Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEV%3C/text%3E%3C/svg%3E)
I am developing a dataflow in Synapse Analitycs and when I am running the pipeline I get the following error.
The strange thing about everything, is that I make another pipeline, but no longer with a dataflow, if not, only with a copy activity and it executed well, in other words it is not the data.
I hope you can help me with this mistake.
at Source 'source': org.apache.spark.SparkException: Job aborted due to stage failure: Task 3 in stage 15.0 failed 1 times, most recent failure: Lost task 3.0 in stage 15.0 (TID 35, vm-85b29723, executor 1): java.nio.charset.MalformedInputException: Input length = 1
at java.nio.charset.CoderResult.throwException(CoderResult.java:281)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:339)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
at com.fasterxml.jackson.core.json.ReaderBasedJsonParser.loadMore(ReaderBasedJsonParser.java:153)
at com.fasterxml.jackson.core.json.ReaderBasedJsonParser._skipWSOrEnd(ReaderBasedJsonParser.java:2017)
at com.fasterxml.jackson.core.json.ReaderBasedJsonParser.nextToken(ReaderBasedJsonParser.java:577)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1$$anonfun$apply$3.apply(JsonInferSchema.scala:56)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1$$anonfun$apply$3.apply(JsonInferSchema.scala:55)
at org.apache.spark.util.Utils$.tryWithResource(Utils.scala:2568)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1.apply(JsonInferSchema.scala:55)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1$$anonfun$apply$1.apply(JsonInferSchema.scala:53)
at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435)
at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceLeft(TraversableOnce.scala:185)
at scala.collection.AbstractIterator.reduceLeft(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceLeftOption(TraversableOnce.scala:203)
at scala.collection.AbstractIterator.reduceLeftOption(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceOption(TraversableOnce.scala:210)
at scala.collection.AbstractIterator.reduceOption(Iterator.scala:1334)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1.apply(JsonInferSchema.scala:70)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$$anonfun$1.apply(JsonInferSchema.scala:50)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.RDD$$anonfun$mapPartitions$1$$anonfun$apply$23.apply(RDD.scala:823)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:310)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$12.apply(Executor.scala:414)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:420)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
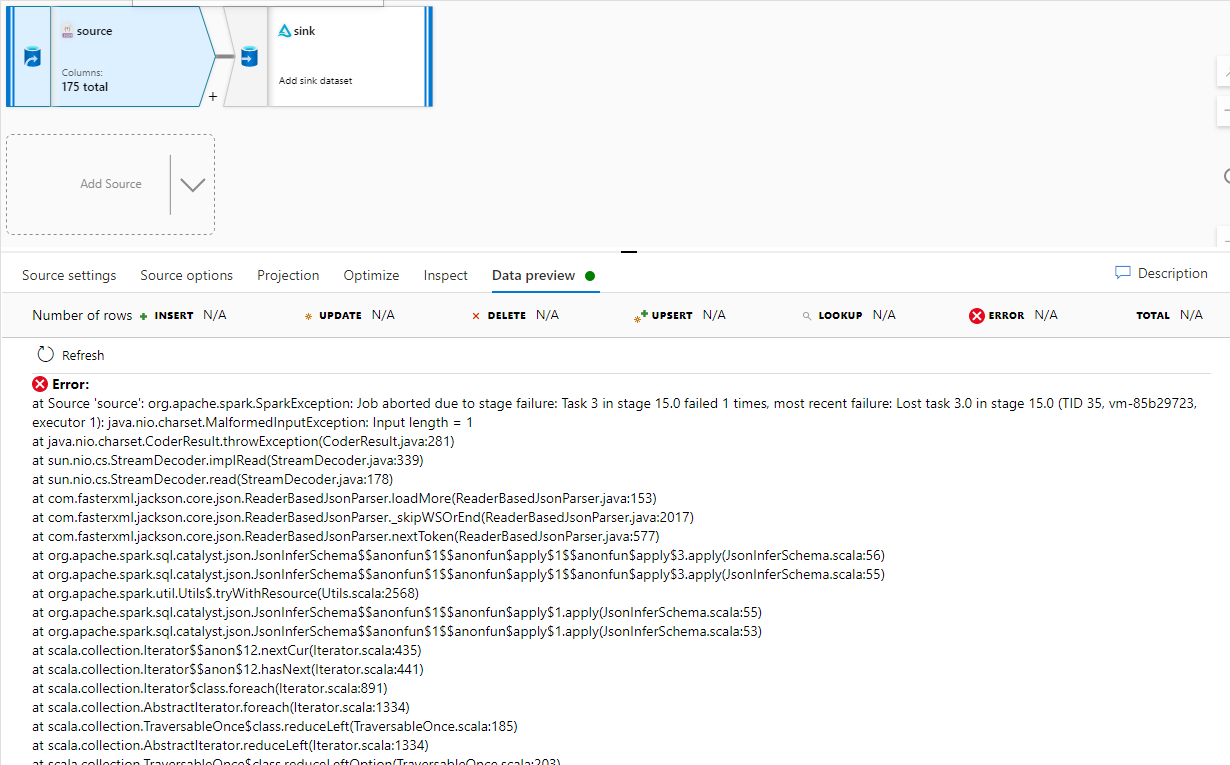
Adding the snapshot.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hello @Anonymous ,
Thanks for the question and using MS Q&A platform.
