Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,696 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETC%3C/text%3E%3C/svg%3E)
Hello everyone! I'm facing a problem while loading a parquet file(171118-salesparquet.txt rename removing txt externsion) in an external table in a Synapse serveless instance. In the file there's a column formatted as a datetime(Saledate). If I try to load it in an external table the datetime is always seen as a bigint and there's no way to cast it otherwise.
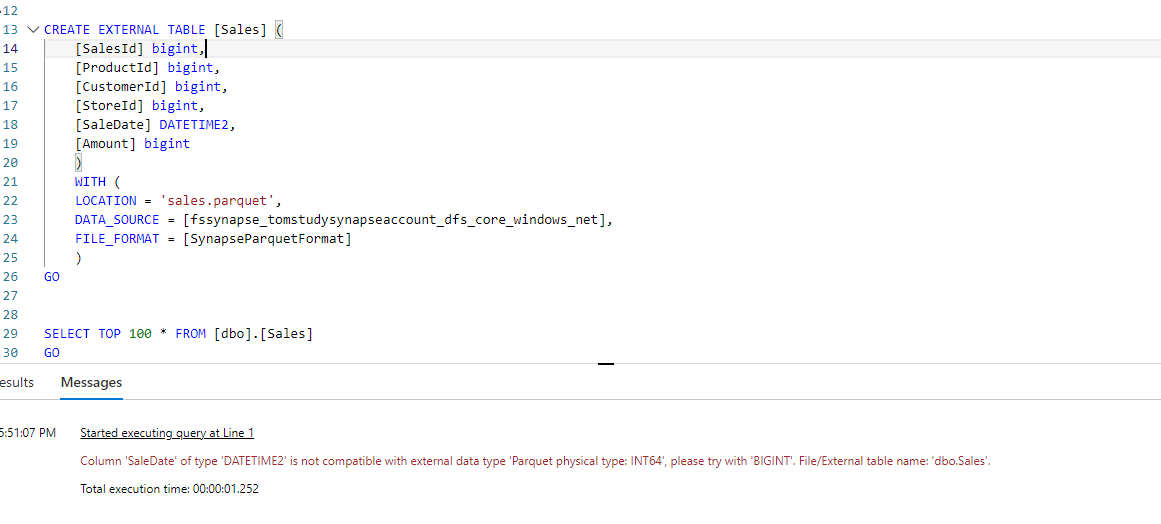
If I try to look at the data using CETA the column id recognized as int:
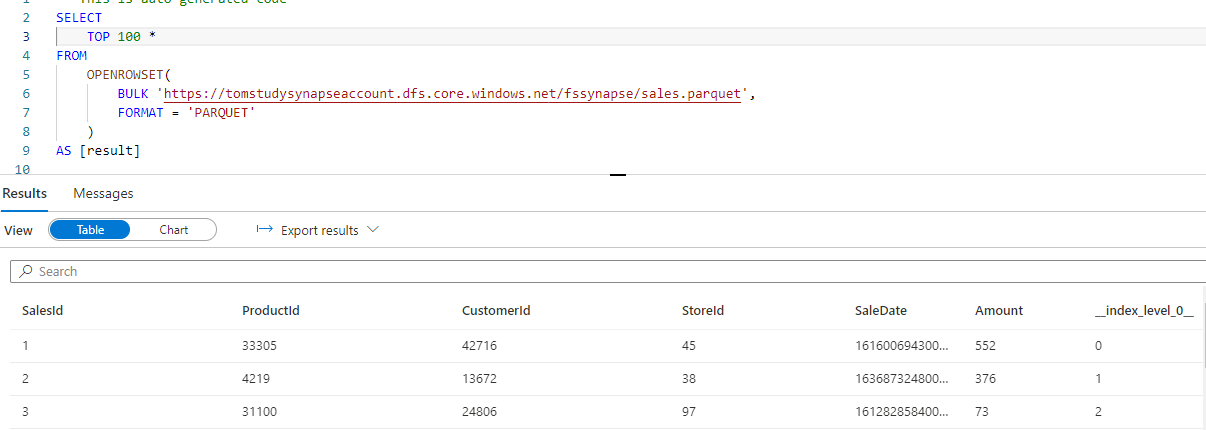
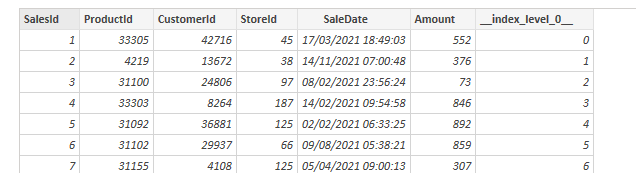
To check things out I tried to open the same file with Power Query in Power BI and the columns is correctly recognized as a datetime:
Do you have any advice/tip/solution for this?

Hi @Tommaso Capelli ,
Thanks for sharing the mitigation step taken by you in order to resolve the query. If the suggested response helped you, please click Accept Answer as accepted answers help the community as well.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3E3%3C/text%3E%3C/svg%3E)
i am also facing same issue please anyone have solution for this?
Hi @Tommaso Capelli ,
Welcome to Microsoft Q&A platform and thanks for posting your query. Apologies for delay in response.
As I understand your requirement , Currently you have dates that appear to be not valid datetime2 values in the parquet and it is stopping the querying of the file.
It might be different version of parquet read using to read parquet file. Say, you use spark 2.4 to write the file, it will use Julian calendar. However, when serverless reads it, it will use Gregorian calendar which causes the problem.
One possible solution in Synapse architecture might be,
Doc reference that can be considered:
Column is not compatible with external data type
Inserting value to batch for column type DATETIME2 failed
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
HI,
As you can see my metadata for booked_order shows as int64 which i cant convert to date in select statement

Thank you Annu for your support. right now I'm not able to work with dedicated spark pools, I can only work with serverless, so my guess is that I have to wait for new releases in Synapse serverless that fixes this issue, meanwhile I've already found a workaround (format as string in parquet and parse it to a datetime in Synpase).
Hi @Tommaso Capelli ,
Thanks for sharing the mitigation step taken by you in order to resolve the query. If the suggested response helped you, please click Accept Answer as accepted answers help the community as well.
Hi @39457273 ,
We recommend you to create a separate thread in Microsoft Q&A platform as the information provided by you is not sufficient enough to provide the answer. Image is not visible even if it looks you have tried attaching it.
Hi @Tommaso Capelli ,
Just following up to see if the suggested response helped you, please click Accept Answer as accepted answers help the community as well.