Azure Machine Learning
An Azure machine learning service for building and deploying models.
3,334 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBT%3C/text%3E%3C/svg%3E)
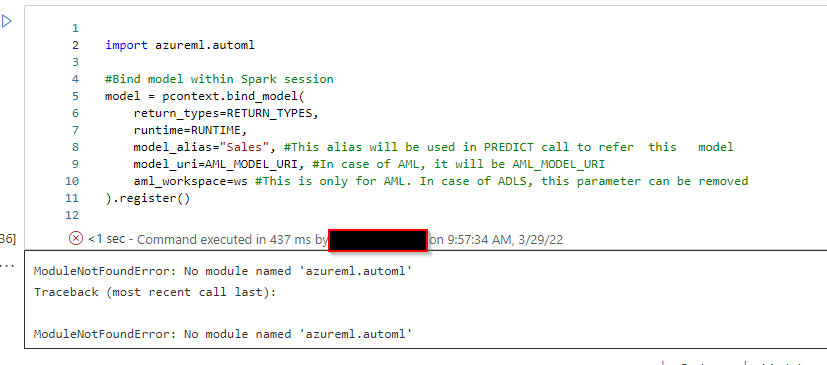
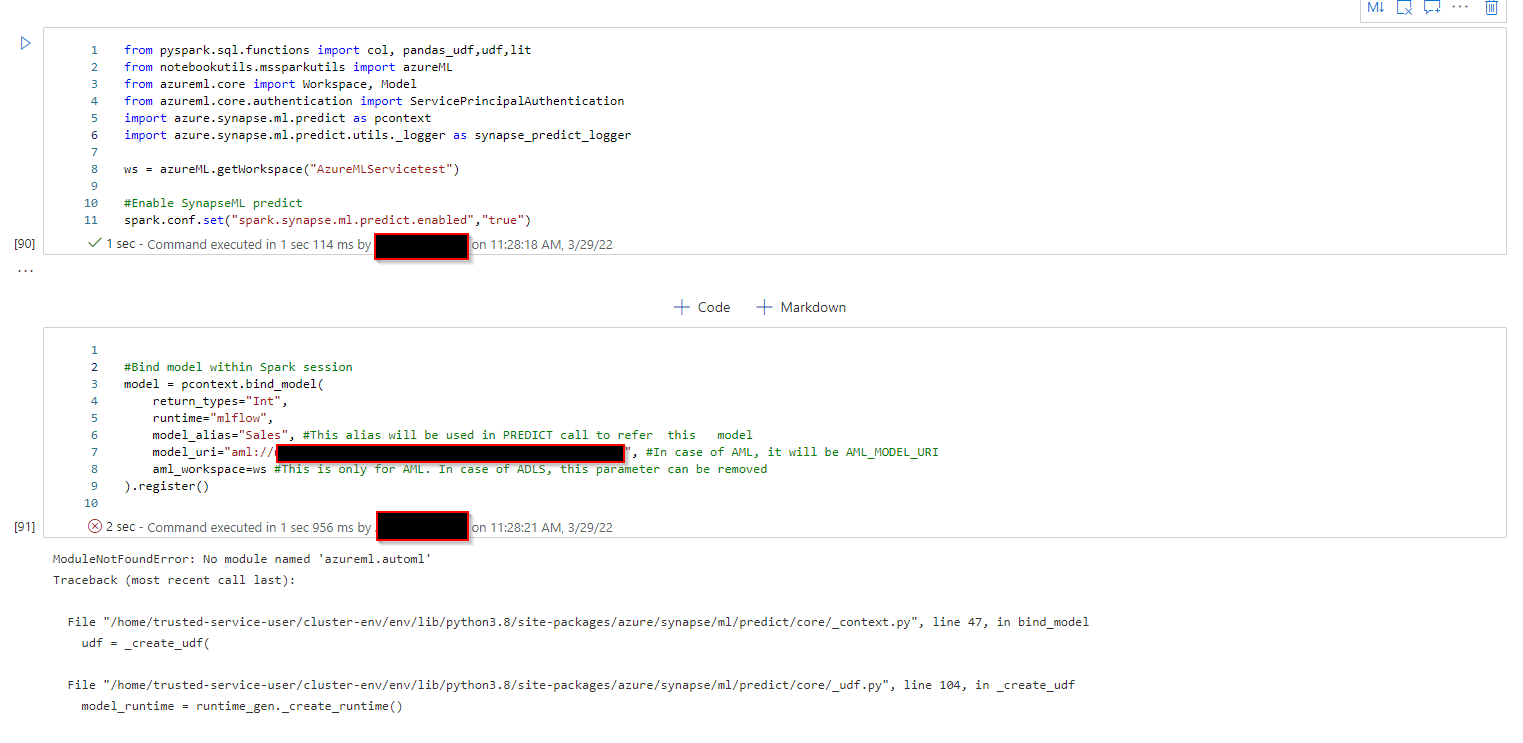
I get the following error with Apache Spark version 3.1 : ModuleNotFoundError: No module named 'azureml.automl'
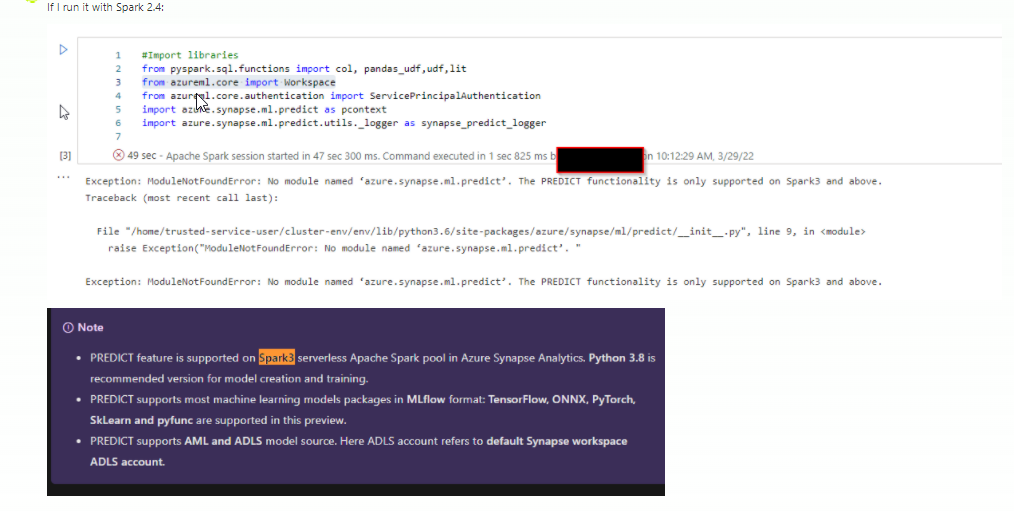
with version 2.4
I solved it. In my case it works best like this:

Hello @Anonymous ,