My understanding is that you are receiving the above error while trying data preview a JSON file as source in Mapping Data flow. But when you tried the same source in Copy activity then there no issue, which confirm you that there is nothing wrong with data. Please correct if I misunderstood the ask.
If the above understanding is correct then, it seems like there is something wrong with your source settings configuration in Mapping data flow source.
We recommend to please make sure the JSON Settings under Source Options tab are correctly configured.
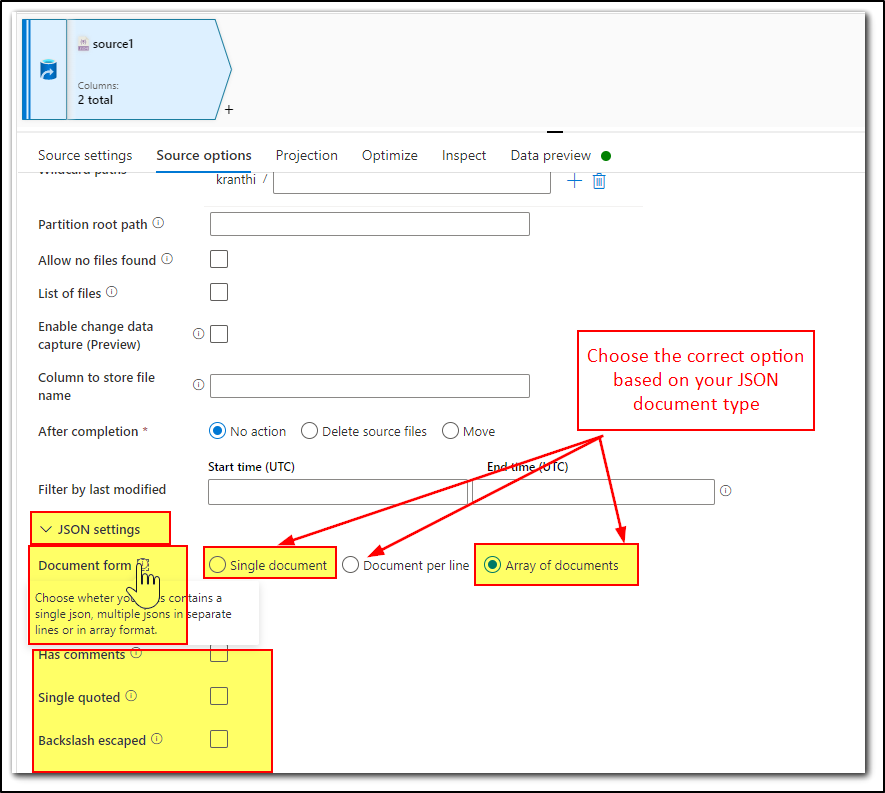
Before previewing the data, please correctly configure the JSON settings under Source Options tab and then under Projection tab check if you are able to see the schema if not try Reset Schema or Import projection. And then try to preview the data.
