Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,338 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAA%3C/text%3E%3C/svg%3E)
The same code runs without any error in synapse analytics. I am not able to figure out what is causing the issue in VS code. Below is the error
Py4JJavaError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_18388\3630326346.py in <module>
6 .getOrCreate()
7
----> 8 df = spark.read.format("parquet").load("abfss://{v_containerName}@{v_accountName}.dfs.core.windows.net/<Path to parquet file>)
9 df.printSchema()
C:\bin\spark-3.0.1-bin-hadoop2.7\python\pyspark\sql\readwriter.py in load(self, path, format, schema, **options)
176 self.options(**options)
177 if isinstance(path, basestring):
--> 178 return self._df(self._jreader.load(path))
179 elif path is not None:
180 if type(path) != list:
C:\bin\spark-3.0.1-bin-hadoop2.7\python\lib\py4j-0.10.9-src.zip\py4j\java_gateway.py in call(self, *args)
1303 answer = self.gateway_client.send_command(command)
1304 return_value = get_return_value(
-> 1305 answer, self.gateway_client, self.target_id, self.name)
1306
1307 for temp_arg in temp_args:
C:\bin\spark-3.0.1-bin-hadoop2.7\python\pyspark\sql\utils.py in deco(*a, **kw)
126 def deco(*a, **kw):
127 try:
--> 128 return f(*a, **kw)
129 except py4j.protocol.Py4JJavaError as e:
130 converted = convert_exception(e.java_exception)
C:\bin\spark-3.0.1-bin-hadoop2.7\python\lib\py4j-0.10.9-src.zip\py4j\protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling o32.load.
: java.io.IOException: No FileSystem for scheme: abfss
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2660)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2667)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:94)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2703)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2685)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:373)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:295)
at org.apache.spark.sql.execution.streaming.FileStreamSink$.hasMetadata(FileStreamSink.scala:46)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:366)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:297)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$2(DataFrameReader.scala:286)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:286)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:232)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Unknown Source)
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAC%3C/text%3E%3C/svg%3E)
@Anushree Agarwal Did you got the answer, actually I am also trying to run azure spark setup locally and not able to succeed for same. Let me know if you are able to run it locally need some guidance for same. Please connect on amish.choudhary@Microsoft Corporation .in
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Anushree Agarwal ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is to either troubleshoot your line of code or explain why it might work in Synapse but not locally .
The line in question being:
df = spark.read.format("parquet").load("abfss://{v_containerName}@{v_accountName}.dfs.core.windows.net/<Path to parquet file>)
There are several things of note here. First in terms of possible typos or substitutions. I see you have put {curly braces} around v_containerName and v_accountName. I assume this is for either substituting or redacting, and you have things proper on your end. You also have <Path to parquet file> . This one is different, and looks like it might have been copied from some other place. Since it is done differently, I suspect it is an error, and you forgot to replace it.
Second point of note, I do not see any place where you are providing credentials or authentication. Unless your Data Lake Gen2 container has been set to public access, some form of authentication is required. In Synapse, credential passthrough is built in, and leverages Azure Active Directory to do the credential stuff in the background so you don't have to explicitly code it in. This feature is not available when you run on your local machine because your machine isn't part of Azure Active Directory.
Third point, the error message includes
java.io.IOException: No FileSystem for scheme: abfss
This is saying your machine doesn't know what to do with abfss. You will need to install drivers at a minimum. Python is not Pyspark.
Please do let me if you have any queries.
Thanks
Martin
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hi Martin,
Thanks for your answer. However the first point that you mentioned for path is already taken care of in the code that I am using. I had replaced the path in my question due to data confidentiality. As I had mentioned earlier, the code worked fine in synapse notebook.
For the second point, I did not have the credentials in the code so I have added it now but the code is still not working in VS code
I also have spark and python installed on my system. My JAVA_HOME variable is set to 'C:\Program Files\Java\jre1.8.0_211', however I donot have JDK on my system, Do I need to install any other driver for the below code to run?
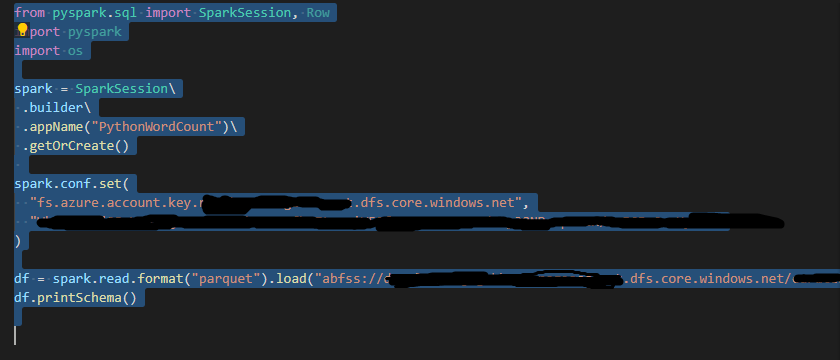
I have used the below link to configure notebook in VS Code-
https://learn.microsoft.com/en-us/azure/synapse-analytics/spark/vscode-tool-synapse
I am able to run the code in VSCode that is given in the above link. However the code fails with Py4JJavaError when it is trying to read the file in azure datalake gen2 storage

Hi Martin,
Thanks for your answer. However the first point that you mentioned for path is already taken care of in the code that I am using. I had replaced the path in my question due to data confidentiality. As I had mentioned earlier, the code worked fine in synapse notebook.
For the second point, I did not have the credentials in the code so I have added it now but the code is still not working in VS code
I also have spark and python installed on my system. My JAVA_HOME variable is set to 'C:\Program Files\Java\jre1.8.0_211', however I do not have JDK on my system, Do I need to install any other driver for the below code to run?
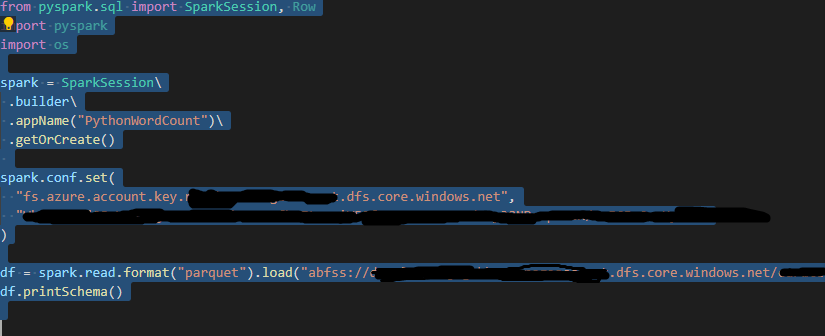
Hi, could you please let me know if you have the solution to the issue I have raised.
@Anushree Agarwal Did you got the answer, actually I am also trying to run azure spark setup locally and not able to succeed for same. Let me know if you are able to run it locally need some guidance for same. Please connect on amish.choudhary@Microsoft Corporation .in