Glad to know that your issue has resolved. And thanks for sharing the solution, which might be beneficial to other community members reading this thread.
Hello @Anonymous ,
Thanks for the question and using MS Q&A platform.
If you are using import azureml.automl in Apache spark 3.1 runtime, you will experience the error message stating No module named 'azureml.automl'.
As mentioned in the official document could you please try using
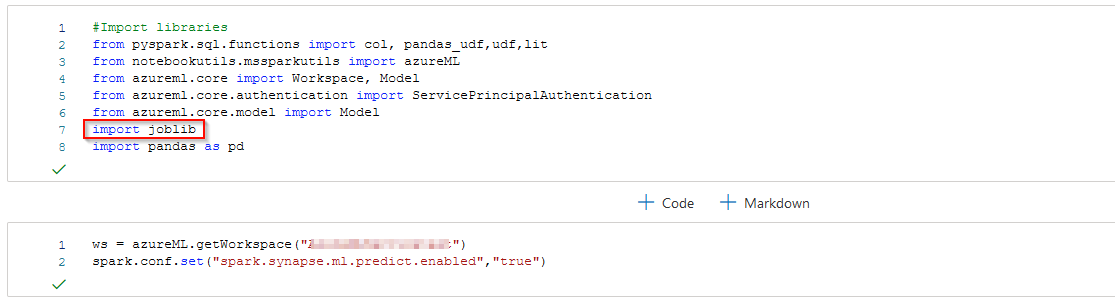
from notebookutils.mssparkutils import azureMLand it will work as excepted.
