that computation restarts each time Response changes.
They are sorted incorrectly in the rectangles.
Actually,in your query ,they are sorted right.
Please check this document ,as it says 
Therefore the ORDER BY clause in OVER( ... ) only defines the logical order of the rows within each partition of the result set.
Therefore the ORDER BY clause in OVER( ... ) only defines the logical order of the rows within each partition of the result set.
OK this sounds right. The question remains however - Why is computation not restarting for each partition?
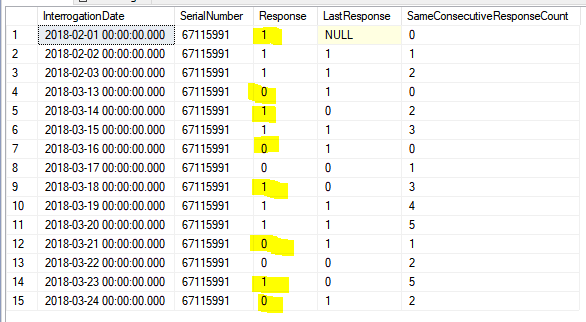
In the screen cap below I have identified the start of each partition in yellow. These are rows where the value in the Response column changes when the rows are sorted by SerialNumber, InterrogationDate.
The expectation is that the value in the SameConsecutiveResponseCount column will be reset to zero for each row where Response is yellow.
It is further expected that the value in SameConsecutiveResponseCount will be incremented by one for each row where the Response column does not change.
When the value in the Response column changes again, it is expected that computation restarts i.e. SUM is set to zero.
The first two partitions in the image below are correct.

OK this sounds right. The question remains however - Why is computation not restarting for each partition?
Because just as LiHong has explained to you: you only have tw partitions.
sum(case when Response = LastResponse then 1 else 0 end) over(partition by Response order by InterrogationDate)
There are only two possible values for Response, 0 and 1. And that is what PARTITION BY means. in an OVER clause PARTITION BY happens first and ORDER BY is applied once the partition has been completed; not the other way round.
There is no way to express in T-SQL what is going on here. In ANSI SQL there is something called Row Pattern Recognition would fit in very well here, but it has yet to appear in SQL Server. (I believe it is only implemented by Oracle and one more product.)
Thanks @Erland Sommarskog I did not understand what @LiHong-MSFT was trying to say.
Now that you explain it, it seems severely crippled - I am not grouping data here.
In any case, thanks for your explanation. This might be a good topic for one of your excellent presentations.
I think LiHong did a very good job of explaining the issue. The point where Li failed was to identify you hiccup, and I can certainly not blame Li for that, since it took me quite a while to see where your error of thinking was.
As for being crippled, the feature works as designed. Keep in mind that computers are very stupid. They never read between the lines and say "Ah, so you mean this" and change the rules.
I said previously that it would be possible to express this in T-SQL that this can be done with a single iteration over the data. I was wrong. My friend Itzik Ben-Gan, who is a lot smarter than me when it comes to T-SQL, was kind to share a solution:
with c as
(
select *,
row_number() over(partition by SerialNumber order by InterrogationDate) as rn,
lag(Response) over(partition by SerialNumber order by InterrogationDate) as
PrevResponse
from dbo.TableB
)
select *,
rn - max(case when Response = PrevResponse then null else rn - 1 end)
over(partition by SerialNumber order by InterrogationDate rows unbounded
preceding) as SeqNo
from c;
As far as I can tell, it gives the desired result.
I can speak for the performance, because I don't have your table, but it is essential that you have this index:
CREATE INDEX SerialNumber_InterrogationDate (SerialNumber, InterrogationDate) INCLUDE (Response)
If the clustered index on the table is on (SerialNumber, InterrogationDate) that should work, but I note that in the script you posted, you have the key columns in TableB in reverse order. That index is not good for this query, because the data has to be re-sorted.

