Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,627 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKV%3C/text%3E%3C/svg%3E)
Hi team
Dataflow : purpose converting Json into CSV flattern and push to data lake gen2 from jsoin filke whicj is there in datalake gen 2
when i tested in dev dataflow working fine, but unable to move in prod and test with json code movement since my adf dont have git.
i have tested dataflow in dev its working properly. i have recreated dataset for source and sink in prod and copy paste json code, after that i am getting error as shown in attachment. how can i solve as early as possible.
for dev i can preview data as well for sake of u r undestanding i have attached a screenshort.

kindly help to fix as soon as posible. its impacting huge.

In the first screenshot, error says that you have used Self hosted IR in linked services. Is that the case? Did you create these linked services by copying the JSON code from Dev Linked service? Can you paste the Json code behind both the linked services?
I guess, you need to remove the self hosted IR and use Azure IR instead, and test the linked service connection.
Hi anonymous userChaudhari
i have created self hosted in dev and i have used same in dev for getting flattern.
can u tell me why it worked in dev why not in prod not allowing me with same self hosted
In Dev ADF, Can you cross check carefully the Linked service that is being used has the self hosted IR?
Optionally to get unblocked, you can try using Azure IR in Prod ADF and see if linked service connection is successful and dataset returns the data as expected
Also, can you clarify why self hosted IR is created and being used to connect to ADLS Gen2 via Linked service?
self hosted used for adls for sake of increase computation
in dev self ir only used and its worked.
i am checking with auto ir in prod and tested its tests connection is succeeded. i need to validate fo rdata.
can u confirm is there anay issues will come in prod if i use auto in future .
There won't be any issue if you use Azure IR to connect to ADLS Gen2.
In fact, documentation & the below thread says - in data flow, Self hosted IR can't be used when LS is using it
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
Hello @Karnati,Venkata Suchendra Reddy,IN-Bangalore ,
Thanks for the question and using MS Q&A platform.
My understanding is that you are receiving above validation errors, while using SHIR in your Mapping Data flow dataset linked service. Please correct if I'm wrong.
As called out by anonymous userChaudhari , currently Self Hosted Integration runtime is not supported in Mapping Data flows which is why you are receiving errors mentioned in your post.
To overcome this issue, you will need to replace the SHIR with Azure IR in your mapping data flows.
The strange thing I would like to reconfirm is, in your DEV Datafactory -
The reason would like clarification on this is because the public documentation clearly states that Data Flow activities are executed on their associated Azure integration runtime. The Spark compute utilized by Data Flows are determined by the data flow properties in your Azure IR and are fully managed by the service.

As called out by Vaibhav, the Integration Runtime documentation also calls out the same:
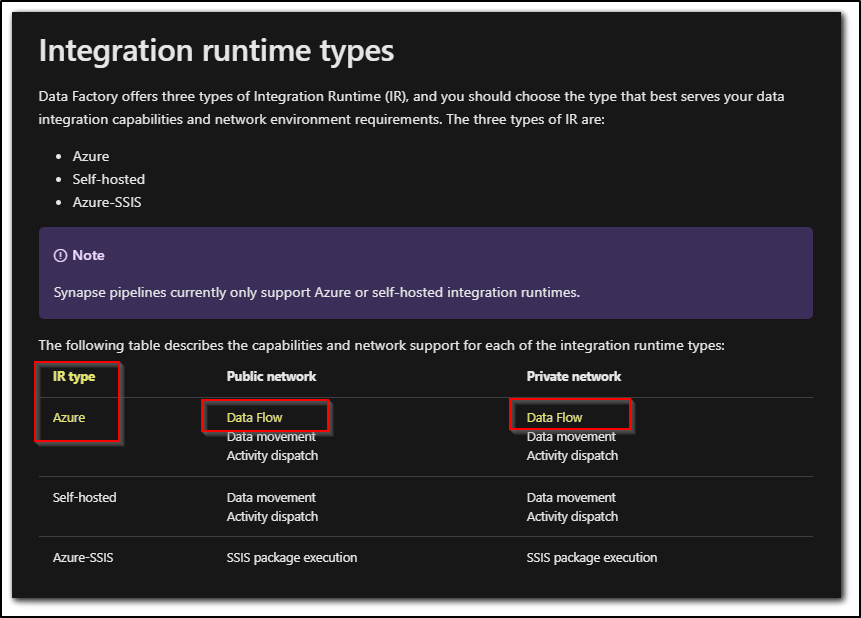
But to unblock, you will have to use Azure IR and there should be any issue in using Azure IR as it is the recommended IR to be used with Mapping data flows.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how