Here is the sample notebook for Score machine learning models with PREDICT in serverless Apache Spark pools
#!/usr/bin/env python
# coding: utf-8
# ## Azure_Synapse_ML_predict
# In[Cell-1]:
from notebookutils.mssparkutils import azureML
# In[Cell-2]:
ws = azureML.getWorkspace("AzureMLService")
# In[Cell-3]:
from azureml.core import Workspace, Model
model = Model(ws, id="linear_regression:1")
model.download('./')
# In[Cell-4]:
from pyspark.sql.functions import col, pandas_udf,udf,lit
from notebookutils.mssparkutils import azureML
from azureml.core import Workspace, Model
from azureml.core.authentication import ServicePrincipalAuthentication
import azure.synapse.ml.predict as pcontext
import azure.synapse.ml.predict.utils._logger as synapse_predict_logger
spark.conf.set("spark.synapse.ml.predict.enabled","true")
# In[Cell-5]:
AML_MODEL_URI_SKLEARN= "aml://linear_regression:1"
# In[Cell-6]:
model = pcontext.bind_model(
return_types="Array<float>",
runtime="mlflow",
model_alias="linear_regression:1",
model_uri=AML_MODEL_URI_SKLEARN,
aml_workspace=ws
).register()
# In[Cell-7]:
DATA_FILE = "abfss://******@cheprasynapse.dfs.core.windows.net/AML/LengthOfStay_cooked_small.csv"
df = spark.read .format("csv") .option("header", "true") .csv(DATA_FILE,
inferSchema=True)
df.createOrReplaceTempView('data')
df.show(10)
# In[Cell-8]:
#Call PREDICT using Spark SQL API
predictions = spark.sql(
"""
SELECT PREDICT('linear_regression:1',
hematocrit,neutrophils,sodium,glucose,bloodureanitro,creatinine,bmi,pulse,respiration)
AS predict FROM data
"""