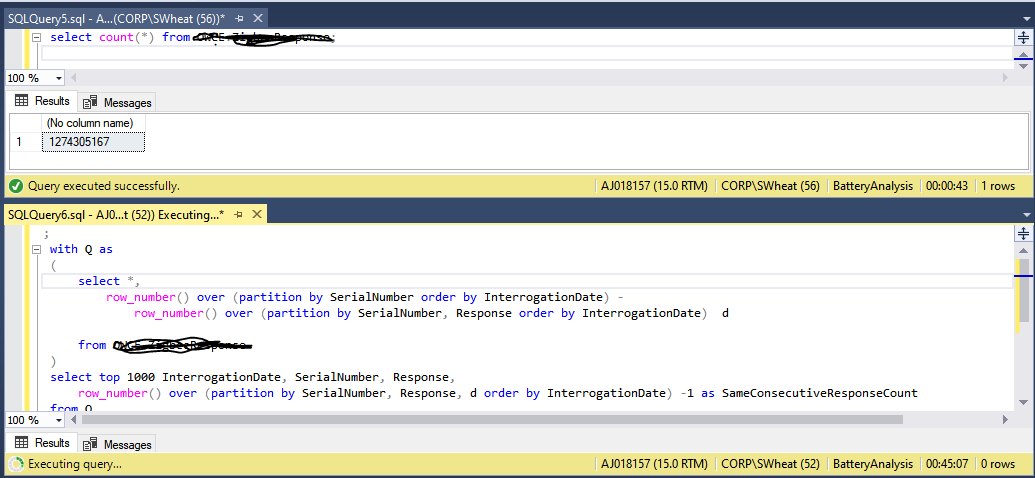
Check if this query works for your sample TableB:
;
with Q as
(
select *,
row_number() over (partition by SerialNumber order by InterrogationDate) -
row_number() over (partition by SerialNumber, Response order by InterrogationDate) d
from TableB
)
select InterrogationDate, SerialNumber, Response,
row_number() over (partition by SerialNumber, Response, d order by InterrogationDate) as SameConsecutiveResponseCount
from Q
order by SerialNumber, InterrogationDate
Hello, @Viorel , thank you for your answer. Yes, the query you provided does work on the sample data. Thanks very much.
Unfortunately, however the query runs slowly on our production data. The table is very large - 1.2 billion rows - so we need it to run as quickly as possible. I have let it run for over 45 mins and it does not return 1000 rows. Is there any chance a query like the one I provided can be made to work? InterrogationDate and SerialNumber are the composite PK and are indexed.
I am still very interested to know the answers to questions 2.) and 3.) that I posted.
Regards,
Sam
Probably the Response column must be included to indexed columns too. Perhaps the query needs specific indices. Maybe there are some alternative queries.
Regarding other questions, I am not sure if this Forum works well with multiple questions and answers.
To start somewhere: You should download and install CU14 which is the most recent Cumulative Update of SQL 2019 to get access to many bug fixes and improvements.
As for your question 2): The 2 is the same as the 2 just above. You are saying:
sum(case when Response = LastResponse then 1 else 0 end) over(partition by Response order by InterrogationDate)
At this point Response is 1 and LastResponse is 0, so the CASE expression returns 0 and adds nothing to the sum. So the 2, which is in the same partition group is left unchanged.
As for what happens in 3) I'm not sure that I want to go into. Your LAG has one PARTITION clause and the SUM has another, and, well, it obviously does not end well.
As for your actual problem, this one of these problems that are difficult to implement efficiently with a pure set-based solution. It's obvious that it can be done as a single pass over the data, but there is no way to express that efficiently. So, yes, it will have to be a loop. However, it does not have to be a loop one row at a time, but you can loop abreast. That is, I assume that you want this numbering for an individual SerialNumber, so you can handle multiple SerialNumber in parallel. With that brutal amount of data, you should probably take a couple at a time.
To give you some inspiration you can watch my lightning talk Looping Abreast.
Thank you @Erland Sommarskog for your answer.
I did create a new ticket in response to comment from@Viorel I will delete that one.
so the CASE expression returns 0 and adds nothing to the sum. So the 2, which is in the same partition group is left unchanged.
However, in the row above the response is zero (it changes) and the sum is reset which is the expected behavior.
Why is that behavior not applied to the row in question, where Response changes again? Namely, why is the sum not reset when the value in the Response column changes?