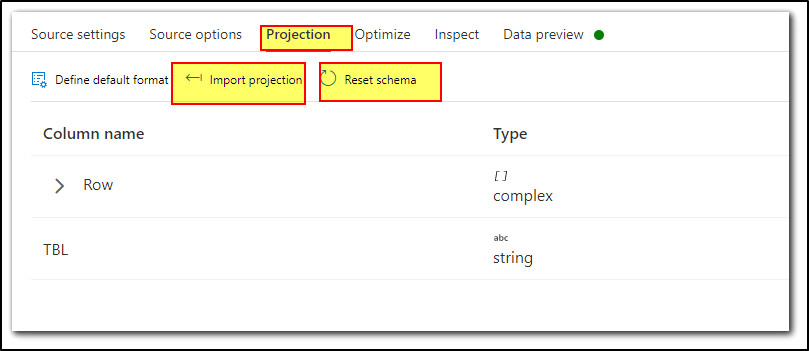
I tried to reproduce the issue but no luck. In case if the above steps didn't help to resolve your issue, we request you to please share a sample JSON file (Please note: save the JSON file as TXT extension to attach here) attached in your response along with screenshots of your Source settings, Source options (exand JSON settings), Projection, Inspect tab settings which would help us to reproduce the issue on our end.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello good morning,