).show()
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Same error
Hello @Anonymous ,
Could you please share the Apache Spark pool runtime details?
Where can I find them?

Hello @Anonymous ,
Yes, you are using the Apache Spark 3.1 runtime.
As per the repro from my end, the above code which you have shared works as excepted and I don't see any error message which you are experiencing.
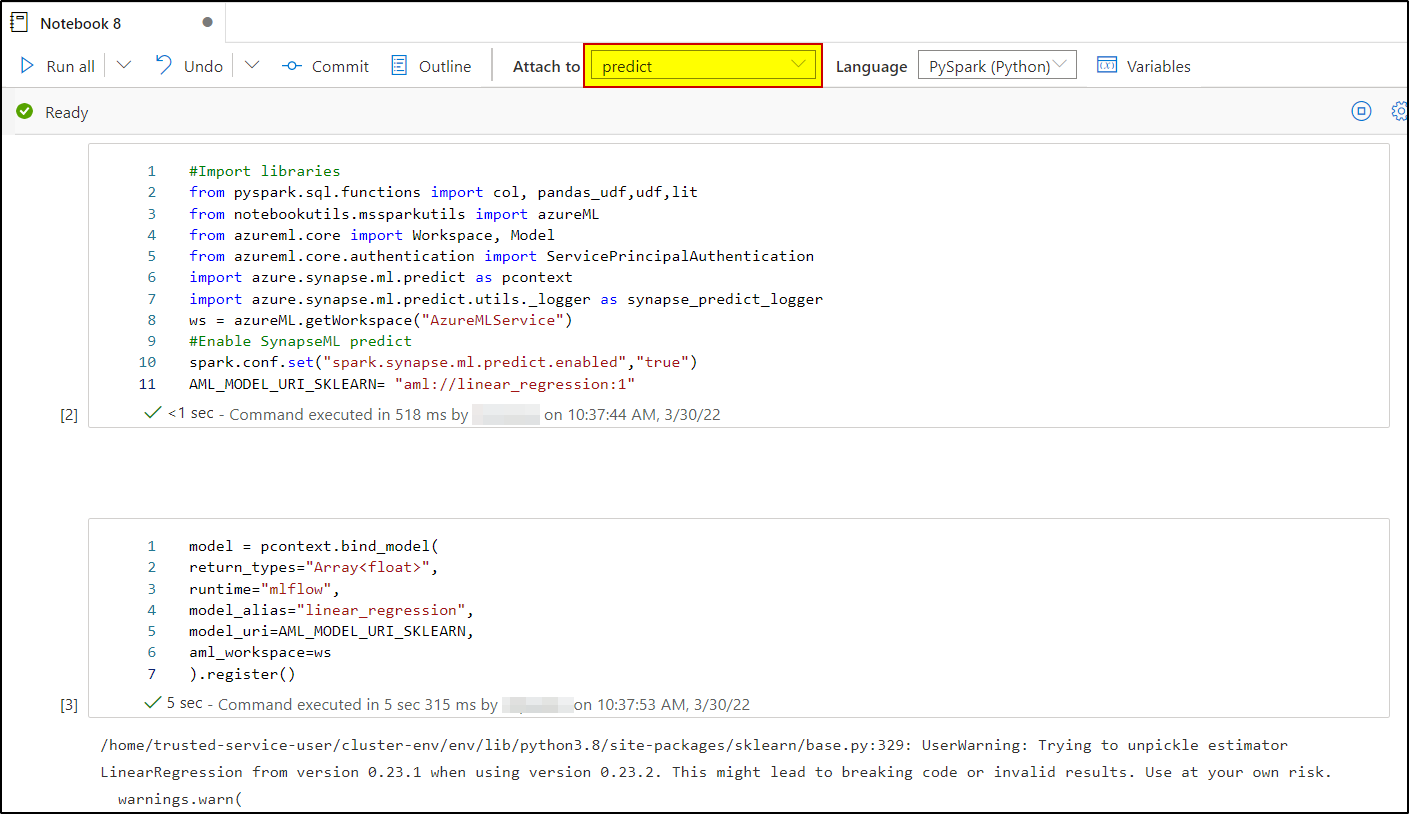
I had even tested the same code on the newly created Apache spark 3.1 runtime and it works as expected.
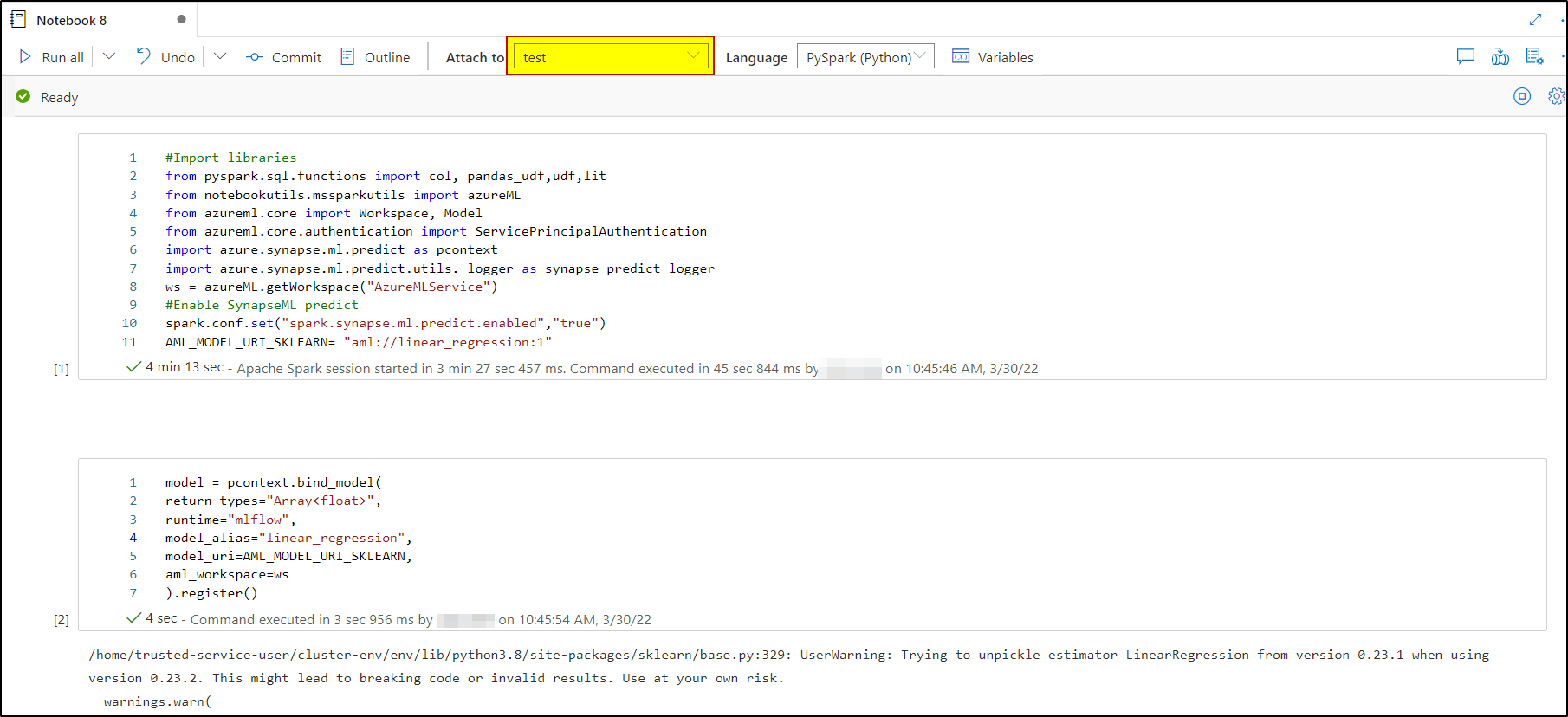
I would request you to create a new cluster and see if you are able to run the above code.
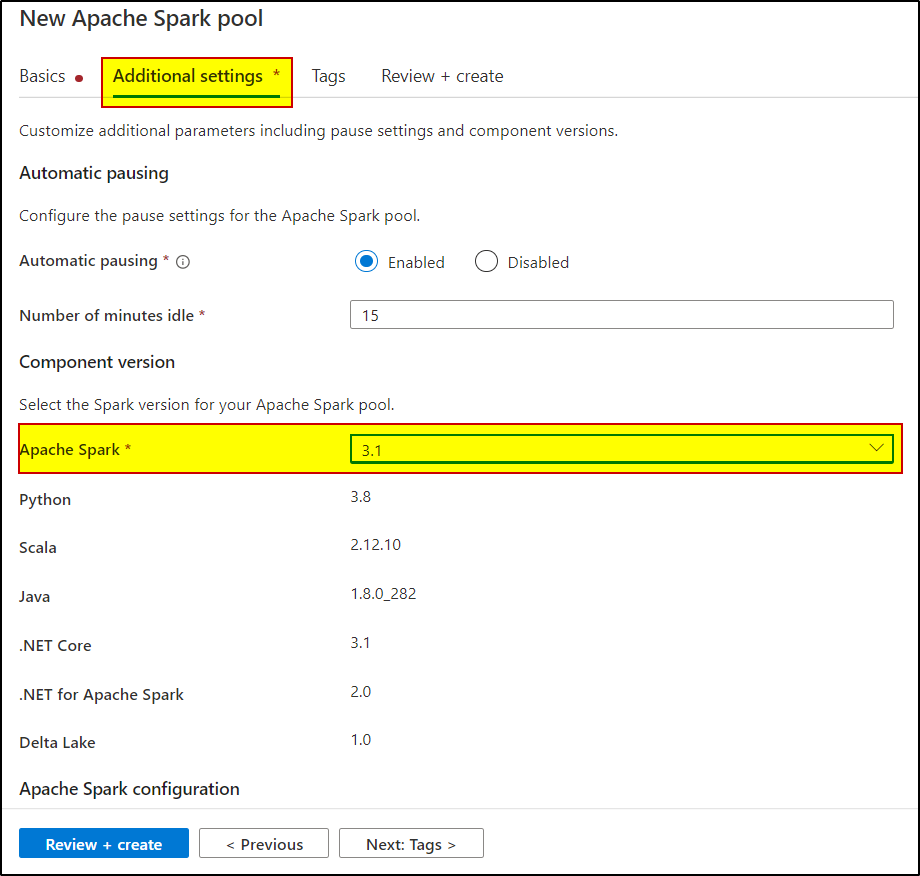
Hope this will help. Please let us know if any further queries.
