Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAK%3C/text%3E%3C/svg%3E)
So I followed the below steps and Now I am interested in knowing how we can ingest data.
I creates a Synapse Workspace and then in the Data Tab-->(+) --> (Lake Database) from the option and then created a Database and then selected the database and created a table in there with columns ID, Name and Class. The table is empty and it only has three column name.
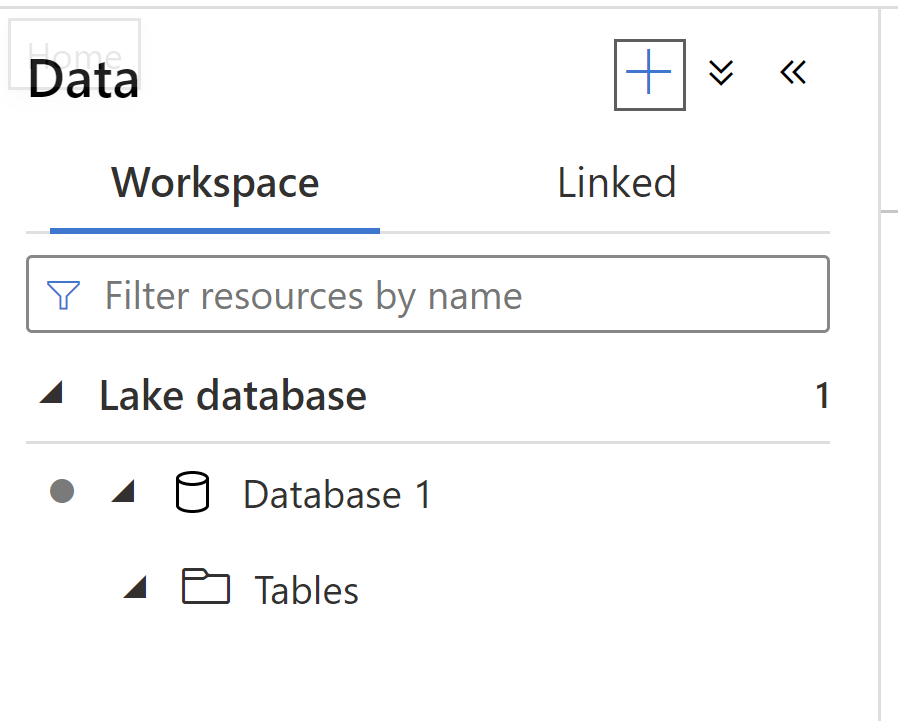
Now I selected the notebook and created a dataframe in pyspark where I have three columns (AssetID, AssetClass and Name) and have populated the data in this dataframe.
I would like to insert this data in my Lake Database which I created above where my AssetID goes in ID column, AssetClass goes in Class column and Name goes in Name column.
I am unable to find a way to do it in pyspark in Notebook. I am also unable to add the created Lake Database table in the Synapse pipeline for any activity. How do we access this created database and its table and populate it with data??
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @ankit kumar ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @ankit kumar ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @ankit kumar ,
Thanks for the ask and using Microsoft Q&A platform .
As I understand you have the below ask , let me know if thats not accurate .
Just to lewt you know thats Lake house is still unders "preview" and we are actively working on this at this time .
I was able to use the below prove of code snippet to insert data into the table .
%%sql
INSERT INTOdb2.table_1VALUES (1,'Product','Prodycclass');
INSERT INTOdb2.table_1VALUES (2,'Product2','Prodycclass2');%%pyspark
df = spark.sql("SELECT * FROMdb2.table_1")
df.show(10)
+---+--------+------------+
| ID| Name| Class|
+---+--------+------------+
| 2|Product2|Prodycclass2|
| 1| Product| Prodycclass|
+---+--------+------------+
Note : Once you crreate the lake database and table , make sure that you commits all the changes and publish the pass , once you do this then only its going to be discovered by the sparl clusters .
To view this db/table from the pipeline , please create a linked servive for Synapse and select the manual option and pass the url of the serverless instance and other details .
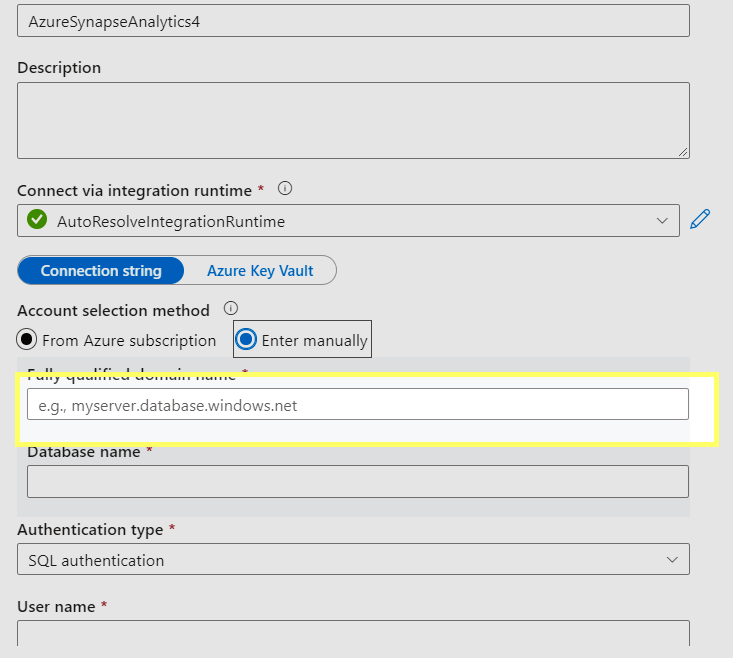
Please do let me if you have any queries .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how