In this case the json document is a document per line, however in Source Option I configured it as if it were an array and in this case if it made methe projection and preview of the data, but it only showed me one line. If I change it to one document per line, the preview of the data does not work for me.
The strange thing is that with a smaller file it does work, but with this one it is the same, but bigger it does not.171983-file.txt
Apparently I can't share the original file, as it's too big, please duplicate it on your part, so that it has a scenario like mine.
Hello @Anonymous ,
Thanks for the getting back to me and sharing a sample file. I did download your file and tried to do a data preview in Source of Mapping data flow and seems like everything is working fine for me. I wasn't able to reproduce the error you are seeing. I believe there might be something wrong your source settings in Mapping data flow which is causing this error. Could you please compare with my settings shown in below GIF and see if that helps?
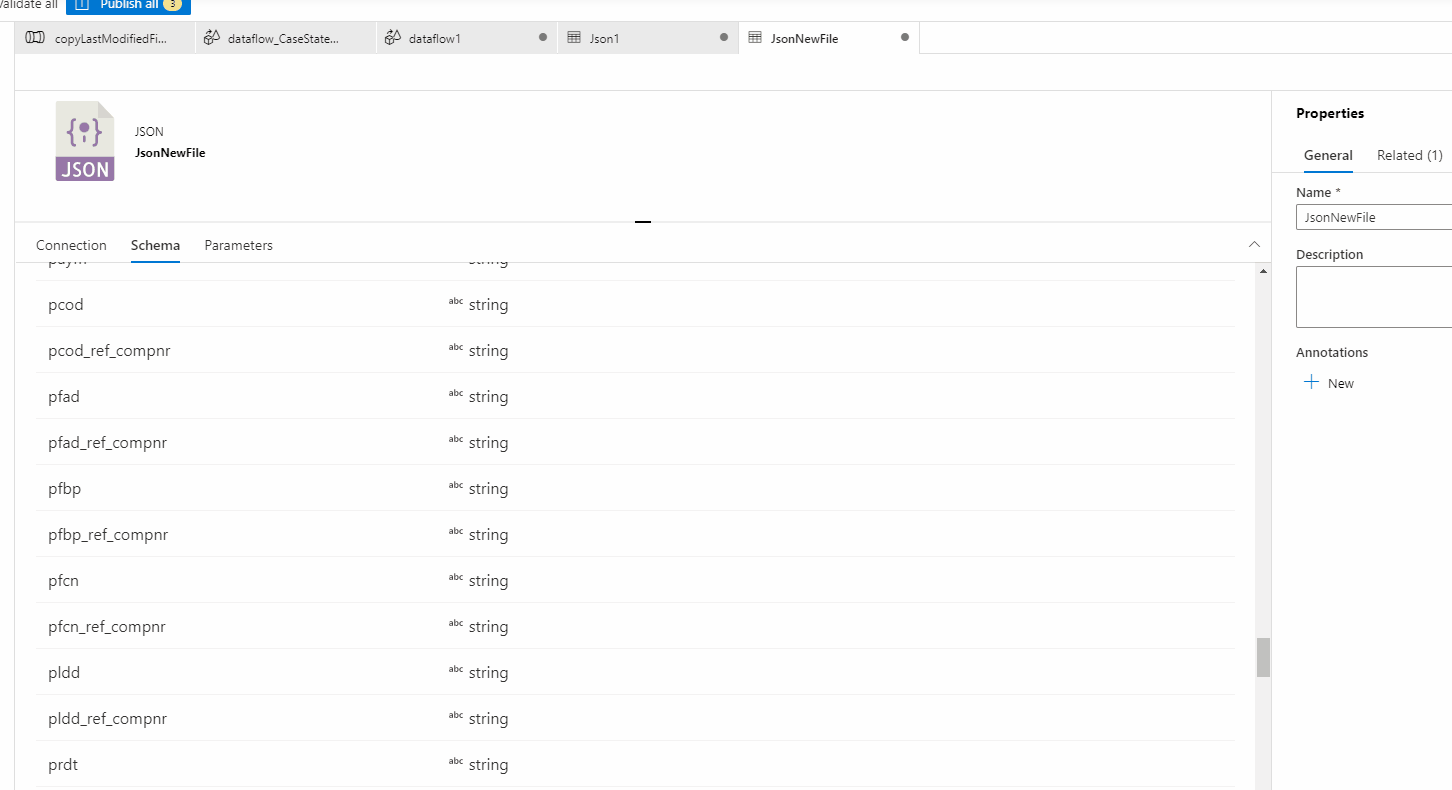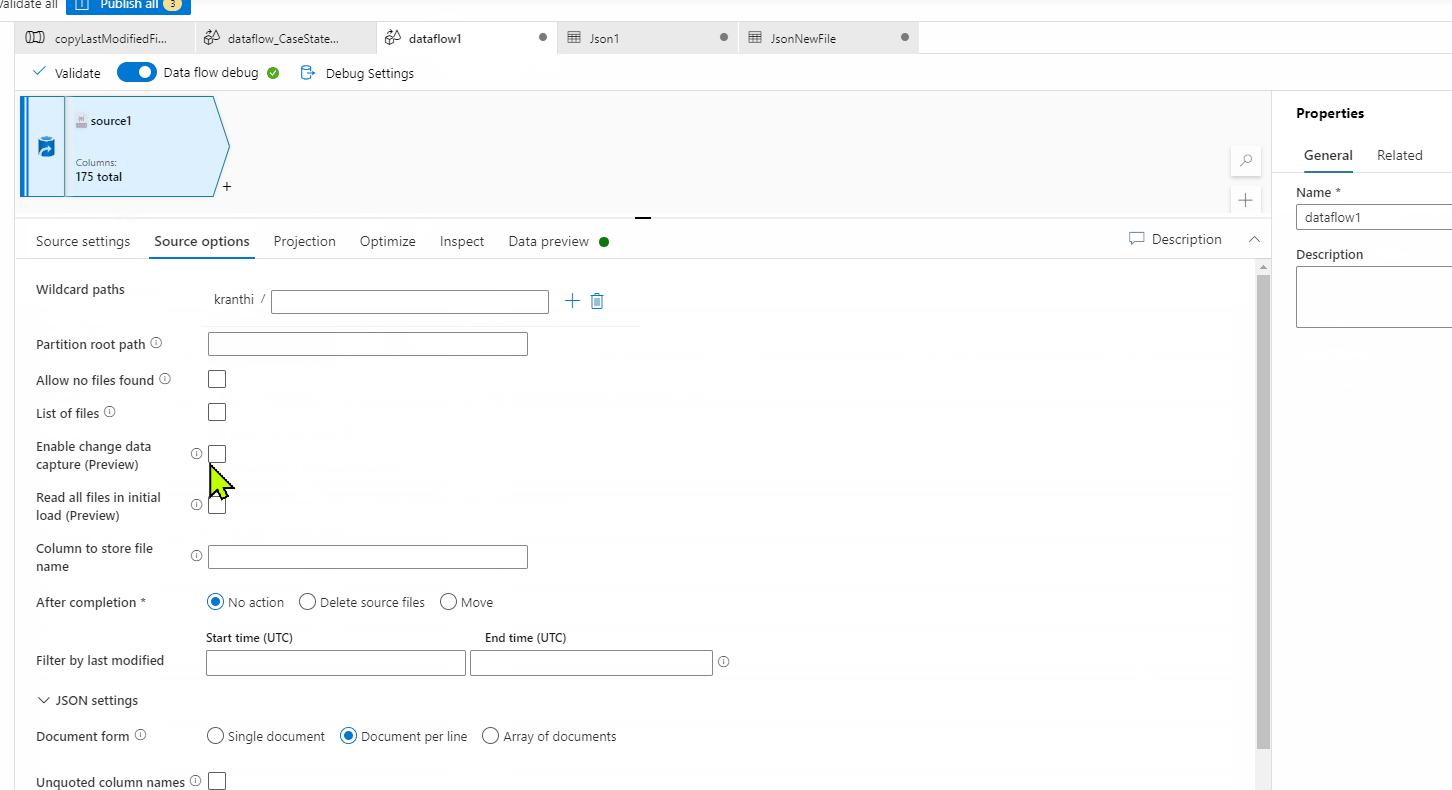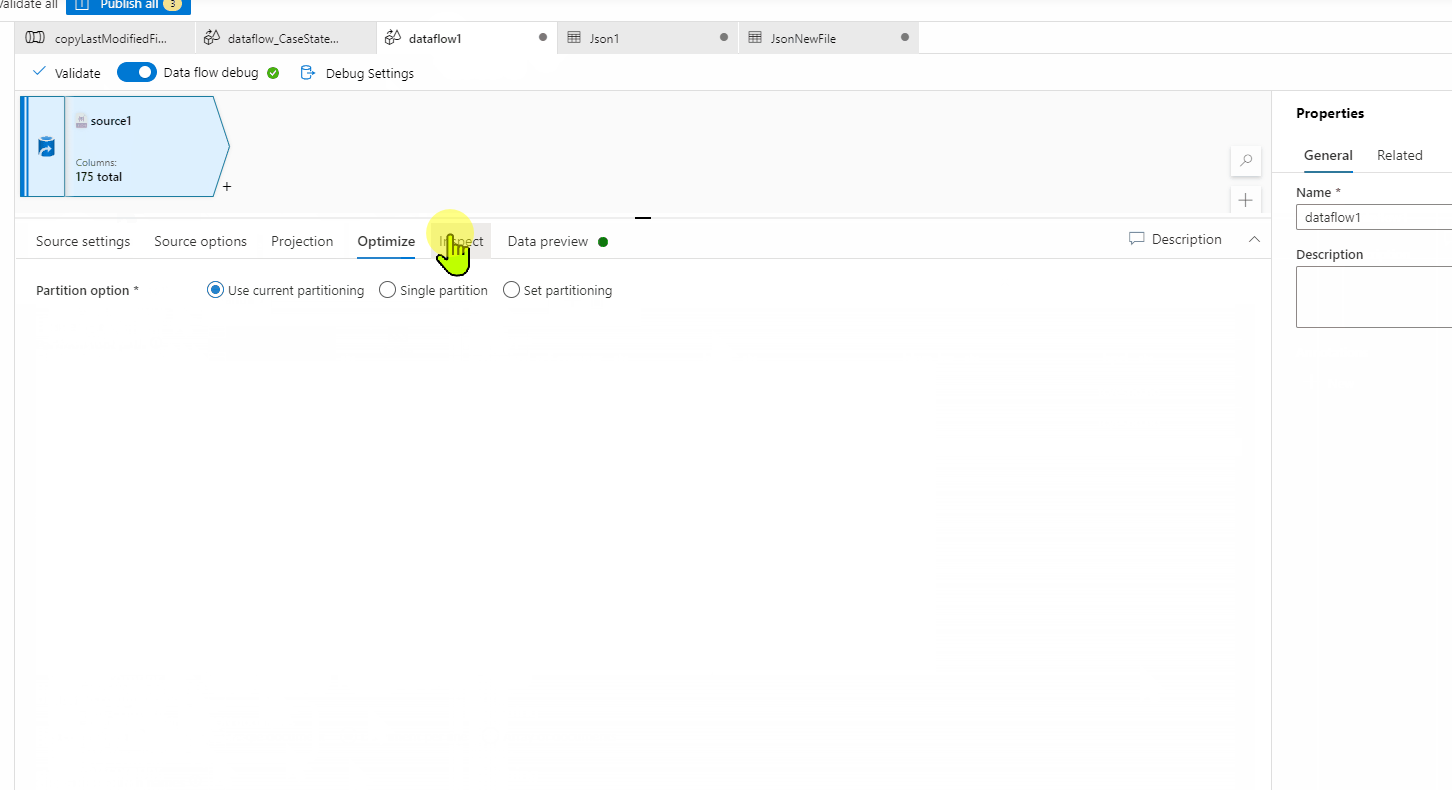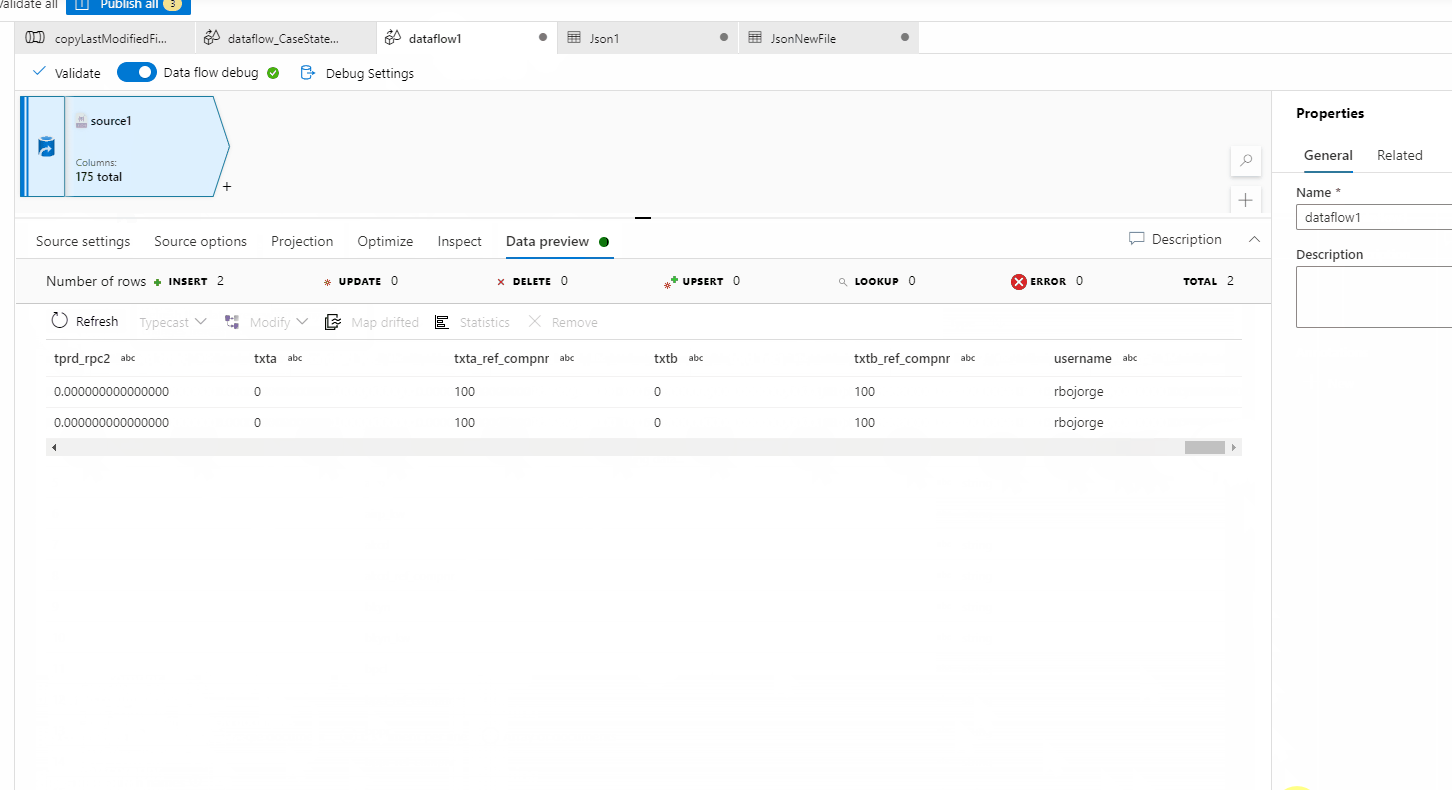
In case you still have the issue, I would recommend recreating the dataset and try to see if that helps to resolve the issue. Else you will have to open a support ticket for deeper investigation.
Do let us know how it goes.
Thank you
----------
Please do consider clicking on "Accept Answer" and "Upvote" on the post that helps you, as it can be beneficial to other community members.
Hello there,
We still have not heard back from you. Just wanted to check if the above suggestion was helpful? If it answers your query, please do click Accept Answer and/or Up-Vote, as it might be beneficial to other community members reading this thread. And, if you have any further query do let us know.