New Spark pool same settings as you. Still this error.
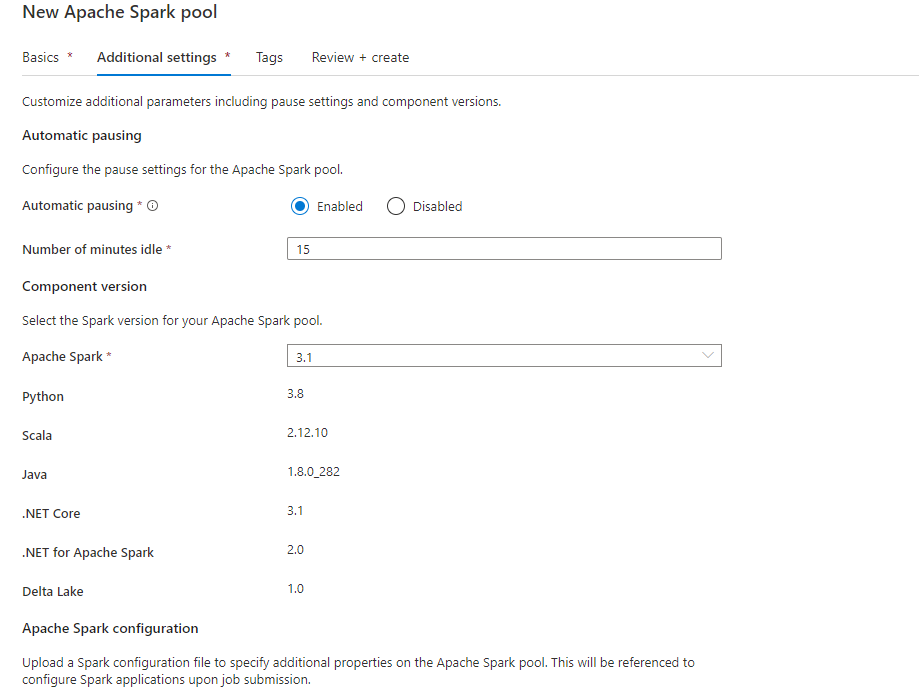
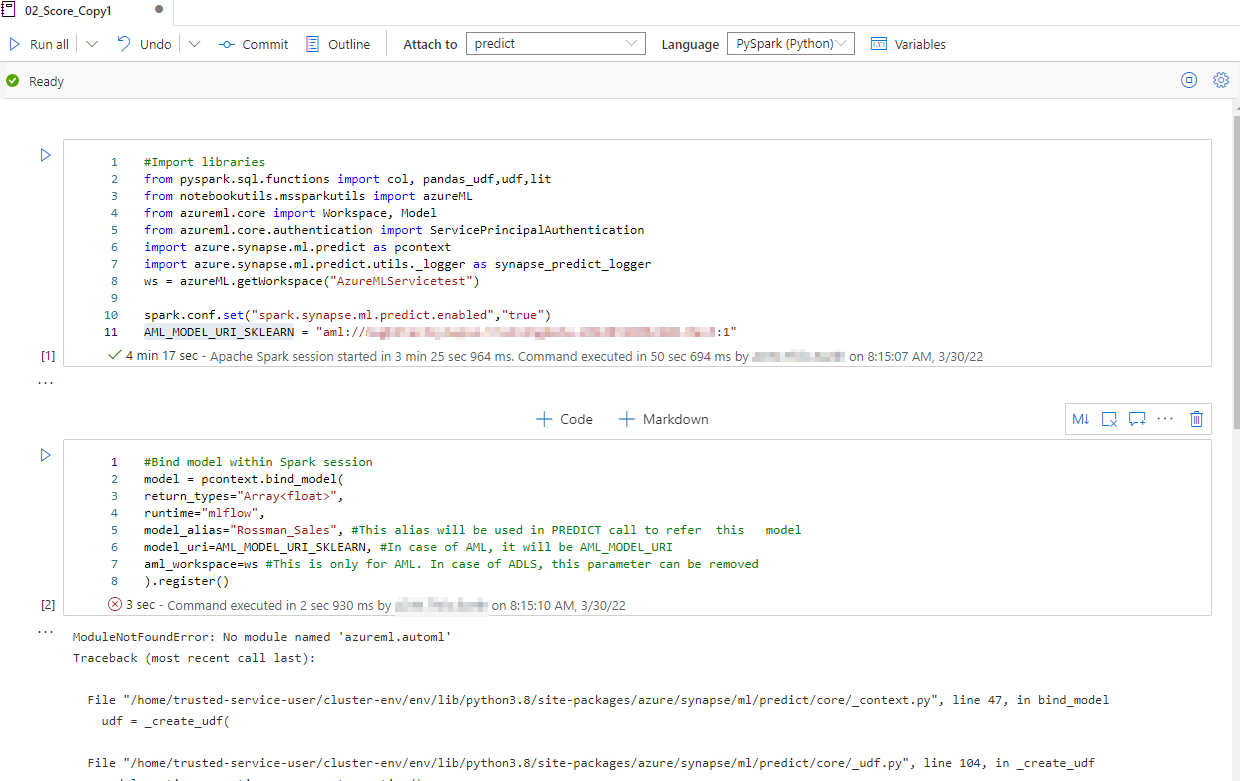
Maybe my Model is corrupt ?
