Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ELC%3C/text%3E%3C/svg%3E)
I have a database in Azure synapse with only one column with datatype datetime2(7). In Azure Databricks I have a table with the following schema.
df.schema
StructType(List(StructField(dates_tst,TimestampType,true)))
The table is empty and allows null values
When I try to write this dataframe
+-----------------------+
| from |
+-----------------------+
|2019-07-24 20:50:08.667|
|2022-01-24 15:33:22.193|
+-----------------------+
I get this error message:
Py4JJavaError: An error occurred while calling o535.save.: org.apache.spark.SparkException: Job aborted due to stage failure: Task 3 in stage 15.0 failed 4 times, most recent failure: Lost task 3.3 in stage 15.0 (TID 46) (10.139.64.5 executor 0): com.microsoft.sqlserver.jdbc.SQLServerException: 110802;An internal DMS error occurred that caused this operation to fail SqlNativeBufferBufferBulkCopy.WriteTdsDataToServer, error in OdbcDone: SqlState: 42000, NativeError: 4816, 'Error calling: bcp_done(this->GetHdbc()) | SQL Error Info: SrvrMsgState: 1, SrvrSeverity: 16, Error <1>: ErrorMsg: [Microsoft][ODBC Driver 17 for SQL Server][SQL Server]Invalid column type from bcp client for colid 1. | Error calling: pConn->Done() | state: FFFF, number: 75205, active connections: 35', Connection String: Driver={pdwodbc17e};app=TypeD00-DmsNativeWriter:DB2\mpdwsvc (56768)-ODBC;autotranslate=no;trusted_connection=yes;server=\\.\pipe\DB.2-e2f5d1c1f0ba-0\sql\query;database=Distribution_24
Runtime version 9.1 LTS (includes Apache Spark 3.1.2, Scala 2.12)
This only happens with these data types (timestamp and date), with other types like int, string this problem does not happen
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @Luis Cespedes ,
Thanks for the ask and using Microsoft Q&A platform .
As we understand the ask here is to insert timestamp data in Azure synapse analytics . Please do let me know if that not accurate.
I did tried out the below code on databricks and I was able to insert the records in SQLDW .
from pyspark.sql import functions as F
dict = [{'name': 'Alice', 'age': 1},{'name': 'Again', 'age': 2}]
df3 = spark.createDataFrame(dict)
df3=df3.withColumn('Age', F.current_timestamp())
df3.show()
tableName = 'SomeTableName'
df3.write.mode("overwrite") \
.format("com.databricks.spark.sqldw") \
.option("url", sqlDwUrl) \
.option("tempDir", tempDir) \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", tableName) \
.save()
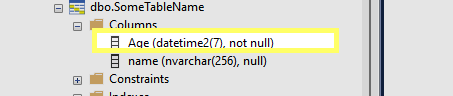
df3.schema
Out[73]: StructType(List(StructField(Age,TimestampType,false),StructField(name,StringType,true)))
On the SQLDW side this is what I see
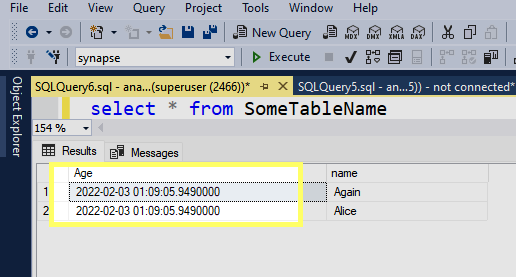
I am unable to repro this . Let me know if you see something which in diffferent in my case , I will try my best to rero this .
One an other note can you please try to cast the timestamp in this format "yyyy-MM-dd HH:mm:ss" and try to insert the data .
Please do let me if you have any queries .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
thank you for your reply I tried this code
from pyspark.sql import *
from pyspark.sql.functions import *
from pyspark.sql import functions as F
dict = [{'v-from': '2019-07-24 20:50:03.003'},{'v-from': '2022-01-22 17:07:53.007'}]
df3 = spark.createDataFrame(dict)
df3=df3.withColumn('v-from', col('v-from').cast('timestamp'))
df3.show(truncate = False)
+-----------------------+
|v-from |
+-----------------------+
|2019-07-24 20:50:03.003|
|2022-01-22 17:07:53.007|
+-----------------------+
And to save the data into synapse table
df3.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", jdb)\
.option("dbtable", "date_test") \
.option("user", username) \
.option("encrypt", "true") \
.option("hostNameInCertificate", "*.database.windows.net") \
.option("password", pass) \
.option("mssqlIsolationLevel", "READ_UNCOMMITTED") \
.option("maxStrLength", "4000" ) \
.option("schemaCheckEnabled", False) \
.save()
The table only has 1 column (v-from)
datetime2(7), null
I also tried changing the data type of the table to datetime, but the same error happens.
As far as I can see, it is probably the write configuration.
@HimanshuSinha-msft
I don't know why I can't edit previous comment, but I wanted to add that the dataframe schema is
StructType(List(StructField(v-from,TimestampType,true)))
Hello @Luis Cespedes ,
I see that you are using the Sql server driver , but the title says that the your sink is Synapse .
.format("com.microsoft.sqlserver.jdbc.spark") \
As called out here , we should use the below driver . Can you please try this out and let me know ?
.format("com.databricks.spark.sqldw") \
Please do let me if you have any queries .
Thanks
Himanshu
·
Hello @Luis Cespedes ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @Luis Cespedes ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others .
If you have any question relating to the current thread, please do let us know and we will try out best to help you.
In case if you have any other question on a different issue, we request you to open a new thread .
Thanks
Himanshu
Hi @HimanshuSinha-msft
the problems were the format and also the credentials, which apparently were not the correct ones, after obtaining the correct ones it was solved, thanks for your recommendations.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ER%3C/text%3E%3C/svg%3E)
I am facing the same issue.
Unable to load timestamp spark dataframe into synapse sql database.
Can You please let me know how was the issue fixed.
Driver used : (com.microsoft.sqlserver.jdbc.spark")
Thanks in Advance
Hi @Ramya ,
I'm not sure what was the solution, but what I did is first, use .format("com.databricks.spark.sqldw"), then use the correct keyvault (scope) and keys, I asked to change to new ones, so I think that I was using the wrong ones or were created wrong.
I hope it helps you