Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,623 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
field1 field2 field3
name1 surname1 address1
name1 surename1 address1
name1 surename1 address1
name2 surename2 address2
name2 surename2 address2
name2 surename2 address2
...
In my select activity, it returns in data preview several fields.
There are duplicates and I would like to return distict rows.
After the select activity I have placed an aggregate activity.
Inside this aggregate activity the screenshot below
How is this done please?

Hi @arkiboys ,
The screenshot you are mentioning about is not visible. Could you please try resharing the same. Have you tried using collect function inside aggregate transformation to achieve the above requirement - eg. Field1= collect(field1) , Field2= collect(field2) , Field3= collect(field3)
Hi,
The below settings seem to be giving me what I want which is to do select distinct
in group by I place all fields
In aggregates section I am using column pattern like below:
each column that matches: name == 'field1' && name == 'field2', etc
first box: $$ second box: first($$)
Question:
Where do I put your collect(field) suggestion?
Thanks
Hi @arkiboys ,
Thankyou for using Microsoft Q&A platform and posting your query.
As I understand your query, you want to remove duplicate in your data. Your approach of trying aggregate with column pattern seems correct but before that try adding Rank Transformation with Dense option enabled to generate Id based on the field values.
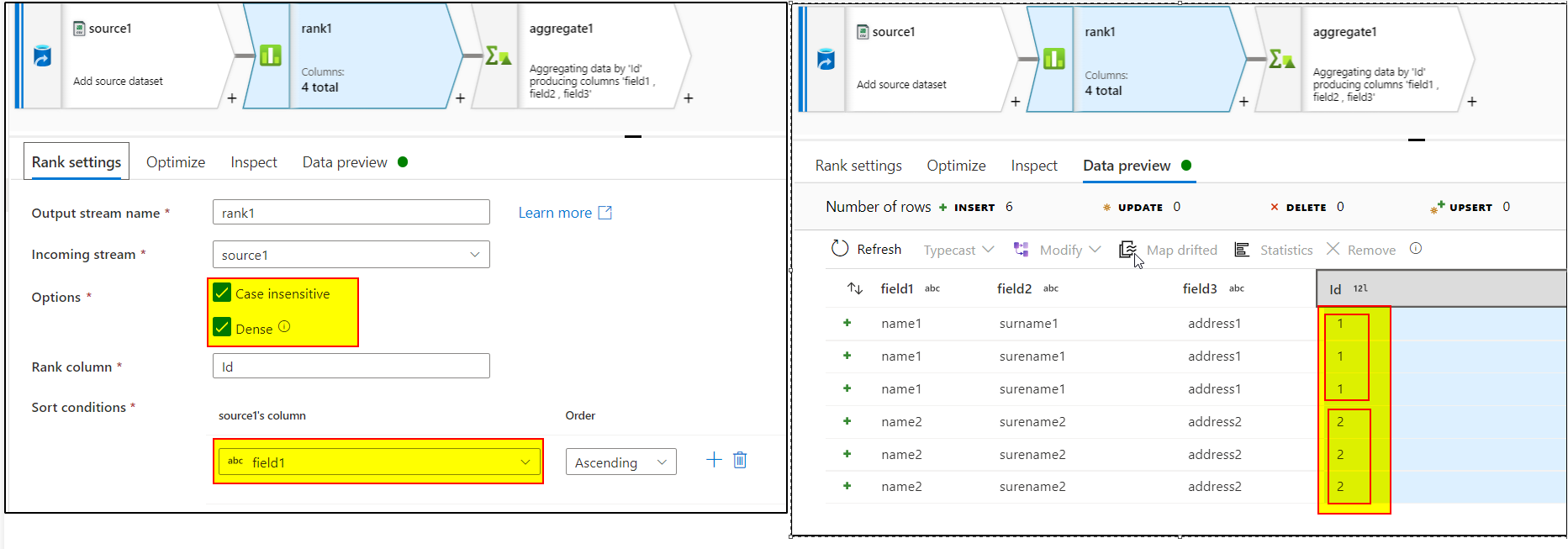
Based on this id , we can group by in group by settings of aggregate transformation. In aggregate settings, we can use column pattern with condition as : name !='Id' . Use Column name expression as : $$ and value expression as : first($$)
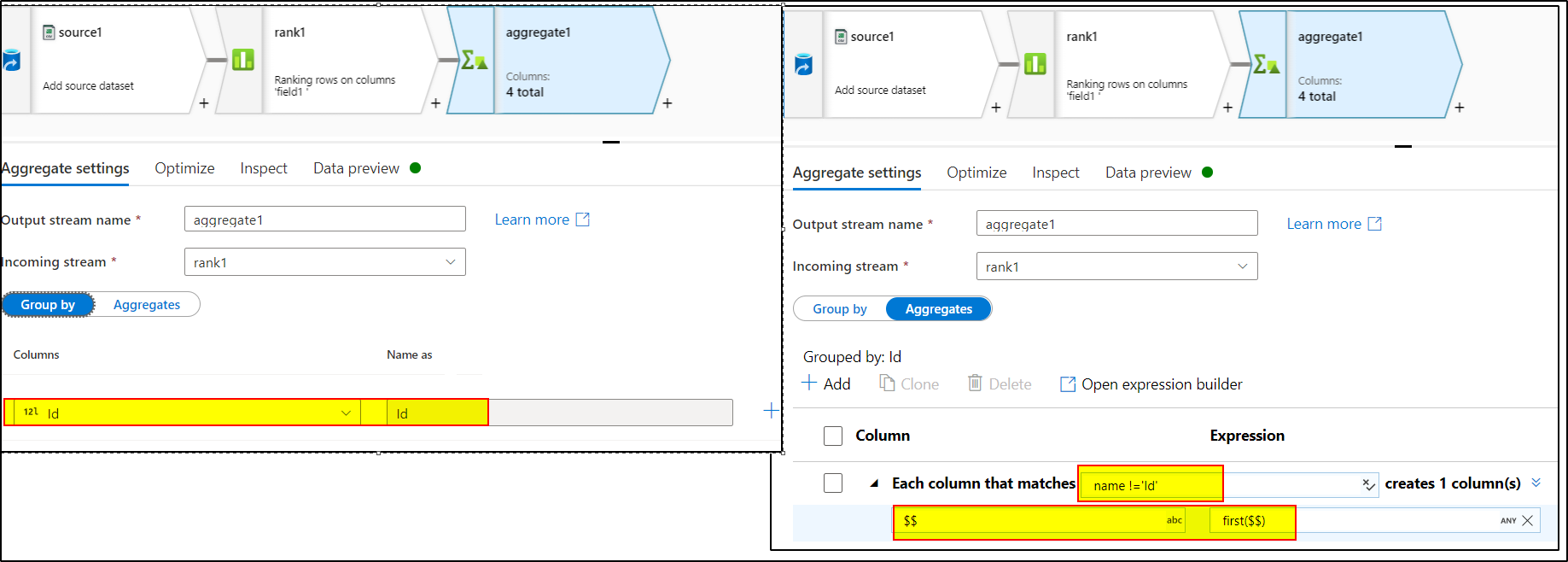
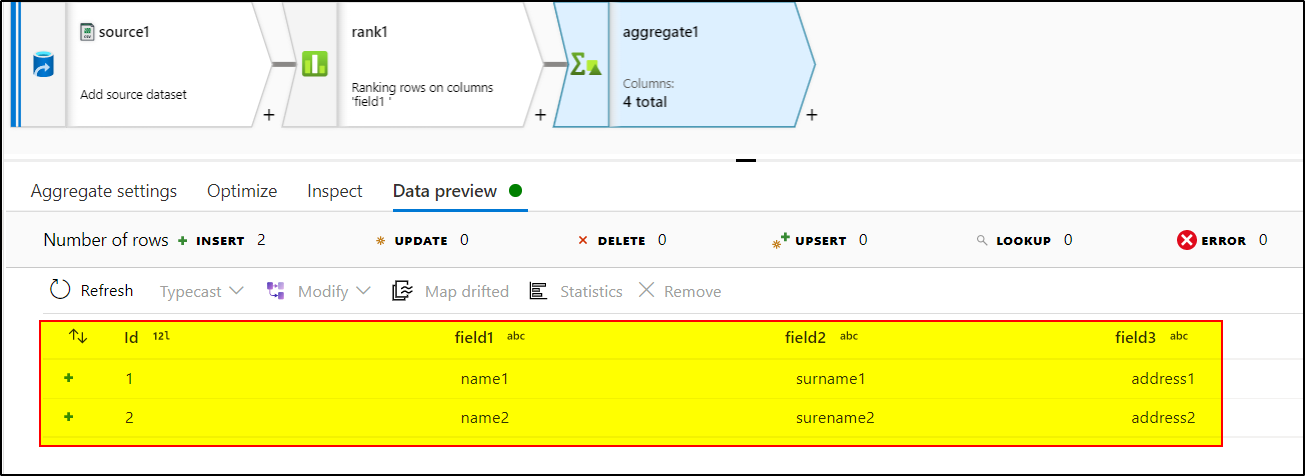
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.