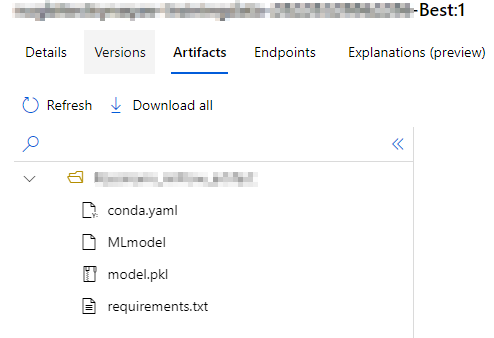
Conda.yaml - MLmodel - requirements.txt
https://pastebin.com/vf8pzE3C
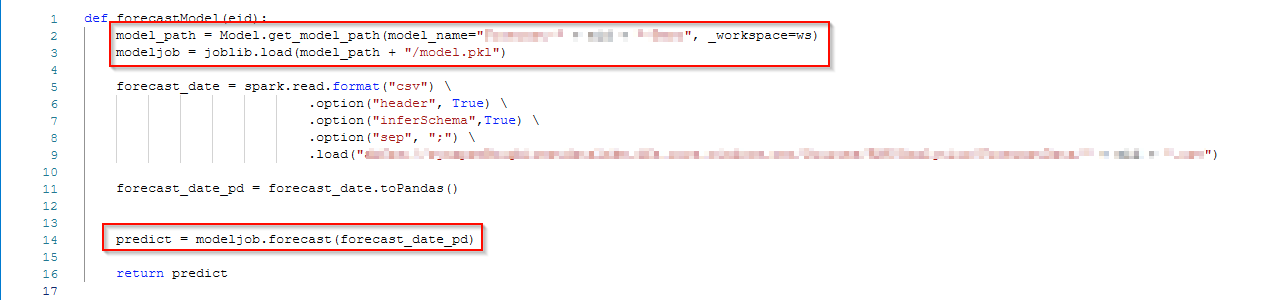
This is how I register the model after training:
